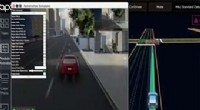
Crédito:Nvidia
El objetivo:convertir imágenes 2-D en modelos 3-D utilizando una arquitectura especial de codificador-decodificador. Los actores:Nvidia. El elogio:una utilización inteligente del aprendizaje automático con aplicaciones beneficiosas del mundo real.
Paul Lilly en Hardware caliente fue uno de los observadores de tecnología que notó que la forma en que pasaron de 2-D-a-3-D fue noticia. No es una gran sorpresa cuando el camino es al revés — 3-D en 2-D — pero "crear un modelo 3-D sin alimentar un sistema con datos 3-D es mucho más desafiante".
Lilly citó a Jun Gao, uno de los miembros del equipo de investigación que trabajó en el enfoque de renderizado. "Esta es esencialmente la primera vez que puede tomar casi cualquier imagen 2-D y predecir propiedades 3-D relevantes".
Su salsa mágica para producir un objeto 3-D a partir de imágenes 2-D es un "renderizador diferenciable basado en interpolación, "o DIB-R. Los investigadores de Nvidia entrenaron su modelo en conjuntos de datos que incluían imágenes de aves. Después del entrenamiento, DIB-R tenía la capacidad de tomar una imagen de pájaro y ofrecer una representación en 3-D, con la forma y textura correctas de un pájaro tridimensional.
Nvidia describió además la entrada transformada en un mapa de características o vector que se utiliza para predecir información específica como la forma, color, textura e iluminación de una imagen.
Por qué esto importa: Gizmodo El titular lo resumió. "Nvidia enseñó a una IA para generar instantáneamente modelos 3-D completamente texturizados a partir de imágenes planas 2-D". Esa palabra "instantáneamente" es importante.
DIB-R puede producir un objeto 3-D a partir de una imagen 2-D en menos de 100 milisegundos, dijo Lauren Finkle de Nvidia. "Lo hace alterando una esfera poligonal, la plantilla tradicional que representa una forma tridimensional. DIB-R la modifica para que coincida con la forma del objeto real representado en las imágenes bidimensionales".
Andrew Liszewski en Gizmodo destacó este elemento de tiempo de 100 milisegundos. "Esa impresionante velocidad de procesamiento es lo que hace que esta herramienta sea particularmente interesante porque tiene el potencial de mejorar enormemente la forma en que las máquinas, como los robots, o coches autónomos, ver el mundo, y entender lo que les espera ".
En cuanto a los coches autónomos, Liszewski dijo:"Las imágenes fijas extraídas de una transmisión de video en vivo desde una cámara podrían convertirse instantáneamente a modelos 3-D, lo que permite un automóvil autónomo, por ejemplo, para medir con precisión el tamaño de un camión grande que debe evitar ".

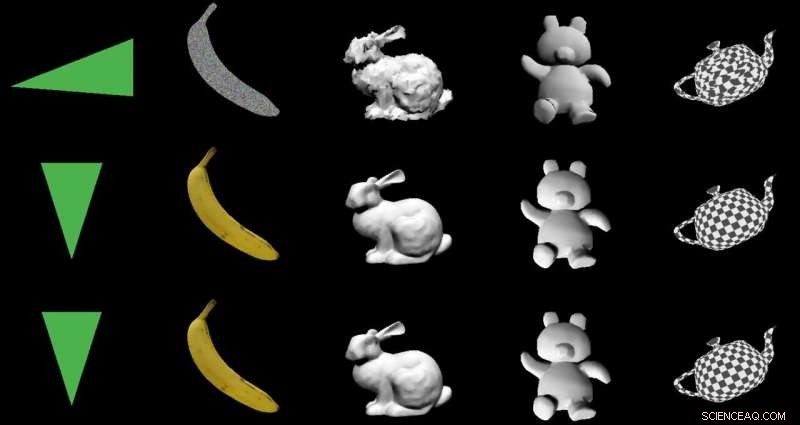
El equipo probó DIB-R en cuatro imágenes 2D de aves (extremo izquierdo). El primer experimento utilizó una imagen de una curruca amarilla (arriba a la izquierda) y produjo un objeto 3D (dos filas superiores). Crédito:Nvidia
Un modelo que pudiera inferir un objeto 3-D a partir de una imagen 2-D podría realizar un mejor seguimiento de objetos, y Lilly empezó a pensar en su uso en robótica. "Al procesar imágenes 2-D en modelos 3-D, un robot autónomo estaría en una mejor posición para interactuar con su entorno de manera más segura y eficiente, " él dijo.
Nvidia señaló que los robots autónomos, con el fin de hacerlo, "debe poder sentir y comprender su entorno. DIB-R podría mejorar potencialmente esas capacidades de percepción de profundidad".
Gizmodo Liszewski, mientras tanto, mencionó lo que el enfoque de Nvidia podría hacer por la seguridad. "DIB-R incluso podría mejorar el rendimiento de las cámaras de seguridad encargadas de identificar a las personas y rastrearlas, ya que un modelo 3D generado instantáneamente facilitaría la realización de coincidencias de imágenes a medida que una persona se mueve a través de su campo de visión ".
Los investigadores de Nvidia presentarán su modelo este mes en la Conferencia anual sobre sistemas de procesamiento de información neuronal (NeurIPS), en Vancouver.
Aquellos que quieran aprender más sobre su investigación pueden consultar su artículo sobre arXiv, "Aprender a predecir objetos 3-D con un renderizador diferenciable basado en interpolación". Los autores son Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson y Sanja Fidler.
Propusieron "un renderizador diferenciable completo basado en rasterización para el cual los gradientes se pueden calcular analíticamente". Cuando se envuelve alrededor de una red neuronal, su marco aprendió a predecir la forma, textura, y luz de imágenes individuales, ellos dijeron, y mostraron su marco "para aprender un generador de formas texturizadas 3-D".
En su resumen, los autores observaron que "muchos modelos de aprendizaje automático funcionan con imágenes, pero ignore el hecho de que las imágenes son proyecciones bidimensionales formadas por geometría tridimensional que interactúan con la luz, en un proceso llamado renderizado. Permitir que los modelos de AA comprendan la formación de imágenes puede ser clave para la generalización ".
Presentaron DIB-R como un marco que permite que los gradientes se calculen analíticamente para todos los píxeles de una imagen.
Dijeron que la clave de su enfoque era "ver la rasterización de primer plano como una interpolación ponderada de propiedades locales y la rasterización de fondo como una agregación de geometría global basada en la distancia. Nuestro enfoque permite una optimización precisa de las posiciones de los vértices, colores, normales direcciones de luz y coordenadas de textura a través de una variedad de modelos de iluminación ".
© 2019 Science X Network