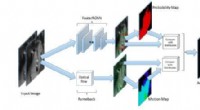
El robot recopila datos de interacción aleatoria que se utilizarán para entrenar una representación y como datos fuera de la política para RL. Crédito:Nair et al.
El aprendizaje por refuerzo (RL) ha demostrado hasta ahora ser una técnica eficaz para entrenar agentes artificiales en tareas individuales. Sin embargo, en lo que respecta a la formación de robots polivalentes, que debería poder completar una variedad de tareas que requieren diferentes habilidades, la mayoría de los enfoques de RL existentes están lejos de ser ideales.
Teniendo esto en cuenta, Un equipo de investigadores de UC Berkeley ha desarrollado recientemente un nuevo enfoque de RL que podría usarse para enseñar a los robots a adaptar su comportamiento en función de la tarea que se les presente. Este enfoque, resumido en un documento prepublicado en arXiv y presentado en la Conferencia de este año sobre el aprendizaje de robots, permite que los robots desarrollen comportamientos automáticamente y los practiquen a lo largo del tiempo, aprender cuáles se pueden realizar en un entorno determinado. Luego, los robots pueden reutilizar el conocimiento que adquirieron y aplicarlo a nuevas tareas que los usuarios humanos les piden que completen.
“Estamos convencidos de que los datos son clave para la manipulación robótica y para obtener datos suficientes para resolver la manipulación de forma general, los robots tendrán que recopilar datos por sí mismos, "Ashvin Nair, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Esto es lo que llamamos aprendizaje de robot auto-supervisado:un robot que puede recopilar activamente datos de exploración coherentes y comprender por sí mismo si ha tenido éxito o no en las tareas para aprender nuevas habilidades".
El nuevo enfoque desarrollado por Nair y sus colegas se basa en un marco de RL condicionado por objetivos presentado en su trabajo anterior. En este estudio anterior, Los investigadores introdujeron el establecimiento de objetivos en un espacio latente como una técnica para entrenar a los robots en habilidades como empujar objetos o abrir puertas directamente desde píxeles. sin la necesidad de una función de recompensa externa o estimación del estado.
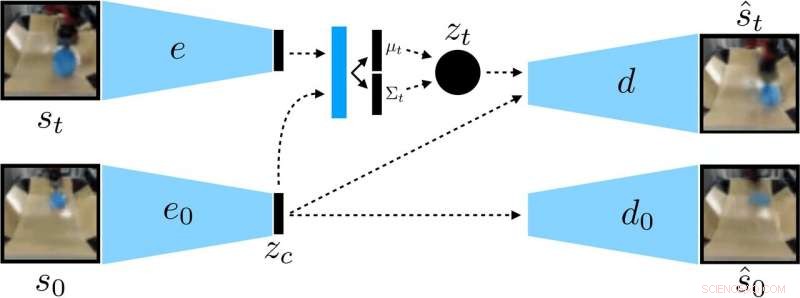
Los investigadores entrenaron un VAE condicionado por el contexto en los datos, que desenreda el contexto que permanece constante durante un lanzamiento. Crédito:Nair et al.
"En nuestro nuevo trabajo, nos enfocamos en la generalización:¿Cómo podemos hacer un aprendizaje auto-supervisado para no solo aprender una sola habilidad, pero también ser capaz de generalizar a la diversidad visual mientras se realiza esa habilidad ", dijo Nair." Creemos que la capacidad de generalizar a nuevas situaciones será clave para una mejor manipulación robótica ".
En lugar de entrenar a un robot en muchas habilidades individualmente, El modelo de establecimiento de objetivos condicional propuesto por Nair y sus colegas está diseñado para establecer objetivos específicos que sean factibles para el robot y estén alineados con su estado actual. Esencialmente, el algoritmo que desarrollaron aprende un tipo específico de representación que separa las cosas que el robot puede controlar de las cosas que no puede controlar.
Al utilizar su método de aprendizaje autodirigido, el robot inicialmente recopila datos (es decir, un conjunto de imágenes y acciones) interactuando aleatoriamente con su entorno circundante. Después, entrena una representación comprimida de estos datos que convierte imágenes en vectores de baja dimensión que contienen implícitamente información como la posición de los objetos. En lugar de que se le diga explícitamente qué aprender, esta representación comprende automáticamente los conceptos a través de su objetivo de compresión.
"Usando la representación aprendida, el robot practica el logro de diferentes objetivos y entrena una política mediante el aprendizaje por refuerzo, "Nair explicó." La representación comprimida es clave para esta fase de práctica:se utiliza para medir qué tan cerca están dos imágenes para que el robot sepa cuándo ha tenido éxito o ha fallado. y se utiliza para muestrear objetivos para que los practique el robot. En el momento de la prueba, luego puede coincidir con una imagen de objetivo especificada por un humano mediante la ejecución de su política aprendida ".
Los investigadores evaluaron la efectividad de su enfoque en una serie de experimentos en los que un agente artificial manipuló objetos nunca antes vistos en un entorno creado utilizando la plataforma de simulación MuJuCo. Curiosamente, su método de entrenamiento permitió al agente robótico adquirir habilidades automáticamente que luego podría aplicar a nuevas situaciones. Más específicamente, el robot pudo manipular una variedad de objetos, generalizar las estrategias de manipulación que adquirió previamente a nuevos objetos que no había encontrado durante el entrenamiento.
"Estamos muy entusiasmados con dos resultados de este trabajo, "Dijo Nair." Primero, descubrimos que podemos entrenar una política para insertar objetos en el mundo real en unos 20 objetos, pero la política aprendida también puede empujar a otros objetos. Este tipo de generalización es la principal promesa de los métodos de aprendizaje profundo, y esperamos que este sea el comienzo de formas de generalización mucho más impresionantes por venir ".
Notablemente, en sus experimentos, Nair y sus colegas pudieron entrenar una política a partir de un conjunto de datos fijo de interacciones sin tener que recopilar una gran cantidad de datos en línea. Este es un logro importante, dado que la recopilación de datos para la investigación en robótica suele ser muy cara, y poder aprender habilidades a partir de conjuntos de datos fijos hace que su enfoque sea mucho más práctico.
En el futuro, El modelo de aprendizaje auto-supervisado desarrollado por los investigadores podría ayudar al desarrollo de robots que puedan abordar una variedad más amplia de tareas sin tener que entrenarse en un gran conjunto de habilidades de forma individual. Mientras tanto, Nair y sus colegas planean seguir probando su enfoque en entornos simulados, al mismo tiempo que investiga formas en las que podría mejorarse aún más.
"Ahora estamos siguiendo algunas líneas de investigación diferentes, incluida la resolución de tareas con una cantidad mucho mayor de diversidad visual, además de resolver un gran conjunto de tareas simultáneamente y ver si podemos usar la solución en una tarea para acelerar la resolución de la siguiente, "Dijo Nair.
© 2019 Science X Network