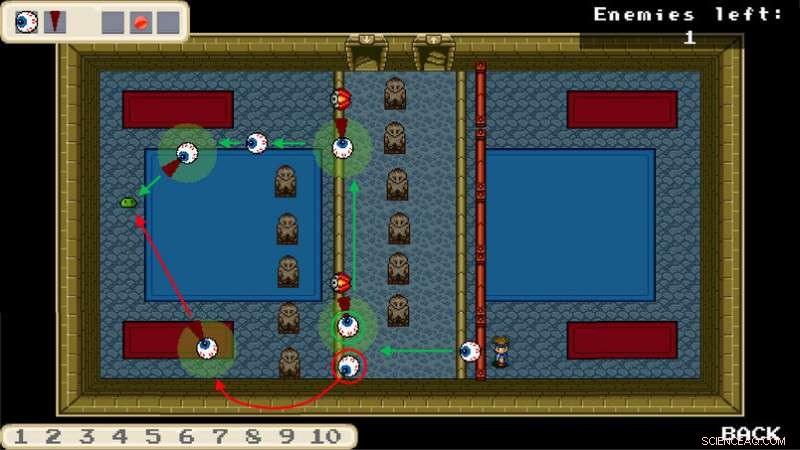
Ejemplo de un agente de aprendizaje en un juego de computadora:el personaje está controlado por un jugador humano. Los ojos son los agentes. Se supone que el jugador debe guiar a los agentes de tal manera que ejecuten una tarea, por ejemplo, sin toparse primero con un obstáculo. La formación se basa en un proceso de aprendizaje automático; todo lo que hace el jugador es esbozar unos requisitos aproximados. Crédito:RUB, Institut für Neuroinformatik
Los procesos que subyacen a la inteligencia artificial hoy en día son, de hecho, bastante tontos. Los investigadores de Bochum intentan hacerlos más inteligentes.
Cambio radical, revolución, megatendencia tal vez incluso un riesgo:la inteligencia artificial ha penetrado en todos los segmentos industriales y mantiene ocupados a los medios de comunicación. Los investigadores del Instituto RUB de Computación Neural lo han estado estudiando durante 25 años. Su principio rector es:para que las máquinas sean verdaderamente inteligentes, Los nuevos enfoques primero deben hacer que el aprendizaje automático sea más eficiente y flexible.
"Hay dos tipos de aprendizaje automático que tienen éxito en la actualidad:redes neuronales profundas, también conocido como Deep Learning, así como el aprendizaje por refuerzo, "explica el profesor Laurenz Wiskott, Cátedra de Teoría de Sistemas Neuronales.
Las redes neuronales son capaces de tomar decisiones complejas. Se utilizan con frecuencia en aplicaciones de reconocimiento de imágenes. "Ellos pueden, por ejemplo, saber a partir de las fotos si el sujeto es un hombre o una mujer, "dice Wiskott.
La arquitectura de tales redes está inspirada en redes de células nerviosas, o neuronas, en nuestro cerebro. Las neuronas reciben señales a través de varios canales de entrada y luego deciden si pasan la señal en forma de pulso eléctrico a las siguientes neuronas o no.
Las redes neuronales también reciben varias señales de entrada, por ejemplo píxeles. En un primer paso muchas neuronas artificiales calculan una señal de salida a partir de varias señales de entrada simplemente multiplicando las entradas por pesos diferentes pero constantes y luego sumándolos. Cada una de estas operaciones aritméticas da como resultado un valor que, para seguir con el ejemplo de hombre / mujer, contribuye un poco a la decisión de mujer o hombre. "El resultado está ligeramente alterado, sin embargo, estableciendo los resultados negativos en cero. Esta, también, se copia de las células nerviosas y es esencial para el funcionamiento de las redes neuronales, "explica Laurenz Wiskott.
Lo mismo vuelve a suceder en la siguiente capa, hasta que la red tome una decisión en la etapa final. Cuantas más etapas haya en el proceso, cuanto más poderosa es, las redes neuronales con más de 100 etapas no son infrecuentes. Las redes neuronales a menudo resuelven las tareas de discriminación mejor que los humanos.
El efecto de aprendizaje de tales redes se basa en la elección de los factores de ponderación correctos, que inicialmente se eligen al azar. "Para formar una red de este tipo, las señales de entrada, así como cuál debe ser la decisión final, se especifican desde el principio, ", elabora Laurenz Wiskott. Así, la red es capaz de ajustar gradualmente los factores de ponderación para finalmente tomar la decisión correcta con la mayor probabilidad.
Aprendizaje reforzado, por otra parte, está inspirado en la psicología. Aquí, cada decisión tomada por el algoritmo (los expertos se refieren a él como el agente) es recompensada o castigada. "Imagine una cuadrícula con el agente en el medio, "ilustra Laurenz Wiskott." Su objetivo es llegar al cuadro superior izquierdo por la ruta más corta posible, pero no lo sabe. "Lo único que quiere el agente es obtener tantas recompensas como sea posible, de lo contrario, no tiene ni idea. En primer lugar, se moverá por el tablero al azar, y todo paso que no llegue a la meta será castigado. Solo el paso hacia la meta resulta en una recompensa.

¿Qué ruta debe tomar el robot? Esta decisión se basa en innumerables operaciones aritméticas. Crédito:Roberto Schirdewahn
Para aprender, el agente asigna un valor a cada campo que indica cuántos pasos quedan desde esa posición hasta su objetivo. Inicialmente, estos valores son aleatorios. Cuanta más experiencia obtenga el agente en su tablero, mejor podrá adaptar estos valores a las condiciones de la vida real. Después de numerosas carreras, es capaz de encontrar el camino más rápido hacia su objetivo y, como consecuencia, a la recompensa.
"El problema con estos procesos de aprendizaje automático es que son bastante tontos, ", dice Laurenz Wiskott." Las técnicas subyacentes se remontan a la década de 1980. La única razón de su éxito actual es que hoy tenemos más capacidad informática y más datos a nuestra disposición ". Debido a esto, Es posible ejecutar rápidamente los procesos de aprendizaje virtualmente ineficientes innumerables veces y alimentar las redes neuronales con una plétora de imágenes y descripciones de imágenes para entrenarlas.
"Lo que queremos saber es:¿cómo podemos evitar tanto tiempo, entrenamiento sin sentido? Y sobre todo:¿cómo podemos hacer que el aprendizaje automático sea más flexible? ", Como lo expresa sucintamente Wiskott. La inteligencia artificial puede ser superior a los humanos exactamente en la única tarea para la que fue entrenada, pero no puede generalizar ni transferir su conocimiento a tareas relacionadas.
Es por eso que los investigadores del Instituto de Computación Neural se están enfocando en nuevas estrategias que ayuden a las máquinas a descubrir estructuras de forma autónoma. "Para tal fin, implementamos el principio de aprendizaje no supervisado, "dice Laurenz Wiskott. Si bien las redes neuronales profundas y el aprendizaje por refuerzo se basan en presentar el resultado deseado o en recompensar o castigar cada paso, los investigadores dejan los algoritmos de aprendizaje en gran parte solos con sus aportes.
"Una tarea podría ser, por ejemplo, para formar racimos, "explica Wiskott. Para ello, la computadora recibe instrucciones de agrupar datos similares. Con respecto a los puntos en un espacio tridimensional, esto significaría agrupar puntos cuyas coordenadas están próximas entre sí. Si la distancia entre las coordenadas es mayor, se asignarían a diferentes grupos.
"Volviendo al ejemplo de las fotografías de personas, uno podría mirar el resultado después de la agrupación y probablemente encontraría que la computadora ha creado un grupo con imágenes de hombres y un grupo con imágenes de mujeres, "elabora Laurenz Wiskott." Una gran ventaja es que todo lo que se requiere al principio son fotos, en lugar de un título de imagen que contenga la solución al acertijo con fines de capacitación, como si fuera."
El principio de lentitud
Es más, este método ofrece más flexibilidad, porque tal formación de grupos es aplicable no solo para imágenes de personas, pero también para los de los coches, plantas casas u otros objetos.
Otro enfoque seguido por Wiskott es el principio de lentitud. Aquí, no son las fotos las que constituyen la señal de entrada, pero imágenes en movimiento:si todas las funciones se extraen de un video que cambia muy lentamente, Surgen estructuras que ayudan a construir una representación abstracta del medio ambiente. "Aquí, también, el punto es preestructurar los datos de entrada, ", señala Laurenz Wiskott. Finalmente, los investigadores combinan estos enfoques de forma modular con los métodos de aprendizaje supervisado, para crear aplicaciones más flexibles y, sin embargo, muy precisas.
"El aumento de la flexibilidad resulta naturalmente en una pérdida de rendimiento, "admite el investigador. Pero a la larga, la flexibilidad es indispensable si queremos desarrollar robots que puedan manejar nuevas situaciones ".