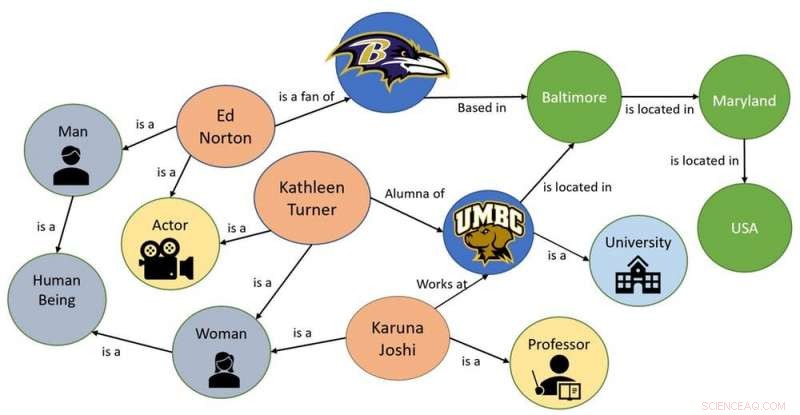
Un ejemplo de un gráfico de conocimiento simple. Crédito:Karuna Pande Joshi, CC BY-ND
Está rastreando bits de datos personales, como números de tarjetas de crédito, preferencias de compra y qué artículos de noticias lee mientras viaja por Internet. Las grandes empresas de Internet ganan dinero con este tipo de información personal compartiéndola con sus subsidiarias y terceros. La preocupación pública por la privacidad en línea ha llevado a leyes diseñadas para controlar quién obtiene esos datos y cómo pueden usarlos.
La batalla continúa. Los demócratas en el Senado de los Estados Unidos presentaron recientemente un proyecto de ley que incluye sanciones para las empresas de tecnología que manejen mal los datos personales de los usuarios. Esa ley se uniría a una larga lista de reglas y regulaciones en todo el mundo, incluido el Estándar de seguridad de datos de la industria de tarjetas de pago que regula las transacciones con tarjetas de crédito en línea, el Reglamento general de protección de datos de la Unión Europea, la Ley de Privacidad del Consumidor de California que entró en vigor en enero, y la Ley de protección de la privacidad en línea de los niños de EE. UU.
Las empresas de Internet deben adherirse a estas regulaciones o arriesgarse a costosas demandas judiciales o sanciones gubernamentales. como la reciente multa de 5 mil millones de dólares de la Comisión Federal de Comercio impuesta a Facebook.
Pero es un desafío técnico determinar en tiempo real si se ha producido una violación de la privacidad. un problema que se está volviendo aún más problemático a medida que los datos de Internet se mueven a una escala extrema. Para asegurarse de que sus sistemas cumplan, las empresas confían en expertos humanos para interpretar las leyes, una tarea compleja y que requiere mucho tiempo para las organizaciones que constantemente lanzan y actualizan servicios.
Mi grupo de investigación en la Universidad de Maryland, Condado de Baltimore, ha desarrollado tecnologías novedosas para que las máquinas comprendan las leyes de privacidad de datos y hagan cumplir su cumplimiento mediante inteligencia artificial. Estas tecnologías permitirán a las empresas asegurarse de que sus servicios cumplan con las leyes de privacidad y también ayudarán a los gobiernos a identificar en tiempo real a aquellas empresas que violan los derechos de privacidad de los consumidores.
Ayudar a las máquinas a comprender las regulaciones
Los gobiernos generan regulaciones de privacidad en línea como documentos de texto sin formato que son fáciles de leer para los humanos pero difíciles de interpretar para las máquinas. Como resultado, Las regulaciones deben examinarse manualmente para garantizar que no se infrinjan las reglas cuando se analizan o comparten los datos privados de un ciudadano. Esto afecta a empresas que ahora tienen que cumplir con una serie de regulaciones.
Las reglas y regulaciones a menudo son ambiguas por diseño porque las sociedades quieren flexibilidad para implementarlas. Los conceptos subjetivos como bueno y malo varían entre culturas y con el tiempo, por lo tanto, las leyes se redactan en términos generales o vagos para dar cabida a modificaciones futuras. Las máquinas no pueden procesar esta vaguedad, operan en 1 y 0, por lo que no pueden "entender" la privacidad como lo hacen los humanos. Las máquinas necesitan instrucciones específicas para comprender el conocimiento en el que se basa una regulación.

La aplicación de los investigadores extrajo automáticamente las reglas deontic, como permisos y obligaciones, de dos regulaciones de privacidad. Las entidades involucradas en las reglas están resaltadas en amarillo. Palabras modales que ayudan a identificar si una regla es un permiso, la prohibición u obligación se destacan en azul. El gris indica el aspecto temporal o basado en el tiempo de la regla. Crédito:Karuna Pande Joshi, CC BY-ND
Una forma de ayudar a las máquinas a comprender un concepto abstracto es mediante la creación de una ontología, o un gráfico que represente el conocimiento de ese concepto. Tomando prestados los conceptos de ontología de la filosofía, nuevos lenguajes informáticos, como OWL, se han desarrollado en IA. Estos lenguajes pueden definir conceptos y categorías en un área temática o dominio, mostrar sus propiedades y mostrar las relaciones entre ellos. Las ontologías a veces se denominan "gráficos de conocimiento, "porque se almacenan en estructuras de tipo gráfico.
Cuando mis colegas y yo comenzamos a considerar el desafío de hacer que las máquinas pudieran entender las regulaciones de privacidad, determinamos que el primer paso sería capturar todo el conocimiento clave en estas leyes y crear gráficos de conocimiento para almacenarlo.
Extrayendo los términos y reglas
El conocimiento clave en las regulaciones consta de tres partes.
Primero, hay "términos del arte":palabras o frases que tienen definiciones precisas dentro de una ley. Ayudan a identificar la entidad que describe la regulación y nos permiten describir sus roles y responsabilidades en un lenguaje que las computadoras puedan entender. Por ejemplo, del Reglamento general de protección de datos de la UE, extrajimos términos del arte como "Consumidores y proveedores" y "Multas y ejecución".
Próximo, identificamos reglas deónticas:oraciones o frases que nos proporcionan una lógica modal filosófica, que se ocupa de la conducta deductiva. Las reglas deónticas (o morales) incluyen oraciones que describen deberes u obligaciones y se dividen principalmente en cuatro categorías. Los "permisos" definen los derechos de una entidad / actor. Las "obligaciones" definen las responsabilidades de una entidad / actor. Las "prohibiciones" son condiciones o acciones que no están permitidas. Las "dispensaciones" son declaraciones opcionales o no obligatorias.
Para explicar esto con un ejemplo simple, considera lo siguiente:

gráfico de conocimiento para las regulaciones GDPR. Crédito:Karuna Pande Joshi, CC BY-ND
Algunas de estas reglas se aplican a todos de manera uniforme en todas las condiciones; mientras que otros pueden aplicar parcialmente, a una sola entidad o en función de las condiciones acordadas por todos.
Se aplican reglas similares que describen lo que se debe y no se debe hacer a los datos personales en línea. Existen permisos y prohibiciones para prevenir violaciones de datos. Las empresas que almacenan los datos tienen obligaciones para garantizar su seguridad. Y hay dispensas hechas para grupos demográficos vulnerables como los menores.
Mi grupo desarrolló técnicas para extraer automáticamente estas reglas de las regulaciones y guardarlas en un gráfico de conocimiento.
En tercer lugar, también tuvimos que averiguar cómo incluir las referencias cruzadas que se utilizan a menudo en las regulaciones legales para hacer referencia al texto en otra sección de la regulación o en un documento separado. Estos son elementos de conocimiento importantes que también deben almacenarse en el gráfico de conocimiento.
Reglas en su lugar, escaneo para cumplimiento
Después de definir todas las entidades clave, propiedades, relaciones, reglas y políticas de una ley de privacidad de datos en un gráfico de conocimiento, mis colegas y yo podemos crear aplicaciones que puedan razonar sobre las reglas de privacidad de datos utilizando estos gráficos de conocimiento.
Estas aplicaciones pueden reducir significativamente el tiempo que les llevará a las empresas determinar si están cumpliendo con las regulaciones de protección de datos. También pueden ayudar a los reguladores a monitorear las pistas de auditoría de datos para determinar si las empresas que supervisan están cumpliendo con las reglas.
Esta tecnología también puede ayudar a las personas a obtener una instantánea rápida de sus derechos y responsabilidades con respecto a los datos privados que comparten con las empresas. Una vez que las máquinas puedan interpretar rápidamente políticas de privacidad complejas, las personas podrán automatizar muchas actividades de cumplimiento mundanas que se realizan manualmente en la actualidad. También pueden hacer que esas políticas sean más comprensibles para los consumidores.
Este artículo se vuelve a publicar de The Conversation bajo una licencia Creative Commons. Lea el artículo original.