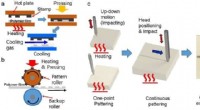
Muestras de imágenes fijas de traducciones generadas por modelos (la fila superior son imágenes humanas reales, la fila inferior son imágenes de robots falsos). Crédito:Smith et al.
En años recientes, Los equipos de investigación de todo el mundo han estado utilizando el aprendizaje por refuerzo (RL) para enseñar a los robots cómo completar una variedad de tareas. Entrenando estos algoritmos, sin embargo, puede ser muy desafiante, ya que también requiere un esfuerzo humano sustancial para definir correctamente las tareas que debe completar el robot.
Una forma de enseñar a los robots cómo completar tareas específicas es a través de demostraciones con humanos. Si bien esto puede parecer sencillo, puede ser muy difícil de implementar, principalmente porque los robots y los humanos tienen cuerpos muy diferentes, por tanto, son capaces de diferentes movimientos.
Investigadores de la Universidad de California en Berkeley han desarrollado recientemente un nuevo marco que podría ayudar a superar algunos de los desafíos encontrados al entrenar robots a través del aprendizaje por imitación (es decir, usando demostraciones humanas). Su marco, llamado AVID, en basado en dos modelos de aprendizaje profundo desarrollados en investigaciones anteriores.
"Al desarrollar AVID, construimos en gran parte sobre dos obras recientes, CycleGAN y SOLAR, que introdujo enfoques para abordar las limitaciones fundamentales que han impedido el aprendizaje de videos humanos en el cambio de dominio y el entrenamiento en un robot físico a partir de la entrada visual, respectivamente, "Laura Smith, uno de los investigadores que realizó el estudio, dijo a TechXplore.
En lugar de utilizar técnicas que no tienen en cuenta las diferencias entre un robot y el cuerpo de un usuario humano, Smith y sus colegas utilizaron Cycle-GAN, una técnica que puede transformar imágenes a nivel de píxel. Usando Cycle-GAN, su método convierte demostraciones humanas de cómo completar una tarea determinada en videos de un robot que realiza la misma tarea. Luego utilizaron estos videos para desarrollar una función de recompensa para un algoritmo RL.

Muestras de imágenes fijas de traducciones generadas por modelos (la fila superior son imágenes humanas reales, la fila inferior son imágenes de robots falsos). Crédito:Smith et al.
"AVID funciona haciendo que el robot observe a un humano realizar alguna tarea y luego imagine cómo se vería por sí mismo para realizar la misma cosa, ", Explicó Smith." Para saber cómo lograr realmente este éxito imaginado, dejamos que el robot aprenda por ensayo y error ".
Usando el marco desarrollado por Smith y sus colegas, un robot aprende tareas una etapa a la vez, reiniciar cada etapa y volver a intentarlo sin requerir la intervención de un usuario humano. Por tanto, el proceso de aprendizaje se automatiza en gran medida, con el robot aprendiendo nuevas habilidades con una mínima intervención humana.
"Una ventaja clave de nuestro enfoque es que el profesor humano puede interactuar con el estudiante robot mientras aprende, "Smith explicó." Además, diseñamos nuestro marco de capacitación para que sea susceptible de aprender el comportamiento a largo plazo con un esfuerzo mínimo ".
Los investigadores evaluaron su enfoque en una serie de ensayos y descubrieron que puede enseñar a los robots de manera efectiva cómo completar tareas complejas. como operar una máquina de café, simplemente procesando 20 minutos de videos de demostración humana sin procesar y practicando la nueva habilidad durante 180 minutos. Además, AVID superó todas las otras técnicas a las que fue, incluida la ablación por imitación, ablación del espacio de píxeles, y enfoques de clonación conductual.
"Lo que descubrimos es que podemos aprovechar CycleGAN para hacer que los videos de demostraciones humanas sean comprensibles para el robot sin requerir un tedioso proceso de recopilación de datos, ", Dijo Smith." También demostramos que explotar la naturaleza de múltiples etapas de las tareas extendidas temporalmente nos permite aprender un comportamiento sólido al tiempo que facilita el entrenamiento. Vemos nuestro trabajo como un paso significativo para poner al alcance el despliegue de robots autónomos en el mundo real, ya que nos brinda una experiencia muy natural, forma intuitiva para que les enseñemos ".
El nuevo marco de aprendizaje introducido por Smith y sus colegas permite un tipo diferente de aprendizaje por imitación, donde un robot aprende a completar un objetivo de nivel superior a la vez, centrándose en lo que encuentra más desafiante en cada paso. Es más, en lugar de requerir que los usuarios humanos reinicien la escena después de cada prueba de práctica, permite a los robots restablecer la escena automáticamente y continuar practicando. En el futuro, AVID podría mejorar los procesos de aprendizaje por imitación, permitiendo a los desarrolladores entrenar robots de forma más rápida y eficaz.
"Una de las principales limitaciones de nuestro trabajo hasta ahora es que requerimos la recopilación de datos y el entrenamiento de CycleGAN para cada nueva escena que pueda encontrar el robot. Esperamos poder tratar el entrenamiento de CycleGAN como una sola vez, un costo inicial tal que capacitar una vez en un gran corpus de datos puede permitir que el robot adquiera rápidamente una amplia variedad de habilidades con algunas demostraciones y un poco de práctica ".
© 2020 Science X Network