Representación de gráfico de flujo semántico producido automáticamente a partir de un análisis de datos de artritis reumatoide. Crédito:IBM
Hemos visto un progreso reciente significativo en el análisis de patrones y la inteligencia de la máquina aplicada a las imágenes, señales de audio y video, y texto en lenguaje natural, pero no tanto aplicado a otro artefacto producido por personas:el código fuente de un programa de computadora. En un artículo que se presentará en el FEED Workshop en KDD 2018, mostramos un sistema que avanza hacia el análisis semántico de código. Al hacerlo, proporcionamos la base para que las máquinas razonen verdaderamente sobre el código del programa y aprendan de él.
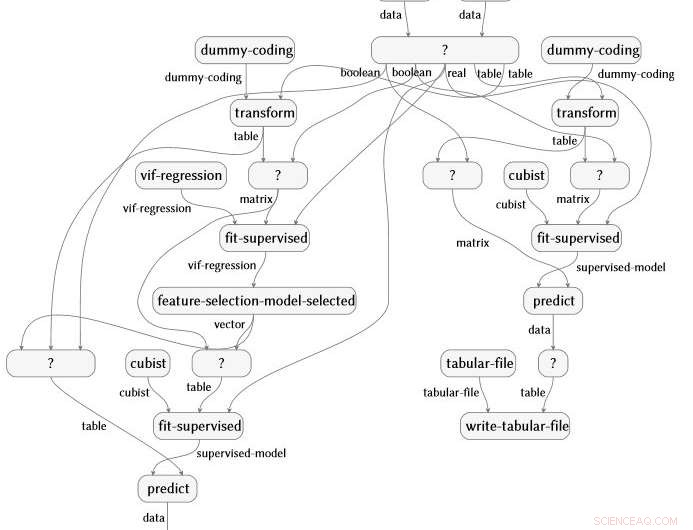
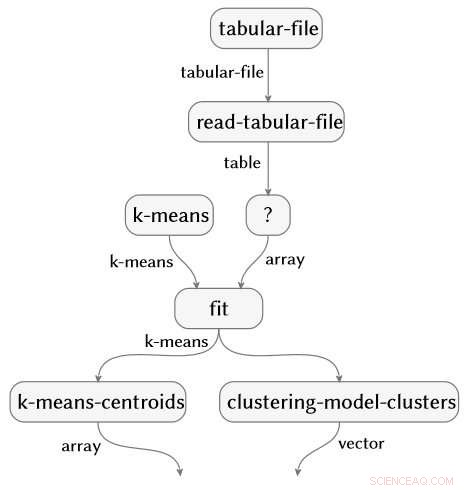
La obra, también recientemente demostrado en IJCAI 2018, está concebido y dirigido por Evan Patterson, miembro de IBM Science for Social Good, y se centra específicamente en el software de ciencia de datos. Los programas de ciencia de datos son un tipo especial de código de computadora, a menudo bastante corto, pero lleno de contenido semánticamente rico que especifica una secuencia de transformación de datos, análisis, modelado, y operaciones de interpretación. Nuestra técnica ejecuta un análisis de datos (imagine una secuencia de comandos R o Python) y captura todas las funciones que se llaman en el análisis. Luego conecta esas funciones a una ontología de ciencia de datos que hemos creado, realiza varios pasos de simplificación, y produce una representación de diagrama de flujo semántico del programa. Como ejemplo, el siguiente gráfico de flujo se genera automáticamente a partir de un análisis de los datos de la artritis reumatoide.
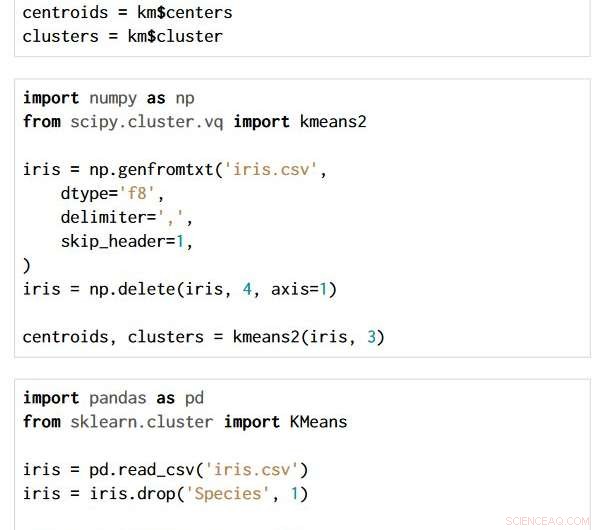
La técnica es aplicable en todas las opciones de paquetes y lenguajes de programación. Los tres fragmentos de código a continuación están escritos en R, Python con los paquetes NumPy y SciPy, y Python con los paquetes Pandas y Scikit-learn. Todos producen exactamente el mismo diagrama de flujo semántico.
Crédito:IBM
Crédito:IBM
Podemos pensar en el gráfico de flujo semántico que extraemos como un único punto de datos, como una imagen o un párrafo de texto, en el que realizar más tareas de nivel superior. Con la representación que hemos desarrollado, podemos habilitar varias funcionalidades útiles para los científicos de datos en práctica, incluyendo búsqueda inteligente y autocompletado de análisis, recomendación de análisis similares o complementarios, visualización del espacio de todos los análisis realizados sobre un problema o conjunto de datos en particular, traducción o transferencia de estilo, e incluso generación de máquinas de análisis de datos novedosos (es decir, creatividad computacional), todo basado en la comprensión verdaderamente semántica de lo que hace el código.
La ontología de ciencia de datos está escrita en un nuevo lenguaje de ontología que hemos desarrollado llamado Ontología monoidal y lenguaje de computación (Monocl). Esta línea de trabajo se inició en 2016 en asociación con el Proyecto de curación acelerada de la esclerosis múltiple.
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.