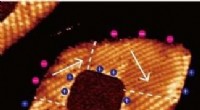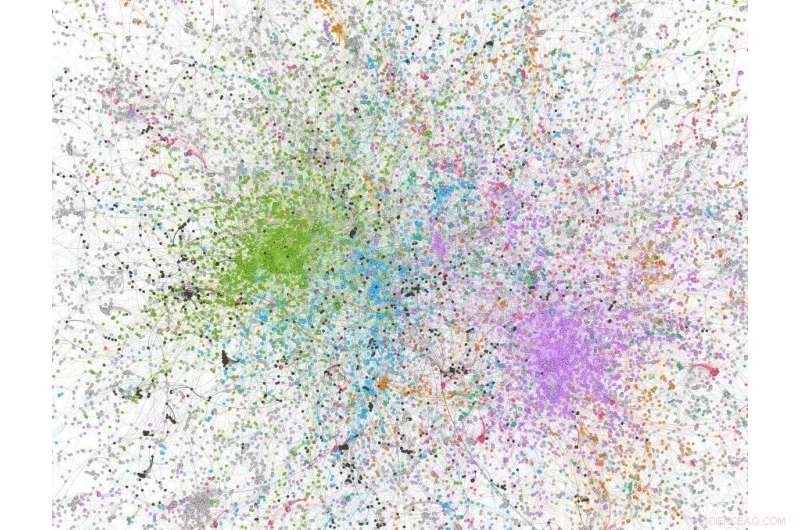
Cifra de análisis de red derivada de una muestra de 100, 000 tweets con 'covid' en el tweet; Los nodos de color verde son usuarios / organizaciones de Twitter de extrema derecha / muy conservadores. Crédito:Dhiraj Murthy, UT Austin
De las innumerables formas en que los investigadores están luchando contra la propagación del coronavirus, estudiar los Tweets puede que no sea lo primero que se te ocurra. Pero ahora, como en crisis pasadas, aprovechar uno de los principales servicios de mensajería en tiempo real del mundo puede ayudar a identificar nuevos puntos de acceso pandémico, resaltar nuevos síntomas, o interpretar cómo las personas y las comunidades están respondiendo a las órdenes de practicar el distanciamiento social.
El equipo de expertos en ciencia de datos del Texas Advanced Computing Center (TACC) ha facilitado el análisis de redes sociales en el pasado, y ha desarrollado herramientas de aprendizaje automático para extraer mejor las agujas de la información de los vastos pajar del Twitterverse.
A partir de marzo TACC comenzó a ingerir grandes cantidades de tweets al día:aproximadamente 40 millones de mensajes, de los cuales un millón son únicos. Combinando su colección con esfuerzos similares de grupos en UT Austin, la Universidad del Sur de California, y la Universidad Estatal de George, han extendido su colección de tweets relacionados con COVID-19 hasta enero. (La semana pasada, Twitter anunció que lanzaría nuevos puntos finales de API a su propia colección de tweets relacionados con COVID-19 para desarrolladores e investigadores aprobados).
"Existe un gran interés en este tipo de colecciones. Es muy útil en la ciencia de datos, "dijo Weijia Xu, quien gestiona el grupo de Inteligencia Computacional Escalable en TACC.
Hoy dia, TACC anunció un nuevo repositorio de GitHub donde los investigadores interesados pueden acceder tanto a punteros a datos sin procesar de Twitter relacionados con COVID-19 como a análisis a gran escala facilitados por las supercomputadoras de TACC.
El primero de los análisis disponibles para los investigadores es un conjunto de n-gramas:secuencias contiguas de palabras de una muestra determinada de tweets. El top 1, 000 uno-, dos-, y se han reunido secuencias de tres palabras para cada día de la pandemia. Reunir incluso un solo gramo de varios millones de tweets podría llevar hasta una hora en una computadora portátil debido a la cantidad de procesamiento de datos involucrado. pero se puede hacer en minutos en las supercomputadoras de TACC.
El equipo de investigación de TACC, dirigido por Xu, también ha estado trabajando en análisis de modelado de temas, identificar términos que aparecen frecuentemente en conexión entre sí, aunque no necesariamente en orden. Estos se agregarán al repositorio de GitHub en las próximas semanas.
Ambos métodos de agrupación pueden ser útiles para identificar tendencias sobre cómo la pandemia, y la respuesta de la gente, están evolucionando.
Los proyectos futuros que utilizan los datos incluyen una base de datos pública con capacidad de búsqueda; análisis de entidades:inspección de tweets de entidades conocidas, como figuras u organizaciones públicas, y devolución de información sobre esas entidades; y detección de eventos:detecta automáticamente la ocurrencia de eventos y los categoriza.
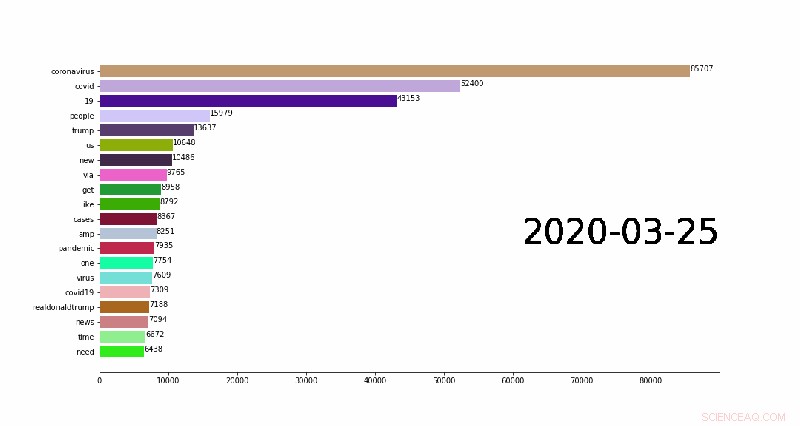
Una animación que muestra los 20 n-gramas diarios principales (palabras comunes en las publicaciones de Twitter) que cambian con el tiempo. Crédito:Weijia Xu, TACC
Estos esfuerzos serán facilitados por herramientas desarrolladas en TACC, como el proyecto Domain Information &Vocabulary Extraction, un esfuerzo financiado por la National Science Foundation para extraer entidades biológicas de publicaciones y otros documentos de texto utilizando el aprendizaje automático, que ha sido adaptado para otros tipos de extracción.
El objetivo principal de TACC, aquí, como en la mayoría de las cosas, es para facilitar la investigación de otros y los descubrimientos de poder. "Lo que más nos interesa es permitir que las personas accedan a conjuntos de datos seleccionados y ayudarlos a realizar investigaciones, "Dijo Xu." Estamos recolectando, limpiar, y procesar datos para que estén listos para que otros los usen ".
Investigadores de la Universidad de Texas en Austin (UT Austin) se encuentran entre los primeros en expresar interés en utilizar los conjuntos de datos de Twitter TACC COVID-19 para investigaciones específicas.
"La colección de Twitter de TACC COVID-19 será invaluable para permitirnos modelar patrones de comunicación y temas que surgen en las etapas de la enfermedad, "dijo Sharon Stover, a professor in the Moody College of Communications. "We may be able to compare the timeline to similar data from other countries such as China that experienced the epidemic earlier. This may lead us toward understanding when typical responses occur and help us to characterize how populations make sense of health pandemics at certain stages in an epidemic's process."
Strover is particularly interested in learning how one might segment tweets by certain population features to learn more about sub-networks that pass along certain information—or ignore it.
Dhiraj Murthy, an associate professor of Journalism and Sociology at UT Austin and author of the first scholarly book about Twitter, plans to use the dataset for his academic work.
"My lab is in the very initial stages of using these data to study two research questions:To what extent is fake news, misinformation, and disinformation regarding COVID-19 present on social media platforms? And:Are social media platforms being used as venues for racist messaging against people of Chinese/Asian origin within COVID-19-related posts?"
Matt Lease, from the UT School of Information, has been using the database to research misinformation in collaboration with Murthy, and also to identify incidents of racist messaging. "The large dataset TACC is collecting, along with its computing and storage services, plus excellent researchers and staff, makes it a fantastic resource for researchers interested in studying and combatting the spread of racist messaging on Twitter."
Both in the moment, and for retrospective analyses, Twitter data can be an incredible resource.
Said TACC research associate Ruizhu Huang:"The large volume of tweets collected at TACC provides a valuable date source to explore various perspectives on COVID-19. And the storage and supercomputing power at TACC will tremendously speed up the data analysis process."