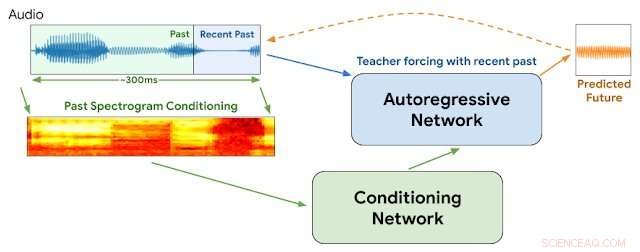
Arquitectura WaveNetEQ. Durante la inferencia, "calentamos" la red autorregresiva forzando al maestro con el audio más reciente. Después, el modelo se suministra con su propia salida como entrada para el siguiente paso. Un espectrograma MEL de una parte de audio más larga se utiliza como entrada para la red de acondicionamiento. Crédito:Google
"Es bueno escuchar tu voz, sabes que ha pasado tanto tiempo
Si no recibo tus llamadas entonces todo sale mal ...
Tu voz al otro lado de la línea me da una sensación extraña "
- Rubia, "Colgando del teléfono"
En 1978, Debbie Harry impulsó a su banda de new wave Blondie a la cima de las listas de éxitos con una historia quejumbrosa de anhelo de escuchar la voz de su novio desde lejos e insistiendo en que no la dejara "colgando del teléfono".
Pero surgen las preguntas:¿Qué pasaría si fuera 2020 y ella estuviera hablando por VOIP con pérdidas de paquetes intermitentes? jitter de audio, retrasos en la red y transmisiones de paquetes fuera de secuencia?
Nunca sabremos.
Pero esta semana Google anunció detalles de una nueva tecnología para su popular aplicación de voz y video Duo que ayudará a garantizar transmisiones de voz más fluidas y reducirá las brechas momentáneas que a veces estropean las conexiones basadas en Internet. Nos gustaría pensar que Debbie lo aprobaría.
Todos hemos experimentado fluctuaciones en el audio de Internet. Ocurre cuando uno o más paquetes de instrucciones que comprenden un flujo de instrucciones de audio se retrasan o se mezclan fuera de orden entre el llamante y el oyente. Los métodos que emplean búferes de paquetes de voz e inteligencia artificial generalmente pueden suavizar una fluctuación de 20 milisegundos o menos. Pero las interrupciones se vuelven más notorias cuando los paquetes faltantes suman 60 milisegundos y más.
Google dice que prácticamente todas las llamadas experimentan alguna pérdida de paquetes de datos:una quinta parte de todas las llamadas pierden el 3 por ciento de su audio y una décima parte pierde el 8 por ciento.
Esta semana, Los investigadores de Google en la división DeepMind informaron que han comenzado a utilizar un programa llamado WaveNetEQ para abordar estos problemas. El algoritmo sobresale en llenar brechas de sonido momentáneas con elementos de voz sintetizados pero que suenan naturales. Confiando en una biblioteca voluminosa de datos de voz, WaveNetEQ llena los huecos de sonido de hasta 120 milisegundos. Estos intercambios de bits de sonido se denominan ocultación de pérdida de paquetes (PLC).
"WaveNetEQ es un modelo generativo basado en la tecnología WaveRNN de DeepMind, "El blog de inteligencia artificial de Google informó el 1 de abril, "que se entrena utilizando un gran corpus de datos de voz para continuar de manera realista segmentos de voz cortos, lo que le permite sintetizar completamente la forma de onda sin procesar de la voz que falta".
El programa analizó los sonidos de 100 hablantes en 48 idiomas, centrándose en "las características del habla humana en general, en lugar de las propiedades de un idioma específico, "explicaba el informe.
Además, El análisis de sonido se probó en entornos que ofrecen una amplia variedad de ruido de fondo para ayudar a garantizar un reconocimiento preciso por parte de los oradores en las aceras concurridas de la ciudad. estaciones de tren o cafeterías.
Todo el procesamiento de WaveNetEQ debe ejecutarse en el teléfono del receptor para que los servicios de cifrado no se vean comprometidos. Pero la demanda adicional de velocidad de procesamiento es mínima, Afirma Google. WaveNetEQ es "lo suficientemente rápido para ejecutarse en un teléfono, sin dejar de ofrecer una calidad de audio de vanguardia y un PLC con un sonido más natural que otros sistemas actualmente en uso ".
Las muestras de sonidos que ilustran la fluctuación del audio y la mejora con WabeNetEQ se publican en el informe del blog de Google.
© 2020 Science X Network