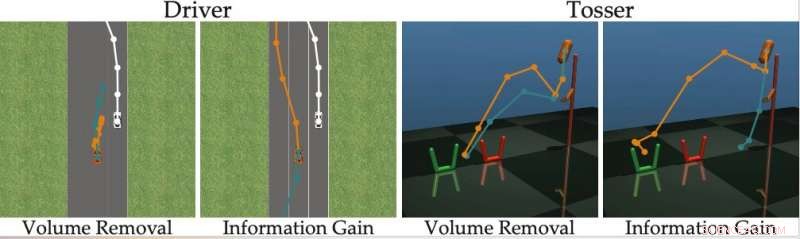
Crédito:Bıyık et al.
En años recientes, Los investigadores han estado tratando de desarrollar métodos que permitan a los robots aprender nuevas habilidades. Una opción es que un robot aprenda estas nuevas habilidades de los humanos, hacer preguntas siempre que no esté seguro de cómo comportarse, y aprender de las respuestas del usuario humano.
Un equipo de investigación de la Universidad de Stanford desarrolló recientemente un enfoque fácil de usar para el aprendizaje de recompensas activas que se puede utilizar para entrenar robots haciendo que los usuarios humanos respondan sus preguntas. Este nuevo enfoque, presentado en un artículo prepublicado en arXiv, entrena a los robots para que hagan preguntas que serán fáciles de responder para un usuario humano y que no son redundantes ni innecesarias.
"Nuestro grupo está interesado en cómo los robots pueden aprender lo que quieren los humanos, ", dijeron los investigadores a TechXplore por correo electrónico." Una forma intuitiva de aprender es haciendo preguntas. Por ejemplo, ¿Prefieres que un coche autónomo conduzca con cautela o agresividad? ¿Debería este automóvil autónomo fusionarse delante o detrás de un automóvil conducido por humanos? "
La suposición principal detrás del estudio reciente es que, idealmente, los robots deben hacer preguntas informativas que obtengan la mayor cantidad de información posible de los usuarios humanos. En otras palabras, un robot debe poder comprender lo que un ser humano necesita o quiere que haga haciendo la menor cantidad de preguntas posible.
En realidad, sin embargo, La mayoría de los enfoques de capacitación existentes basados en la respuesta a preguntas no consideran lo fácil que será para los usuarios humanos responder preguntas específicas formuladas por el robot. Esto a menudo hace que los usuarios pierdan el tiempo respondiendo un montón de preguntas innecesarias o no puedan responder con certeza.
"Descubrimos que la mayoría de los algoritmos de vanguardia muestran las alternativas humanas que son (casi) indistinguibles, impidiendo que la persona responda correctamente a las preguntas del robot, ", dijeron los investigadores." Volviendo a nuestro ejemplo, estos enfoques podrían preguntar:"¿Preferirías fusionarte frente al automóvil conducido por humanos a una velocidad de 29 mph, o una velocidad de 50 km / h? "Esto puede ser informativo para que el robot decida si el humano quiere ir más rápido de 50 km / h o no, pero las opciones están tan cerca que los humanos no pueden responder de manera confiable ".
Para superar las limitaciones de los métodos de aprendizaje activo existentes, los investigadores desarrollaron un algoritmo que puede seleccionar preguntas más efectivas para hacer a los usuarios humanos. El algoritmo identifica las preguntas que más reducen la incertidumbre del robot sobre las preferencias de un usuario humano (es decir, que maximizan la ganancia de información), al mismo tiempo que considera lo fácil que será para un usuario humano responderlas.

Crédito:Bıyık et al.
"Inspirado por las deficiencias de trabajos anteriores, cuando desarrollamos este algoritmo, nos centramos en tener en cuenta la capacidad del ser humano para responder realmente las preguntas que hace el robot, ", dijeron los investigadores. Esto se basa en la idea de que solo los robots que dan cuenta de la capacidad del ser humano para responder pueden aprender de manera precisa y eficiente lo que quieren los humanos".
Los investigadores calcularon la ganancia de información midiendo la disminución de la entropía (es decir, una medida de incertidumbre) sobre las preferencias del usuario humano en función de la pregunta formulada por el robot. En otras palabras, una pregunta que maximice la obtención de información reducirá al máximo la incertidumbre del robot sobre cuáles son las preferencias del usuario humano. Esto le da a los robots un objetivo formal que pueden usar para seleccionar las preguntas más informativas.
"Una buena característica de la obtención de información es que maximiza inherentemente la incertidumbre del robot (de modo que el robot aprende mucho de la pregunta) al mismo tiempo que minimiza la incertidumbre del ser humano (de modo que la pregunta sea fácil de responder), "explicaron los investigadores." Generar las preguntas utilizando la ganancia de información mejora así el aprendizaje activo, no solo porque las preguntas son sumamente informativas, pero también porque el humano da menos respuestas erróneas ".
El enfoque ideado por los investigadores selecciona con avidez la pregunta que maximiza la obtención de información en cada paso del tiempo. Esencialmente, el robot mantiene una creencia (es decir, una distribución de probabilidad) sobre las preferencias del usuario con el que está interactuando y muestras tanto de esta creencia como del espacio de posibles preguntas.
Por último, el robot elige la pregunta que proporciona la mayor ganancia de información en la distribución actual de las posibles preferencias humanas. Después, actualiza sus creencias sobre lo que quiere el usuario en función de la respuesta que recibe. Este proceso se repite continuamente, permitiendo que el robot mejore gradualmente su rendimiento al conocer las preferencias del usuario.
"Formulamos un método computacionalmente manejable que nos permite descubrir rápidamente las preferencias humanas en tareas robóticas reales, superando a los métodos anteriores, ", dijeron los investigadores." En nuestro estudio, los usuarios preferían nuestro método a otras técnicas de vanguardia ".
En su estudio, El equipo de Stanford demostró que entrenar a un robot para que haga preguntas que maximicen la ganancia de información tiene la misma complejidad computacional que los métodos de vanguardia. En otras palabras, no es más difícil para el robot encontrar estas preguntas informativas, en comparación con los generados por otros enfoques.
"También señalamos que nuestro enfoque tiene varias propiedades matemáticas deseables, como la submodularidad, lo que nos permite tomar las extensiones y los límites teóricos que fueron desarrollados para enfoques anteriores y también usarlos con nuestro método, ", dijeron los investigadores." Por ejemplo, podemos utilizar trabajos anteriores para encontrar varias preguntas informativas a la vez, en lugar de buscar una pregunta a la vez ".
El equipo evaluó su enfoque activo de aprendizaje por recompensa en una serie de simulaciones y descubrió que permite a los robots captar las preferencias humanas de forma más rápida y precisa que otros métodos de vanguardia. También se descubrió que esto es cierto en situaciones en las que los humanos pueden responder correctamente preguntas difíciles o cuando su respuesta es "No sé".
Los investigadores también llevaron a cabo un estudio de usuarios en el que pidieron a los participantes humanos que respondieran preguntas generadas por su método y otras generadas utilizando otros enfoques de vanguardia. The feedback they collected suggests that people find questions generated by their approach far easier to answer. Además, users often felt that robots using the new method had acquired a more accurate representation of their preferences than they did with previously proposed approaches.
"Considering all of our contributions together, we took a step toward enabling robots to determine human preferences, " the researchers said. "We showed that the true objective that we originally wanted the robot to maximize—-asking questions to gain as much information as possible—-can actually be solved with the same computational complexity as existing methods."
In the future, the active reward-learning technique developed by this team of researchers could help to train robots more effectively, making them more attuned to user preferences. Además, it could be used to teach robots to ask questions that humans can easily understand and answer. In their future studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
"We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively."
© 2019 Science X Network