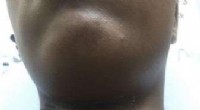
Al jugar el juego de cartas cooperativo Hanabi, los humanos se sentían frustrados y confundidos por los movimientos de su compañero de equipo de IA. Crédito:Bryan Mastergeorge
Cuando se trata de juegos como el ajedrez o el Go, los programas de inteligencia artificial (IA) han superado con creces a los mejores jugadores del mundo. Estas IA "sobrehumanas" son competidores incomparables, pero quizás sea más difícil que competir contra los humanos colaborar con ellos. ¿Puede la misma tecnología llevarse bien con las personas?
En un nuevo estudio, los investigadores del Laboratorio Lincoln del MIT buscaron descubrir qué tan bien los humanos podían jugar el juego de cartas cooperativo Hanabi con un modelo avanzado de IA entrenado para sobresalir jugando con compañeros de equipo que nunca antes había conocido. En experimentos ciegos simples, los participantes jugaron dos series del juego:una con el agente de IA como compañero de equipo y la otra con un agente basado en reglas, un bot programado manualmente para jugar de una manera predefinida.
Los resultados sorprendieron a los investigadores. No solo los puntajes no fueron mejores con el compañero de equipo de IA que con el agente basado en reglas, sino que los humanos odiaron constantemente jugar con su compañero de equipo de IA. Descubrieron que era impredecible, poco confiable y poco confiable, y se sintieron mal incluso cuando el equipo anotó bien. Se ha aceptado un documento que detalla este estudio en la Conferencia de 2021 sobre sistemas de procesamiento de información neuronal (NeurIPS).
"Realmente destaca la distinción matizada entre crear IA que funcione objetivamente bien y crear IA en la que se confíe o se prefiera subjetivamente", dice Ross Allen, coautor del artículo e investigador del Grupo de Tecnología de Inteligencia Artificial. "Puede parecer que esas cosas están tan cerca que realmente no hay luz del día entre ellas, pero este estudio mostró que esos son en realidad dos problemas separados. Necesitamos trabajar para desenredarlos".
Los humanos que odian a sus compañeros de equipo de IA podrían ser motivo de preocupación para los investigadores que diseñan esta tecnología para trabajar algún día con humanos en desafíos reales, como defenderse de misiles o realizar cirugías complejas. Esta dinámica, llamada inteligencia de equipo, es la próxima frontera en la investigación de IA y utiliza un tipo particular de IA llamado aprendizaje de refuerzo.
A una IA de aprendizaje por refuerzo no se le dice qué acciones tomar, sino que descubre qué acciones producen la "recompensa" más numérica probando escenarios una y otra vez. Es esta tecnología la que ha producido los jugadores de ajedrez y Go sobrehumanos. A diferencia de los algoritmos basados en reglas, estas IA no están programadas para seguir declaraciones "si/entonces", porque los posibles resultados de las tareas humanas que deben abordar, como conducir un automóvil, son demasiados para codificar.
"El aprendizaje por refuerzo es una forma mucho más general de desarrollar IA. Si puede entrenarla para que aprenda a jugar al ajedrez, ese agente no necesariamente irá a conducir un automóvil. Pero puede usar los mismos algoritmos para entrenar un agente diferente para conducir un automóvil, dados los datos correctos", dice Allen. "El cielo es el límite de lo que, en teoría, podría hacer".
Malas pistas, malas jugadas
Hoy en día, los investigadores están utilizando Hanabi para probar el rendimiento de los modelos de aprendizaje reforzado desarrollados para la colaboración, de la misma manera que el ajedrez ha servido como punto de referencia para probar la IA competitiva durante décadas.
El juego de Hanabi es similar a una forma multijugador de Solitario. Los jugadores trabajan juntos para apilar cartas del mismo palo en orden. Sin embargo, los jugadores no pueden ver sus propias cartas, solo las cartas que tienen sus compañeros de equipo. Cada jugador está estrictamente limitado en lo que puede comunicar a sus compañeros de equipo para que elijan la mejor carta de su propia mano para apilar a continuación.
Los investigadores del Laboratorio Lincoln no desarrollaron la IA ni los agentes basados en reglas utilizados en este experimento. Ambos agentes representan lo mejor en sus campos para el desempeño de Hanabi. De hecho, cuando el modelo de IA se emparejó previamente con un compañero de equipo de IA con el que nunca había jugado antes, el equipo logró el puntaje más alto para el juego de Hanabi entre dos agentes de IA desconocidos.
"Ese fue un resultado importante", dice Allen. "Pensamos, si esta IA que nunca antes se había conocido puede unirse y jugar muy bien, entonces deberíamos poder traer humanos que también sepan jugar muy bien junto con la IA, y también lo harán muy bien. Es por eso que pensamos que el equipo de IA jugaría mejor objetivamente, y también por qué pensamos que los humanos lo preferirían, porque generalmente nos gustará algo mejor si lo hacemos bien".
Ninguna de esas expectativas se hizo realidad. Objetivamente, no hubo diferencia estadística en las puntuaciones entre la IA y el agente basado en reglas. Subjetivamente, los 29 participantes informaron en las encuestas una clara preferencia por el compañero de equipo basado en reglas. No se informó a los participantes con qué agente estaban jugando para qué juegos.
"Un participante dijo que estaba tan estresado por la mala jugada del agente de IA que en realidad le dio dolor de cabeza", dice Jaime Pena, investigador del Grupo de Tecnología y Sistemas de IA y autor del artículo. "Otro dijo que pensaban que el agente basado en reglas era tonto pero viable, mientras que el agente de IA demostró que entendía las reglas, pero que sus movimientos no eran coherentes con la apariencia de un equipo. Para ellos, estaba dando malas pistas, haciendo malas jugadas".
Creatividad inhumana
Esta percepción de que la IA hace "malas jugadas" se vincula con comportamientos sorprendentes que los investigadores han observado previamente en el trabajo de aprendizaje por refuerzo. Por ejemplo, en 2016, cuando AlphaGo de DeepMind derrotó por primera vez a uno de los mejores jugadores de Go del mundo, uno de los movimientos más elogiados de AlphaGo fue el movimiento 37 en el juego 2, un movimiento tan inusual que los comentaristas humanos pensaron que era un error. Un análisis posterior reveló que el movimiento en realidad estaba muy bien calculado y se describió como "genial".
Dichos movimientos pueden ser elogiados cuando un oponente de IA los realiza, pero es menos probable que se celebren en un entorno de equipo. Los investigadores del Laboratorio Lincoln descubrieron que los movimientos extraños o aparentemente ilógicos eran los peores delincuentes para romper la confianza de los humanos en su compañero de equipo de IA en estos equipos estrechamente acoplados. Tales movimientos no solo disminuyeron la percepción de los jugadores de qué tan bien ellos y su compañero de equipo de IA trabajaron juntos, sino también cuánto querían trabajar con la IA, especialmente cuando cualquier beneficio potencial no era inmediatamente obvio.
"Hubo muchos comentarios sobre darse por vencidos, comentarios como 'Odio trabajar con esto'", agrega Hosea Siu, también autor del artículo e investigador del Grupo de Ingeniería de Sistemas Autónomos y de Control.
Los participantes que se calificaron a sí mismos como expertos en Hanabi, lo que hizo la mayoría de los jugadores en este estudio, a menudo se dieron por vencidos con el jugador de IA. Siu encuentra esto preocupante para los desarrolladores de IA, porque los usuarios clave de esta tecnología probablemente serán expertos en el dominio.
"Digamos que entrena a un asistente de guía de inteligencia artificial superinteligente para un escenario de defensa antimisiles. No se lo está pasando a un aprendiz; se lo está pasando a sus expertos en sus barcos que han estado haciendo esto durante 25 años. Entonces, si hay un fuerte sesgo de expertos en contra en escenarios de juegos, es probable que aparezca en operaciones del mundo real”, agrega.
Humanos blandos
Los investigadores señalan que la IA utilizada en este estudio no se desarrolló para las preferencias humanas. Pero eso es parte del problema, no muchos lo son. Como la mayoría de los modelos de IA colaborativos, este modelo se diseñó para obtener la puntuación más alta posible y su éxito se ha comparado con su rendimiento objetivo.
Si los investigadores no se enfocan en la cuestión de la preferencia humana subjetiva, "entonces no crearemos IA que los humanos realmente quieran usar", dice Allen. "Es más fácil trabajar con IA que mejora un número muy limpio. Es mucho más difícil trabajar con IA que funciona en este mundo más confuso de preferencias humanas".
Resolver este problema más difícil es el objetivo del proyecto MeRLin (Mission-Ready Reinforcement Learning), bajo el cual se financió este experimento en la Oficina de Tecnología del Laboratorio Lincoln, en colaboración con el Acelerador de Inteligencia Artificial de la Fuerza Aérea de EE. UU. y el Departamento de Ingeniería Eléctrica e Informática del MIT. Ciencias. El proyecto está estudiando qué ha impedido que la tecnología de IA colaborativa salte del espacio del juego a una realidad más desordenada.
Los investigadores creen que la capacidad de la IA para explicar sus acciones generará confianza. Este será el enfoque de su trabajo para el próximo año.
"You can imagine we rerun the experiment, but after the fact—and this is much easier said than done—the human could ask, 'Why did you do that move, I didn't understand it?' If the AI could provide some insight into what they thought was going to happen based on their actions, then our hypothesis is that humans would say, 'Oh, weird way of thinking about it, but I get it now,' and they'd trust it. Our results would totally change, even though we didn't change the underlying decision-making of the AI," Allen says.
Like a huddle after a game, this kind of exchange is often what helps humans build camaraderie and cooperation as a team.
"Maybe it's also a staffing bias. Most AI teams don't have people who want to work on these squishy humans and their soft problems," Siu adds, laughing. "It's people who want to do math and optimization. And that's the basis, but that's not enough."
Mastering a game such as Hanabi between AI and humans could open up a universe of possibilities for teaming intelligence in the future. But until researchers can close the gap between how well an AI performs and how much a human likes it, the technology may well remain at machine versus human.