Ejemplo del algoritmo de colocación de macros propuesto por Google. Crédito:Science China Press
La automatización del diseño electrónico (EDA) o el diseño asistido por computadora (CAD) es una categoría de herramientas de software para diseñar sistemas electrónicos, como circuitos integrados (IC). Con las herramientas EDA, los diseñadores pueden terminar el flujo de diseño de chips integrados a muy gran escala (VLSI) con miles de millones de transistores. Las herramientas EDA son esenciales para el diseño VLSI moderno debido a la gran escala y la alta complejidad de los sistemas electrónicos.
Recientemente, con el auge de los algoritmos de inteligencia artificial (IA), la comunidad EDA está explorando activamente técnicas de IA para IC para el diseño de chips avanzados. Muchos estudios han explorado técnicas basadas en aprendizaje automático (ML) para tareas de predicción entre etapas en el flujo de diseño para lograr una convergencia de diseño más rápida. Por ejemplo, Google publicó un artículo en Nature en 2021 titulado "Una metodología de ubicación de gráficos para el diseño rápido de chips", aprovechando el aprendizaje por refuerzo (RL) para colocar macros en un diseño de chip.
La idea básica es considerar el diseño de fichas como un tablero Go, mientras que cada macro es una piedra. De esta forma, un agente de RL puede recibir una formación previa con 10 000 muestras de diseño interno y aprender a colocar una macro a la vez. Al ajustar el agente en cada diseño durante aproximadamente 6 horas, puede superar el rendimiento de las herramientas EDA convencionales en los chips de TPU de Google y lograr un mejor rendimiento, potencia y área (PPA).
Se puede ver que la "IA para EDA" se está explorando activamente en la comunidad de automatización del diseño. Aunque la construcción de modelos de ML generalmente requiere una gran cantidad de datos, la mayoría de los estudios solo pueden generar pequeños conjuntos de datos internos para la validación, debido a la falta de grandes conjuntos de datos públicos y la dificultad en la generación de datos. Con este fin, se desea con urgencia un conjunto de datos de código abierto dedicado a las tareas de ML en EDA.
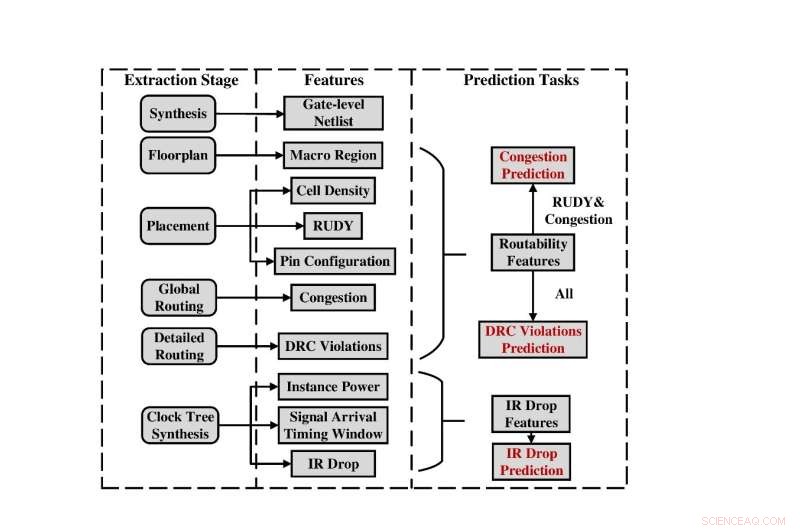
Flujo general para la recopilación de datos y la extracción de características. Crédito:Science China Press
Para abordar este problema, el grupo de investigación de la Universidad de Pekín ha lanzado el primer conjunto de datos de código abierto, llamado CircuitNet, que está dedicado a la IA para aplicaciones IC en VLSI CAD. El conjunto de datos consta de más de 10 000 muestras y 54 netlists de circuitos sintetizados a partir de seis diseños RISC-V de código abierto, brinda soporte holístico para tareas de predicción entre etapas y admite tareas que incluyen predicción de congestión de enrutamiento, predicción de violaciones de verificación de reglas de diseño (DRC) e IR caída de predicción. Las principales características de CircuitNet se pueden resumir de la siguiente manera:
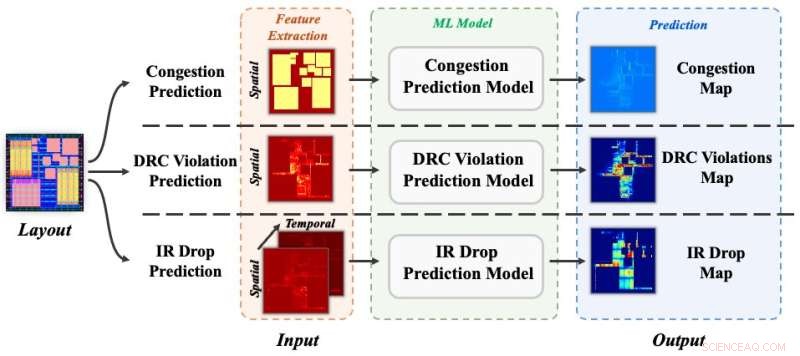
Tres tareas de predicción de etapas cruzadas:congestión, violaciones de DRC y caída de IR. Crédito:Science China Press
Para evaluar la efectividad de CircuitNet, los autores validan el conjunto de datos mediante experimentos en tres tareas de predicción:congestión, violaciones de DRC y caída de IR. Cada experimento toma un método de estudios recientes y evalúa su resultado en CircuitNet con las mismas métricas de evaluación que los estudios originales. En general, los resultados son consistentes con las publicaciones originales, lo que demuestra la efectividad de CircuitNet. Un tutorial detallado sobre la configuración experimental está disponible en GitHub. En el futuro, los autores planean incorporar más muestras de datos con diseños a gran escala en nodos de tecnología avanzada para mejorar la escala y la diversidad del conjunto de datos.
La investigación fue publicada en Science China Information Sciences . Los gemelos digitales de la ciudad ayudan a entrenar modelos de aprendizaje profundo para separar las fachadas de los edificios