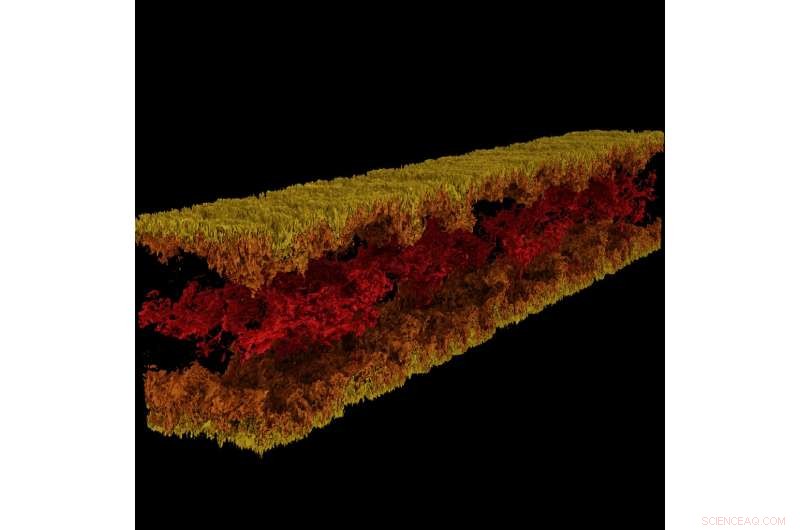
Visualización de flujo de canal turbulento producida con GraviT. Crédito:Visualización:Texas Advanced Computing Center. Datos:ICES, La Universidad de Texas en Austin.
Grande, La ciencia impactante requiere todo un ecosistema tecnológico para progresar. Esto incluye sistemas informáticos de vanguardia, almacenamiento de alta capacidad, redes de alta velocidad, poder, enfriamiento ... la lista sigue y sigue.
Críticamente, También requiere software de última generación:programas que funcionan en conjunto sin problemas para permitir que los científicos e ingenieros respondan preguntas difíciles, compartir sus soluciones, y realizar investigaciones con la máxima eficacia y el mínimo dolor.
Para nutrir este modo crítico de progreso científico, en 2012, NSF estableció el programa de infraestructura de software para la innovación sostenida (SI2), con el objetivo de transformar las innovaciones en investigación y educación en recursos de software sostenidos que son una parte integral de la ciberinfraestructura.
"El descubrimiento científico y la innovación avanzan a lo largo de caminos fundamentalmente nuevos abiertos por el desarrollo de software cada vez más sofisticado, ", escribió la National Science Foundation (NSF) en la solicitud del programa SI2." El software también es directamente responsable del aumento de la productividad científica y la mejora significativa de las capacidades de los investigadores ".
Con cinco premios SI2 actuales, y roles colaborativos en varios más, el Centro de Computación Avanzada de Texas (TACC) se encuentra entre los líderes nacionales en el desarrollo de software para computación científica. Los investigadores principales de TACC presentarán su trabajo del 30 de abril al 2 de mayo en la Reunión de investigadores principales de NSF SI2 2018 en Washington. CORRIENTE CONTINUA.
"Parte de la misión de TACC es mejorar la productividad de los investigadores que utilizan nuestros sistemas, "dijo Bill Barth, Director de informática de alto rendimiento de TACC y ex beneficiario de una subvención SI2. "El programa SI2 nos ha ayudado a hacer eso al respaldar los esfuerzos para desarrollar nuevas herramientas y ampliar las herramientas existentes con funciones adicionales de rendimiento y usabilidad".
Desde marcos para visualización a gran escala hasta herramientas de paralelización automática y más, El software desarrollado por TACC está cambiando la forma en que los investigadores computan en el futuro.
Herramienta de paralelización interactiva
El poder de las supercomputadoras radica principalmente en su capacidad para resolver ecuaciones matemáticas en paralelo. Toma un problema difícil dividirlo en sus partes constituyentes, resuelva cada parte individualmente y reúna las respuestas nuevamente:esto es computación paralela en su esencia. Sin embargo, la tarea de organizar el problema de uno para que pueda ser abordado por una supercomputadora no es fácil, incluso para científicos computacionales experimentados.
Ritu Arora, un científico investigador en TACC, ha estado trabajando para bajar el listón a la computación paralela mediante el desarrollo de una herramienta que puede convertir un código en serie, que solo puede usar un solo procesador a la vez, en un código paralelo que puede utilizar decenas a miles de procesadores. La herramienta analiza una aplicación en serie, solicita información adicional del usuario, aplica heurística incorporada, y genera una versión paralela de la aplicación serial de entrada.
Arora y sus colaboradores implementaron la versión actual de IPT en la nube para que los investigadores puedan usarla cómodamente a través de un navegador web. Los investigadores pueden generar versiones paralelas de su código de forma semiautomática y probar el código paralelo para determinar su precisión y rendimiento en los recursos TACC y XSEDE. incluyendo Stampede2, Lonestar5, y cometa.
"La magnitud del impacto social de IPT es una función directa de la importancia de HPC en STEM y dominios emergentes no tradicionales, y los grandes desafíos a los que se enfrentan los estudiantes y los expertos en el campo al escalar la curva de aprendizaje de la programación paralela, ", Dijo Arora." Además de reducir el tiempo de desarrollo y el tiempo de ejecución de las aplicaciones en plataformas HPC, IPT disminuirá el uso de energía y maximizará el rendimiento entregado por las plataformas HPC a través de su capacidad para generar código híbrido ".

GraviT permitió a los investigadores producir visualizaciones de trazado de rayos utilizando datos producidos por Enzo, un código de simulación diseñado para ricos, cálculos astrofísicos hidrodinámicos multifísicos. Crédito:Universidad de Texas en Austin
Como ejemplo de las capacidades de IPT, Arora apunta a un esfuerzo reciente para paralelizar una aplicación de dinámica molecular (MD). Al paralelizar la aplicación serial usando OpenMP a un alto nivel de abstracción, es decir, sin que el usuario conociera la sintaxis de bajo nivel de OpenMP, lograron un 88% de aceleración en el código.
También cuantificaron el impacto de IPT en términos de productividad del usuario midiendo la cantidad de líneas de código que un investigador tiene que escribir durante el proceso de paralelizar una aplicación manualmente en comparación con el uso de IPT.
"En nuestros casos de prueba, IPT mejoró la productividad del usuario en más del 90%, en comparación con escribir el código manualmente, y generó el código paralelo que está dentro del 10% del rendimiento del mejor código paralelo escrito a mano disponible para esas aplicaciones, ", dijo Arora." Estamos muy contentos con su éxito hasta ahora ".
TACC está ampliando IPT para admitir tipos adicionales de aplicaciones seriales, así como aplicaciones que exhiben patrones de comunicación y computación irregulares.
(Vea una demostración en video de IPT en la que TACC muestra el proceso de paralelizar una aplicación de dinámica molecular con el modelo de programación OpenMP).
GraviT
La visualización científica, el proceso de transformar datos sin procesar en imágenes interpretables, es un aspecto clave de la investigación. Sin embargo, it can be challenging when you're trying to visualize petabyte-scale datasets spread among many nodes of a computing cluster. Even more so when you're trying to use advanced visualizations methods like ray tracing—a technique for generating an image by tracing the path of light as pixels in an image plane and simulating the effects of its encounters with virtual objects.
To address this problem, Paul Navratil, director of visualization at TACC, has led an effort to create GraviT, a scalable, distributed-memory ray tracing framework and software library for applications that encompass data so large that it cannot reside in the memory of a single compute node. Collaborators on the project include Hank Childs (University of Oregon), Chuck Hansen (University of Utah), Matt Turk (National Center for Supercomputing Applications) and Allen Malony (ParaTools).
GraviT works across a variety of hardware platforms, including the Intel Xeon processors and NVIDIA GPUs. It can also function in heterogeneous computing environments, por ejemplo, hybrid CPU and GPU systems. GraviT has been successfully integrated into the GLuRay OpenGL-based ray tracing interface, the VisIt visualization toolkit, the VTK visualization toolkit, and the yt visualization framework.
"High-fidelity rendering techniques like ray tracing improve visual analysis by providing the same spatial cues of light and shadow that we see in the world around us, but these are challenging to use in distributed contexts, " said Navratil. "GraviT enables these techniques to be used efficiently across distributed computing resources, unlocking their potential for large scale analysis and to be used in situ, where data is not written to disk prior to analysis."
(The GraviT source code is available at the TACC GitHub site ).
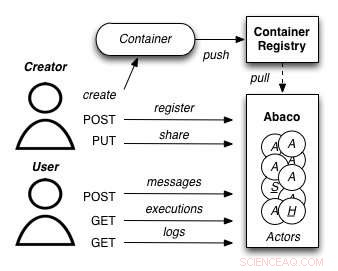
A diagram showing how the Abaco "Actor" model works. Credit:University of Texas at Austin
Abaco
The increased availability of data has enabled entirely new kinds of analyses to emerge, yielding answers to many important questions. Sin embargo, these analyses are complex and frequently require advanced computer science expertise to run correctly.
Joe Stubbs, who leads TACC's Cloud and Interactive Computing (CIC) group, is working on a project that simplifies how researchers create analysis tools that are reliable and scalable. The project, known as Abaco, adapts the "Actor" model, whereby software systems are designed as a collection of simple functions, which can then be provided as a cloud-based capability on high performance computing environments.
"Abaco significantly simplifies the way scientific software is developed and used, " said Stubbs. "Scientific software developers will find it much easier to design and implement a system. Más lejos, scientists and researchers that use software will be able to easily compose collections of actors with pre-determined functionality in order to get the computation and data they need."
The Abaco API (application programming interface) combines technologies and techniques from cloud computing, including Linux Containers and the "functions-as-a-service" paradigm, with the Actor model for concurrent computation. Investigators addressing grand challenge problems in synthetic biology, earthquake engineering and food safety are already using the tool to advance their work. Stubbs is working to extend Abaco's ability to do data federation and discoverability, so Abaco programs can be used to build federated datasets consisting of separate datasets from all over the internet.
"By reducing the barriers to developing and using such services, this project will boost the productivity of scientists and engineers working on the problems of today, and better prepare them to tackle the new problems of tomorrow, " Stubbs said.
Expanding volunteer computing
Volunteer computing uses donated computing time on consumer devices such as home computers and smartphones to conduct scientific investigations. Early successes from this approach include the discovery of the structure of an enzyme involved in reproduction of HIV by FoldIt participants; and the detection of pulsars using Einstein@Home.
Volunteer computing can provide greater computing power, at lower cost, than conventional approaches such as organizational computing centers and commercial clouds, but participation in volunteer computing efforts is yet to reach its full potential.
TACC is partnering with the University of California at Berkeley and Purdue University to build new capabilities for BOINC (the most common software framework used for volunteer computing) to grow this promising mode of distributed computing. The project involves two complementary development efforts. Primero, it adds BOINC-based volunteer computing conduits to two major high-performance computing providers:TACC and nanoHUB, a web portal for nano science that provides computing capabilities. In this way, the project benefits the thousands of scientists who use these facilities and creates technologies that make it easy for other HPC providers to add their own volunteer computing capability to their systems.
Segundo, the team will develop a unified interface for volunteer computing, tentatively called Science United, where donors can register to participate and scientists can market their volunteer computing projects to the public.
TACC is currently setting up a BOINC server on Jetstream and using containerization technologies, such as Docker and VirtualBox, to build and package popular applications that can run in high-throughput computing mode on the devices of volunteers. Initial applications being tested include AutoDock Vina, used for drug discovery, and OpenSees, used by the natural hazards community. As a next step, TACC will develop the plumbing required for selecting and routing qualified jobs from TACC resources to the BOINC server.
"By creating a huge pool of low-cost computing power that will benefit thousands of scientists, and increasing public awareness of and interest in science, the project plans to establish volunteer computing as a central and long-term part of the U.S. scientific cyber infrastructure, " said David Anderson, the lead principal investigator on the project from UC Berkeley.