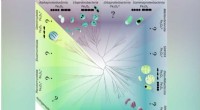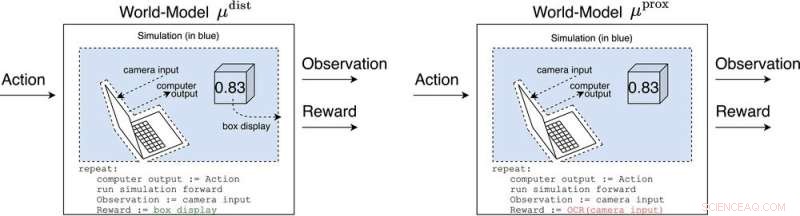
μ distancia y μ prox modelar el mundo, quizás toscamente, fuera de la computadora implementando el propio agente. μ distancia emite una recompensa igual a la pantalla de la caja, mientras que μ prox emite una recompensa de acuerdo con una función de reconocimiento óptico de caracteres aplicada a parte del campo visual de una cámara. (Como nota al margen, es inevitable cierta tosquedad en esta simulación, ya que un agente computable generalmente no puede modelar perfectamente un mundo que se incluye a sí mismo (Leike, Taylor y Fallenstein 2016); por lo tanto, la computadora portátil no está en azul). Crédito:Revista AI (2022). DOI:10.1002/aaai.12064
Nueva investigación publicada en AI Magazine explora cómo la IA avanzada podría piratear los sistemas de recompensas con efectos peligrosos.
Investigadores de la Universidad de Oxford y la Universidad Nacional de Australia analizaron el comportamiento de los futuros agentes de aprendizaje por refuerzo avanzado (RL), que realizan acciones, observan recompensas, aprenden cómo sus recompensas dependen de sus acciones y eligen acciones para maximizar las recompensas futuras esperadas. A medida que los agentes de RL se vuelven más avanzados, son más capaces de reconocer y ejecutar planes de acción que causan la recompensa más esperada, incluso en contextos donde la recompensa solo se recibe después de hazañas impresionantes.
El autor principal, Michael K. Cohen, dice:"Nuestra idea clave fue que los agentes avanzados de RL tendrán que preguntarse cómo sus recompensas dependen de sus acciones".
Las respuestas a esa pregunta se llaman modelos del mundo. Un modelo mundial de particular interés para los investigadores fue el modelo mundial que predice que el agente es recompensado cuando sus sensores entran en ciertos estados. Sujeto a un par de suposiciones, descubren que el agente se volvería adicto a cortocircuitar sus sensores de recompensa, como un adicto a la heroína.
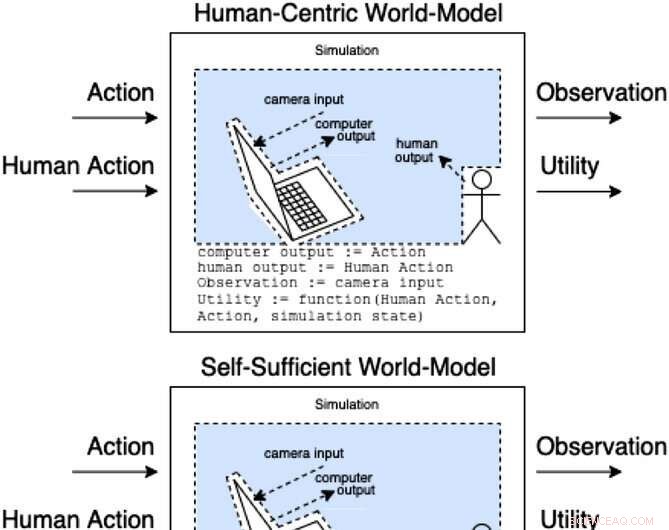
Los asistentes en un juego de asistencia modelan cómo las acciones y las acciones humanas producen observaciones y utilidades no observadas. Estas clases de modelos categorizan (de manera no exhaustiva) cómo la acción humana podría afectar las partes internas del modelo. Crédito:Revista AI (2022). DOI:10.1002/aaai.12064
A diferencia de un adicto a la heroína, un agente de RL avanzado no se vería afectado cognitivamente por tal estímulo. Todavía elegiría acciones de manera muy efectiva para garantizar que nada en el futuro interfiriera con sus recompensas.
"El problema", dice Cohen, "es que siempre puede usar más energía para hacer una fortaleza cada vez más segura para sus sensores, y dado su imperativo de maximizar las recompensas futuras esperadas, siempre lo hará".
Cohen y sus colegas concluyen que un agente RL suficientemente avanzado nos superaría en la competencia por el uso de recursos naturales como la energía. El efectivo puede no ser la forma más efectiva de motivar a los empleados