Al principio, de alguna manera, los bloques de construcción genéticos básicos se tradujeron en proteínas para dar lugar a la vida compleja tal como la conocemos. Crédito:Christ-claude Mowandza-ndinga
Todos los seres vivos utilizan el código genético para "traducir" la información genética basada en el ADN en proteínas, que son las principales moléculas de trabajo en las células. Precisamente cómo surgió el complejo proceso de traducción en las primeras etapas de la vida en la Tierra hace más de cuatro mil millones de años ha sido un misterio durante mucho tiempo, pero dos biólogos teóricos han logrado ahora un avance significativo en la resolución de este misterio.
Charles Carter, Doctor., profesor de bioquímica y biofísica en la Facultad de Medicina de la UNC, y Peter Wills, Doctor., profesor asociado de bioquímica en la Universidad de Auckland, utilizó métodos estadísticos avanzados para analizar cómo las moléculas de traducción modernas encajan para realizar su trabajo:enlazar secuencias cortas de información genética con los bloques de construcción de proteínas que codifican.
El análisis de los científicos, publicado en Investigación de ácidos nucleicos , revela reglas previamente ocultas por las cuales las moléculas de traducción clave interactúan en la actualidad. La investigación sugiere cómo los ancestros mucho más simples de estas moléculas comenzaron a trabajar juntos en los albores de la vida.
"Creo que hemos aclarado las reglas subyacentes y la historia evolutiva de la codificación genética, Carter dijo. "Esto había estado sin resolver durante 60 años".
Testamentos agregados, "Los pares de patrones moleculares que hemos identificado pueden ser los primeros que la naturaleza haya utilizado para transferir información de una forma a otra en los organismos vivos".
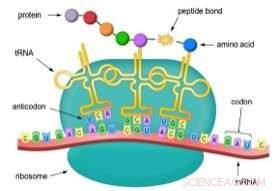
Los descubrimientos se centran en una molécula en forma de hoja de trébol llamada ARN de transferencia (ARNt), un actor clave en la traducción. Un ARNt está diseñado para transportar un bloque de construcción de proteínas simple, conocido como un aminoácido, en la línea de ensamblaje de producción de proteínas dentro de pequeñas fábricas moleculares llamadas ribosomas. Cuando una copia o "transcripción" de un gen llamado ARN mensajero (ARNm) emerge del núcleo celular y entra en un ribosoma, está unido a los ARNt que transportan sus cargas de aminoácidos.
El ARNm es esencialmente una serie de "letras" genéticas que explican las instrucciones para la producción de proteínas, y cada ARNt reconoce una secuencia específica de tres letras en el ARNm. Esta secuencia se denomina "codón". A medida que el ARNt se une al codón, el ribosoma une su aminoácido al aminoácido que le precedió, alargando el péptido en crecimiento. Cuando esté completo, la cadena de aminoácidos se libera como una proteína recién nacida.
Las proteínas en los seres humanos y la mayoría de las otras formas de vida están hechas de 20 aminoácidos diferentes. Por lo tanto, hay 20 tipos distintos de moléculas de ARNt, cada uno capaz de unirse a un aminoácido particular. Junto con estos 20 ARNt hay 20 enzimas auxiliares coincidentes conocidas como sintetasas (aminoacil-ARNt sintetasas), cuyo trabajo es cargar los ARNt de su pareja con el aminoácido correcto.
"Puede pensar en estas 20 sintetasas y 20 tRNA colectivamente como una computadora molecular que la evolución ha diseñado para hacer que suceda la traducción de genes a proteínas, "Dijo Carter.
Todos los seres vivos utilizan el código genético para 'traducir' la información genética basada en el ADN en proteínas, que son las principales moléculas de trabajo en las células. Precisamente cómo surgió el complejo proceso de traducción en las primeras etapas de la vida en la Tierra hace más de cuatro mil millones de años ha sido un misterio durante mucho tiempo, pero dos biólogos teóricos han logrado ahora un avance significativo en la resolución de este misterio. Crédito:Carter y Wills
Los biólogos llevan mucho tiempo intrigados por esta computadora molecular y el enigma de cómo se originó hace miles de millones de años. En años recientes, Carter y Wills han hecho de este rompecabezas su principal foco de investigación. Han mostrado, por ejemplo, cómo las 20 sintetasas, que existen en dos clases estructuralmente distintas de 10 sintetasas, probablemente surgió de dos más simples, enzimas ancestrales.
Existe una división de clases similar para los aminoácidos, y Carter y Wills han argumentado que la misma división de clases debe aplicarse a los tRNA. En otras palabras, proponen que en los albores de la vida en la Tierra, organismos contenían solo dos tipos de ARNt, que habría funcionado con dos tipos de sintetasas para realizar la traducción de gen a proteína utilizando solo dos tipos diferentes de aminoácidos.
La idea es que en el transcurso de eones este sistema se volvió cada vez más específico, como cada uno de los ARNt originales, sintetasas, y los aminoácidos fueron aumentados o refinados por nuevas variantes hasta que hubo distintas clases de 10 en lugar de cada uno de los dos tRNA originales, sintetasas, y aminoácidos.
En su estudio más reciente, Carter y Wills examinaron los ARNt modernos en busca de evidencia de esta antigua dualidad. Para ello analizaron la parte superior de la molécula de ARNt, conocido como el vástago aceptor, donde se unen las sintetasas asociadas. Su análisis mostró que solo tres bases de ARN, o cartas, en la parte superior del tallo aceptor hay un código oculto que especifica reglas que dividen los ARNt en dos clases, que corresponden exactamente a las dos clases de sintetasas ". Son simplemente las combinaciones de estas tres bases las que determinan qué clase de sintetasa se une a cada ARNt , "Dijo Carter.
El estudio encontró por casualidad evidencia para otra propuesta sobre los ARNt. Cada ARNt moderno tiene en su extremo inferior un "anticodón" que utiliza para reconocer y adherirse a un codón complementario en un ARNm. El anticodón está relativamente lejos del sitio de unión de la sintetasa, pero los científicos desde principios de la década de 1990 han especulado que los ARNt alguna vez fueron mucho más pequeños, combinando las regiones de unión de anticodón y sintetasa en una. El análisis de Wills y Carter muestra que las reglas asociadas con una de las tres bases determinantes de clase, la base número 2 en la molécula de ARNt general, implican efectivamente un rastro del anticodón en un antiguo, versión truncada de tRNA.
"Esta es una confirmación completamente inesperada de una hipótesis que ha existido durante casi 30 años, "Dijo Carter.
Estos hallazgos refuerzan el argumento de que el sistema de traducción original tenía solo dos ARNt primitivos, correspondiente a dos sintetasas y dos tipos de aminoácidos. A medida que este sistema evolucionó para reconocer e incorporar nuevos aminoácidos, Habrían surgido nuevas combinaciones de bases de ARNt en la región de unión de la sintetasa para mantenerse al día con la creciente complejidad, pero de una manera que dejara rastros detectables de la disposición original.
"Estas tres bases que definen clases en los ARNt contemporáneos son como un manuscrito medieval cuyos textos originales han sido borrados y reemplazados por textos más nuevos, "Dijo Carter.
Los hallazgos reducen las posibilidades de los orígenes de la codificación genética. Es más, reducen el ámbito de los experimentos futuros que los científicos podrían realizar para reconstruir las primeras versiones del sistema traslacional en el laboratorio, y tal vez incluso hacer que este sistema simple evolucione hacia uno más complejo, formas modernas del mismo sistema de traducción. Esto mostraría además cómo la vida evolucionó desde la más simple de las moléculas hasta convertirse en células y organismos complejos.