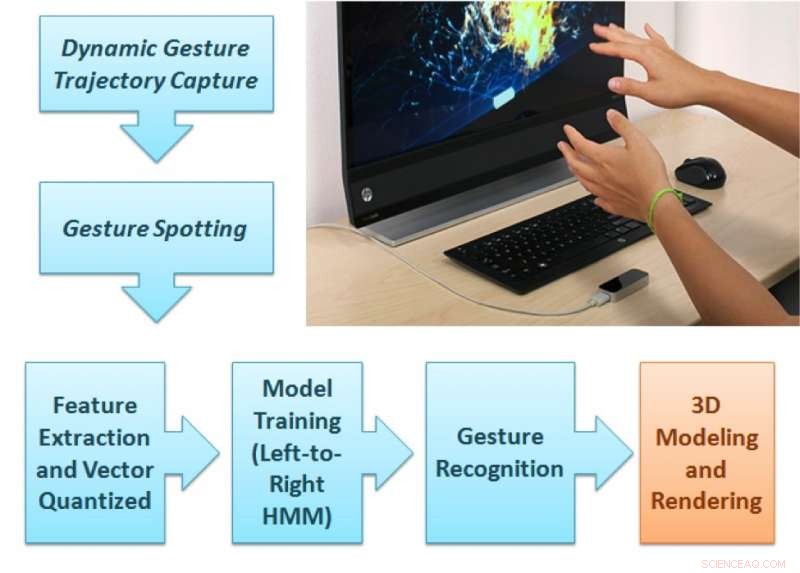
El marco de análisis de gestos propuesto. Crédito:Singla, Roy, y Dogra.
Investigadores de NIT Kurukshetra, IIT Roorkee e IIT Bhubaneswar han desarrollado un nuevo método basado en el controlador Leap Motion que podría mejorar la representación de formas 2-D y 3-D en dispositivos de visualización. Este nuevo método, descrito en un artículo publicado previamente en arXiv, rastrea los movimientos de los dedos mientras los usuarios realizan gestos naturales dentro del campo de visión de un sensor.
En años recientes, los investigadores han intentado diseñar innovadores, interfaces de usuario sin contacto. Dichas interfaces podrían permitir a los usuarios interactuar con dispositivos electrónicos incluso cuando sus manos están sucias o no son conductoras. al mismo tiempo que ayuda a las personas con discapacidades físicas parciales. Los estudios que exploran estas posibilidades se han visto mejorados por la aparición de sensores de bajo costo, como los que utiliza Leap Motion, Dispositivos Kinect y RealSense.
"Queríamos desarrollar una tecnología que pudiera brindar una experiencia de enseñanza atractiva a los estudiantes que aprenden arte con arcilla o incluso a los niños que están aprendiendo alfabetos básicos, "Dra. Debi Prosad Dogra, uno de los investigadores que llevó a cabo el estudio le dijo a TechXplore. "Entender el hecho de que los niños aprenden mejor de los estímulos visuales, Utilizamos un conocido dispositivo de captura de movimiento manual para brindar esta experiencia. Queríamos diseñar un marco que pudiera identificar los gestos del profesor y representar las imágenes en la pantalla. La configuración se puede utilizar para aplicaciones que requieran una representación visual guiada por gestos con las manos ".
El marco propuesto por el Dr. Dogra y sus colegas tiene dos partes distintas. En la primera parte, el usuario realiza un gesto natural entre los 36 tipos de gestos disponibles dentro del campo de visión del dispositivo Leap Motion.
"Las dos cámaras de infrarrojos del interior del sensor pueden grabar la secuencia de gestos, "Dijo el Dr. Dogra." El módulo de aprendizaje automático propuesto puede predecir la clase de gesto y una unidad de renderizado muestra la forma correspondiente en la pantalla ".
Las trayectorias de la mano del usuario se analizan para extraer características extendidas de Npen ++ en 3-D. Estas características, representar los movimientos de los dedos del usuario durante los gestos, se alimentan a un modelo de Markov oculto (HMM) unidireccional de izquierda a derecha para el entrenamiento. A continuación, el sistema realiza un mapeo uno a uno entre gestos y formas. Finalmente, las formas correspondientes a estos gestos se representan sobre la pantalla utilizando la interfaz MuPad.
"Desde la perspectiva de un desarrollador, el marco propuesto es un marco abierto típico, "Explicó el Dr. Dogra." Para agregar más gestos, un desarrollador solo necesita recopilar datos de secuencia de gestos de varios voluntarios y volver a entrenar el modelo de aprendizaje automático (ML) para nuevas clases. Este modelo ML puede aprender una representación generalizada ".
Como parte de su estudio, los investigadores crearon un conjunto de datos de 5400 muestras registradas por 10 voluntarios. Su conjunto de datos contiene 18 formas geométricas y 18 no geométricas, incluyendo círculo, rectángulo, flor, cono, esfera, y muchos más.
"La selección de funciones es una de las partes esenciales de una aplicación típica de aprendizaje automático, "Dijo el Dr. Dogra." En nuestro trabajo, hemos ampliado las funciones 2-D Npen ++ existentes en 3-D. Se ha demostrado que las funciones ampliadas mejoran significativamente el rendimiento. Las funciones 3-D Npen ++ también se pueden utilizar para otros tipos de señales, como la detección de la postura corporal, reconocimiento de actividad, etc. "
El Dr. Dogra y sus colegas evaluaron su método con una validación cruzada de cinco veces y encontraron que alcanzó una precisión del 92,87 por ciento. Sus características 3-D extendidas superaron a las características 3-D existentes para la representación y clasificación de formas. En el futuro, El método ideado por los investigadores podría ayudar al desarrollo de aplicaciones útiles de interacción humano-computadora (HCI) para dispositivos de visualización inteligentes.
"Nuestro enfoque del reconocimiento de gestos es bastante general, "El Dr. Dogra agregó." Vemos esta tecnología como una herramienta para la comunicación de personas sordas y discapacitadas. Ahora queremos emplear el sistema para comprender los gestos y convertirlos en formatos o formas escritos, para ayudar a las personas en las conversaciones de la vida diaria. Con la llegada de modelos avanzados de aprendizaje automático como las redes neuronales recurrentes (RNN) y la memoria a corto plazo a largo plazo (LSTM), también hay amplios alcances en la clasificación de señales temporales ".
© 2018 Science X Network














