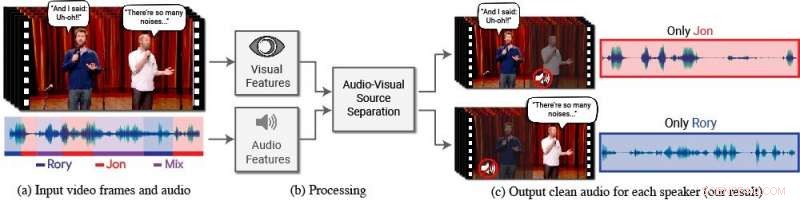
Un nuevo modelo aísla y mejora el discurso de los oradores deseados en un video. (a) La entrada es un video (cuadros + pista de audio) con una o más personas hablando, donde el discurso de interés es interferido por otros hablantes y / o ruido de fondo. (b) Tanto las características de audio como las visuales se extraen y se introducen en un modelo conjunto de separación de voz audiovisual. (c) La salida es una descomposición de la pista de audio de entrada en pistas de voz limpias, uno por cada persona detectada en el video. El habla de personas específicas se mejora en los videos, mientras que el resto del sonido se suprime. El nuevo modelo se entrenó utilizando miles de horas de segmentos de video del nuevo conjunto de datos del equipo, AVSpeech, que se dará a conocer públicamente. Crédito:Autores / Imágenes fijas de Google Video:Cortesía del Equipo Coco / CONAN
Las personas tienen una habilidad natural para concentrarse en lo que dice una sola persona, incluso cuando hay conversaciones en competencia de fondo u otros sonidos que distraen. Por ejemplo, la gente a menudo puede distinguir lo que dice alguien en un restaurante lleno de gente, durante una fiesta ruidosa, o mientras ve debates televisados en los que varios expertos hablan entre sí. Hasta la fecha, ser capaz de imitar computacionalmente y con precisión esta habilidad humana natural para aislar el habla ha sido una tarea difícil.
"Las computadoras son cada vez mejores para comprender el habla, pero todavía tiene una dificultad significativa para entender el habla cuando varias personas hablan juntas o cuando hay mucho ruido, "dice Ariel Ephrat, un doctorado candidato en la Universidad Hebrea de Jerusalén-Israel y autor principal de la investigación. (Ephrat desarrolló el nuevo modelo mientras realizaba una pasantía en Google el verano de 2017). "Los humanos sabemos cómo entender el habla en tales condiciones de forma natural, pero queremos que las computadoras puedan hacerlo tan bien como nosotros, tal vez incluso mejor ".
Para tal fin, Ephrat y sus colegas de Google han desarrollado un modelo audiovisual novedoso para aislar y mejorar el habla de los oradores deseados en un video. El modelo basado en la red profunda del equipo incorpora señales visuales y auditivas para aislar y mejorar a cualquier orador en cualquier video, incluso en escenarios desafiantes del mundo real, como videoconferencias, donde varios participantes a menudo hablan a la vez, y bares ruidosos, que podría contener una variedad de ruido de fondo, música, y conversaciones competitivas.
El equipo, que incluye Inbar Mosseri de Google, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, y Michael Rubinstein, presentará su trabajo en SIGGRAPH 2018, celebrada del 12 al 16 de agosto en Vancouver, Columbia Británica. La conferencia y exposición anual presenta a los principales profesionales del mundo, académica, y mentes creativas a la vanguardia de los gráficos por computadora y las técnicas interactivas.
En este trabajo, los investigadores no solo se centraron en las señales auditivas para separar el habla, sino también en las señales visuales en el video, es decir, los movimientos de los labios del sujeto y potencialmente otros movimientos faciales que pueden contribuir a lo que está diciendo. Las características visuales obtenidas se utilizan para "enfocar" el audio en un solo sujeto que está hablando y para mejorar la calidad de la separación del habla.
Para entrenar su modelo audiovisual conjunto, Ephrat y sus colaboradores seleccionaron un nuevo conjunto de datos, "AVSpeech, "compuesto por miles de videos de YouTube y otros segmentos de videos en línea, como TED Talks, Videos de' cómo hacer, y conferencias de alta calidad. Desde AVSpeech, Los investigadores generaron un conjunto de capacitación de los llamados "cócteles sintéticos":mezclas de videos faciales con voz limpia y otras pistas de audio de voz con ruido de fondo. Para aislar el habla de estos videos, el usuario solo debe especificar el rostro de la persona en el video cuyo audio se va a destacar.
En múltiples ejemplos detallados en el documento, titulado "Buscando escuchar en el cóctel:un modelo audiovisual independiente del orador para la separación del habla, "el nuevo método obtuvo resultados superiores en comparación con los métodos de solo audio existentes en mezclas de voz pura, y mejoras significativas en la entrega de audio claro a partir de mezclas que contienen voz superpuesta y ruido de fondo en escenarios del mundo real. Si bien el enfoque del trabajo es la separación y mejora del habla, El método novedoso del equipo también podría aplicarse al reconocimiento automático de voz (ASR) y la transcripción de video, es decir, capacidades de subtítulos en la transmisión de videos y TV. En una demostración, el nuevo modelo audiovisual conjunto produjo subtítulos más precisos en escenarios en los que participaron dos o más oradores.
Sorprendido al principio por lo bien que funcionaba su método, los investigadores están entusiasmados con su potencial futuro.
"No habíamos visto antes la separación de voz 'en estado salvaje' con tal calidad. Por eso vemos un futuro emocionante para esta tecnología, ", señala Ephrat." Se necesita más trabajo antes de que esta tecnología llegue a manos de los consumidores, pero con los prometedores resultados preliminares que hemos mostrado, Ciertamente, podemos verlo admitiendo una variedad de aplicaciones en el futuro, como subtítulos de video, videoconferencia, e incluso mejores audífonos si dichos dispositivos pudieran combinarse con cámaras ".
Actualmente, los investigadores están explorando oportunidades para incorporarlo en varios productos de Google.