Crédito:Instituto de Tecnología de Massachusetts
A pesar de todo el progreso que los investigadores han logrado con el aprendizaje automático para ayudarnos a hacer cosas como calcular números, conducir coches y detectar el cáncer, Rara vez pensamos en la cantidad de energía que requiere mantener los enormes centros de datos que hacen posible ese trabajo. En efecto, un estudio de 2017 predijo que, para 2025, los dispositivos conectados a Internet consumirían el 20 por ciento de la electricidad del mundo.
La ineficiencia del aprendizaje automático es en parte una función de cómo se crean dichos sistemas. Las redes neuronales se desarrollan típicamente generando un modelo inicial, ajustando algunos parámetros, intentándolo de nuevo, y luego enjuagar y repetir. Pero este enfoque significa que un tiempo significativo, La energía y los recursos informáticos se gastan en un proyecto antes de que nadie sepa si realmente funcionará.
El estudiante graduado del MIT, Jonathan Rosenfeld, lo compara con los científicos del siglo XVII que buscaban comprender la gravedad y el movimiento de los planetas. Él dice que la forma en que desarrollamos los sistemas de aprendizaje automático hoy en día, en ausencia de tal comprensión, tiene un poder predictivo limitado y, por lo tanto, es muy ineficiente.
"Todavía no existe una forma unificada de predecir qué tan bien funcionará una red neuronal dados ciertos factores como la forma del modelo o la cantidad de datos con los que se ha entrenado, "dice Rosenfeld, quien recientemente desarrolló un nuevo marco sobre el tema con colegas del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT (CSAIL). "Queríamos explorar si podíamos hacer avanzar el aprendizaje automático tratando de comprender las diferentes relaciones que afectan la precisión de una red".
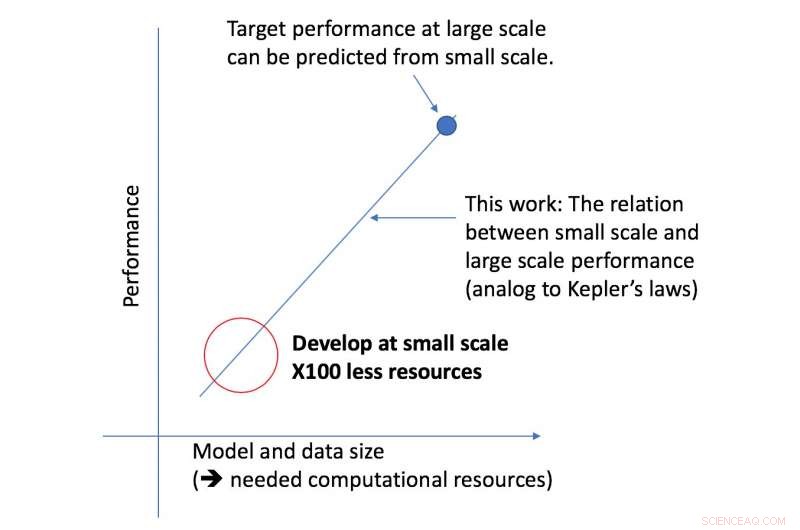
El nuevo marco del equipo de CSAIL analiza un algoritmo dado a una escala más pequeña, y, basado en factores como su forma, puede predecir qué tan bien funcionará a mayor escala. Esto permite que un científico de datos determine si vale la pena continuar dedicando más recursos para capacitar aún más al sistema.
"Nuestro enfoque nos dice cosas como la cantidad de datos necesarios para que una arquitectura entregue un rendimiento objetivo específico, o la compensación más eficiente desde el punto de vista computacional entre los datos y el tamaño del modelo, "dice el profesor del MIT Nir Shavit, quien coescribió el nuevo artículo con Rosenfeld, el ex estudiante de doctorado Yonatan Belinkov y Amir Rosenfeld de la Universidad de York. "Consideramos que estos hallazgos tienen implicaciones de gran alcance en el campo al permitir que los investigadores del mundo académico y de la industria comprendan mejor las relaciones entre los diferentes factores que deben sopesarse al desarrollar modelos de aprendizaje profundo". y hacerlo con los limitados recursos computacionales disponibles para los académicos ".
El marco permitió a los investigadores predecir con precisión el rendimiento en el modelo grande y escalas de datos utilizando cincuenta veces menos poder computacional.
El aspecto del rendimiento del aprendizaje profundo en el que se centró el equipo es el llamado "error de generalización, "que se refiere al error generado cuando se prueba un algoritmo con datos del mundo real. El equipo utilizó el concepto de escala del modelo, lo que implica cambiar la forma del modelo de formas específicas para ver su efecto sobre el error.
Como siguiente paso, el equipo planea explorar las teorías subyacentes de lo que hace que el rendimiento de un algoritmo específico tenga éxito o falle. Esto incluye experimentar con otros factores que pueden afectar el entrenamiento de modelos de aprendizaje profundo.