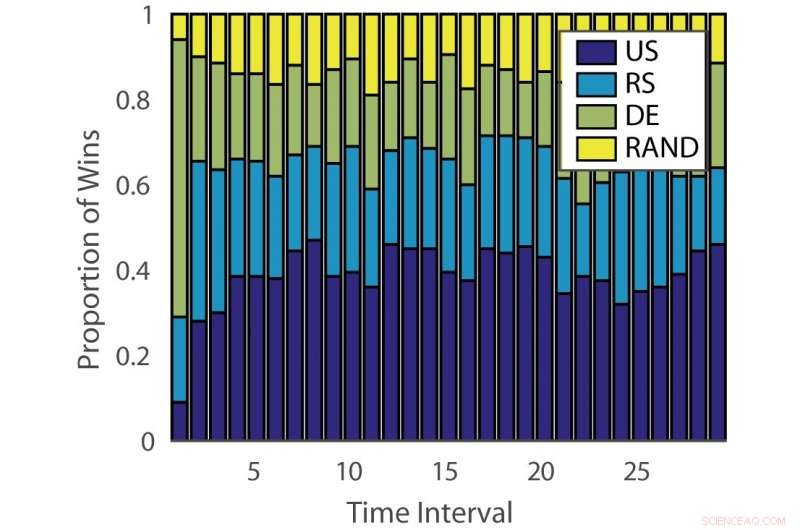
Proporción de victorias:“ILPD”. Crédito:Pang et al.
Investigadores de la Universidad de Edimburgo, University College London (UCL) y el Instituto de Ciencia y Tecnología de Nara han desarrollado un nuevo enfoque de aprendizaje activo conjunto basado en un bandido de múltiples brazos no estacionario y un algoritmo de asesoramiento experto. Su método, presentado en un artículo publicado previamente en arXiv, podría reducir el tiempo y el esfuerzo invertidos en la anotación manual de datos.
"El aprendizaje automático supervisado convencional consume muchos datos, y los datos etiquetados pueden ser un cuello de botella cuando la anotación de datos es costosa, "Timothy Hospedales, uno de los investigadores que llevó a cabo el estudio le dijo a Tech Xplore. "El aprendizaje activo respalda el aprendizaje supervisado al predecir los puntos de datos más informativos para anotar, de modo que se puedan entrenar buenos modelos con un presupuesto de anotaciones reducido".
El aprendizaje activo es un área particular del aprendizaje automático en la que un algoritmo de aprendizaje puede elegir activamente los datos de los que quiere aprender. Por lo general, esto da como resultado un mejor rendimiento, con conjuntos de datos de entrenamiento significativamente más pequeños.
Los investigadores han desarrollado una variedad de algoritmos de aprendizaje activo que podrían reducir los costos de anotación, pero hasta ahora, ninguna de estas soluciones ha demostrado ser eficaz para todos los problemas. Por lo tanto, otros estudios han utilizado algoritmos de bandidos para identificar el mejor algoritmo de aprendizaje activo para un conjunto de datos dado.
"El término 'bandido' se refiere a una máquina tragamonedas de bandidos con varios brazos, que es una abstracción matemática conveniente para problemas de exploración / explotación, "Hospedales explicó." Un algoritmo de bandidos encuentra un buen equilibrio entre el esfuerzo invertido en explorar todas las máquinas tragamonedas para descubrir cuál está pagando más, con el esfuerzo invertido en explotar la mejor máquina tragamonedas encontrada hasta ahora ".
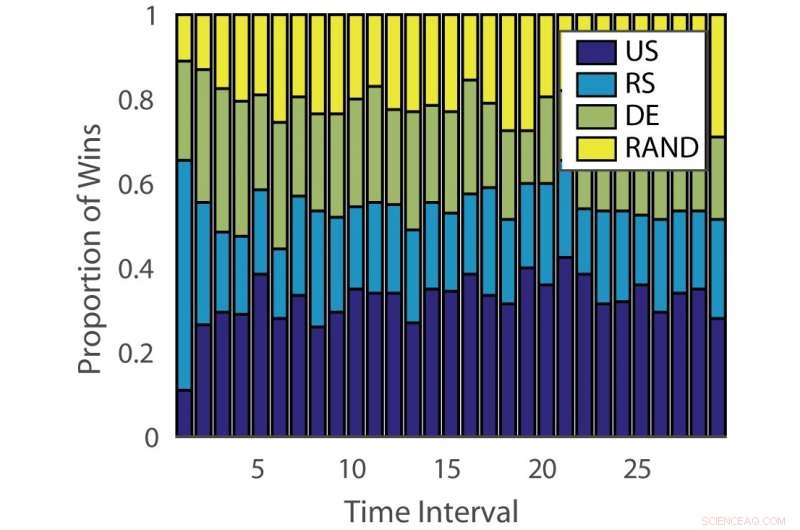
Proporción de victorias:“alemán”. Crédito:Pang et al.
La eficacia de los algoritmos de aprendizaje activo varía según los problemas y con el tiempo en las diferentes etapas del aprendizaje. Esta observación es análoga a jugar máquinas tragamonedas, donde la probabilidad de pago cambia con el tiempo.
"El objetivo de nuestro estudio fue desarrollar un nuevo algoritmo de bandidos que mejore el rendimiento teniendo en cuenta este aspecto del problema de aprendizaje activo, "Dijo Hospedales.
Para abordar esta limitación, los investigadores propusieron un aprendiz activo de conjunto dinámico (DEAL) basado en un bandido no estacionario. Este alumno genera una estimación de la eficacia de cada algoritmo de aprendizaje activo en línea, según la recompensa (precisión ponderada por importancia) obtenida después de cada anotación de datos.
"Para ello, utiliza la preferencia expresada por ese punto por cada algoritmo de aprendizaje activo, "Kunkun Pang, otro investigador que realizó el estudio, le dijo a Tech Xplore. "Para abordar el problema de la eficacia cambiante de los estudiantes activos a lo largo del tiempo, periódicamente reiniciamos el algoritmo de aprendizaje para actualizar su preferencia de alumno activo. Con esta capacidad, si el algoritmo de aprendizaje activo más eficaz cambia entre las primeras y últimas etapas del aprendizaje, podemos adaptarnos rápidamente a este cambio ".
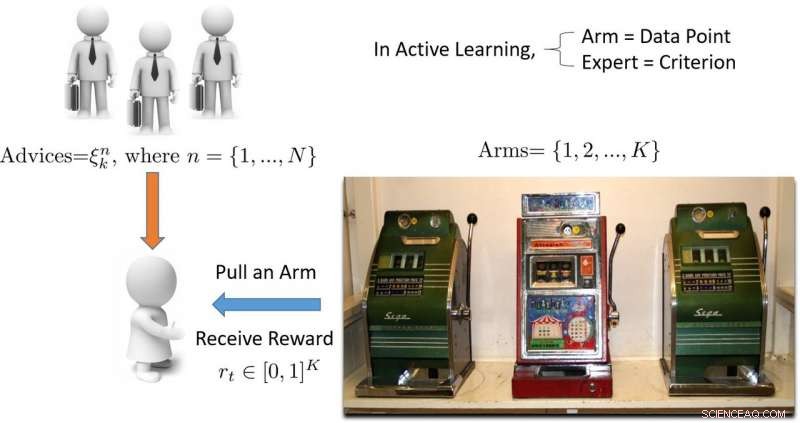
Ilustración de un enfoque de aprendizaje activo basado en bandidos de múltiples brazos. Crédito:Pang et al.
Los investigadores probaron su enfoque en 13 conjuntos de datos populares, logrando resultados muy alentadores. Su algoritmo DEAL tiene una garantía de rendimiento matemático, lo que significa que existe un alto grado de confianza en lo bien que funcionará.
"La garantía relaciona el rendimiento de nuestro algoritmo, que es el de un oráculo ideal que siempre conoce la elección correcta para el alumno activo, Hospedales explicó. "Proporciona un límite en la brecha de rendimiento entre el algoritmo del mejor de los casos y el nuestro".
La evaluación empírica realizada por Hospedales y sus colegas confirmó que su algoritmo DEAL mejora el rendimiento del aprendizaje activo en un conjunto de puntos de referencia. Lo hace identificando continuamente el algoritmo de aprendizaje activo más eficaz para diferentes tareas y en diferentes etapas del entrenamiento.
"Hoy dia, mientras que el aprendizaje activo es atractivo, su impacto en las prácticas de aprendizaje automático es limitado debido a la molestia de hacer coincidir los algoritmos con los problemas y las etapas del aprendizaje, Hospedales dijo. “DEAL elimina esta dificultad y proporciona un enfoque para abordar muchos problemas y todas las etapas del aprendizaje. Al hacer que el aprendizaje activo sea más fácil de usar, esperamos que pueda tener un mayor impacto en la reducción del costo de las anotaciones en la práctica del aprendizaje automático ".
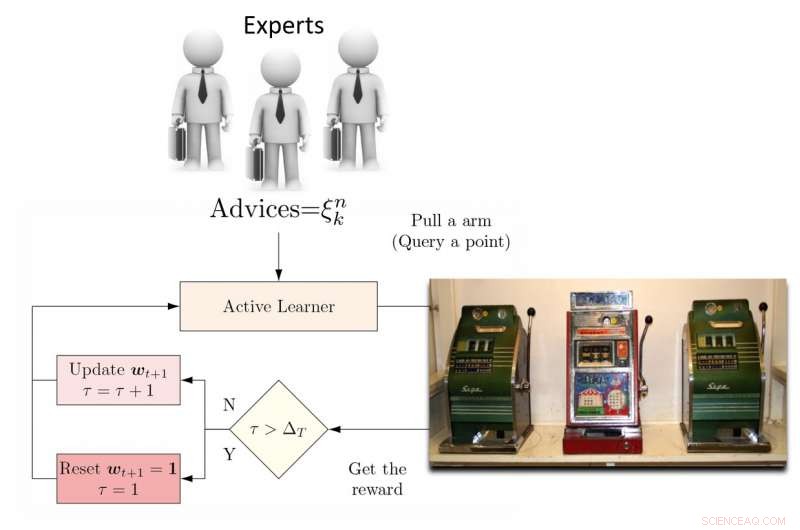
Ilustración del algoritmo DEAL REXP4. Crédito:Pang et al.
A pesar de los resultados muy prometedores, la técnica ideada por los investigadores todavía tiene una limitación significativa. DEAL hace todo el aprendizaje dentro de un solo problema y esto da como resultado un 'arranque en frío, ', lo que significa que el algoritmo aborda todos los problemas nuevos con una pizarra en blanco.
"En el trabajo en curso, estamos aprendiendo a hacer anotaciones en muchos problemas diferentes y eventualmente transferir este conocimiento a un nuevo problema, para realizar una anotación efectiva de inmediato sin requisitos de calentamiento, ", Dijo Pang." Nuestro trabajo preliminar sobre este tema se ha publicado y también ganó el premio al mejor artículo en el taller AutoML de ICML 2018 ".
© 2018 Science X Network














