Ninguna. Crédito:Wenjing Lu, Weizhong Huo, Huwanbieke Gulina, Chao Pan.
La producción cada vez mayor de desechos sólidos ha estado amenazando el medio ambiente natural y la seguridad humana en los últimos años. Con el aumento de la urbanización en todo el mundo, los residuos sólidos municipales (RSU) han aumentado significativamente. La gestión integrada de RSU es un método eficaz, pero la predicción precisa de la generación de RSU es un problema complejo. Algunos modelos de predicción tradicionales (modelo de regresión lineal multivariable, modelo de análisis de series temporales, etc.) tienen éxito utilizando métodos simples, pero generalmente seleccionan un modelo matemático básico de antemano, lo que limita la capacidad de reflejar verdaderamente las características de los RSU.
Los modelos de predicción de máquinas con alta precisión, que pueden obtener nuevos datos complejos y extraerlos en profundidad, se utilizan cada vez más para crear predicciones a corto, mediano y largo plazo para la generación de RSU. Entre ellos, se han empleado algoritmos como la red neuronal artificial (ANN), la máquina de vectores de soporte (SVM) y el árbol de regresión de impulso de gradiente (GBRT) para pronosticar la generación de RSU. Sin embargo, la falta de un modelo de alta precisión basado en la recopilación de datos a gran escala y una amplia gama de variables de influencia limita la amplia aplicabilidad del modelo.
Para satisfacer las necesidades del tratamiento integral a gran escala y realizar la predicción de generación de RSU a corto plazo, el profesor Weijing Lu de la Universidad de Tinghua y los miembros del equipo trabajaron juntos y utilizaron una amplia gama de datos (en todo el país, basados en ciudades) de 130 ciudades de China y variables de características de varios niveles (por ejemplo, factores socioeconómicos, condiciones naturales y condiciones internas) para establecer un modelo de aprendizaje automático de varias ciudades de generación de RSU con alta precisión. Su trabajo analizó y exploró los modelos de gestión de residuos de dos grandes ciudades típicas (Beijing y Shenzhen) en China. Este estudio, titulado "Desarrollo del modelo multiciudad de aprendizaje automático para la predicción de la generación de residuos sólidos municipales", se publica en línea en Frontiers of Environmental Science &Engineering. .
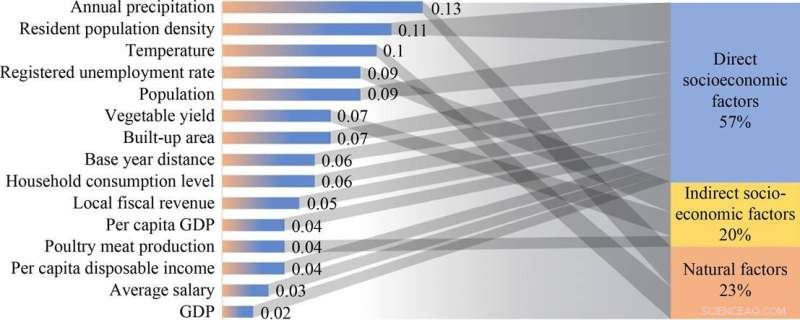
En este estudio, se construyó una base de datos de generación de RSU y variables de características que cubren 130 ciudades de China. Basado en la base de datos, se adoptó un algoritmo de aprendizaje automático avanzado (GBRT) para construir el modelo de predicción de generación de residuos (WGMod). En el proceso de desarrollo del modelo, los principales factores que influyen en la generación de RSU se identificaron mediante un análisis ponderado. Los factores influyentes clave seleccionados fueron la precipitación anual, la densidad de población y la temperatura media anual con pesos del 13%, 11% y 10%, respectivamente.
El WGMod mostró un buen rendimiento con R 2 =0,939. La predicción del modelo sobre la generación de RSU en Beijing y Shenzhen indica que la generación de desechos en Beijing aumentaría gradualmente en los próximos 3 a 5 años, mientras que en Shenzhen crecería rápidamente en los próximos 3 años. La diferencia entre los dos se debe principalmente a las diferentes tendencias de crecimiento de la población.
Este estudio estableció una base de datos de generación de RSU y variables de características con 1012 conjuntos de datos que cubren 130 ciudades de China. El WGMod desarrollado funciona razonablemente bien y es muy adecuado para predecir la generación de RSU en China. Este estudio proporcionó métodos científicos y datos básicos para el desarrollo de un modelo multiciudad para la generación de RSU. Los gemelos digitales de la ciudad ayudan a entrenar modelos de aprendizaje profundo para separar las fachadas de los edificios