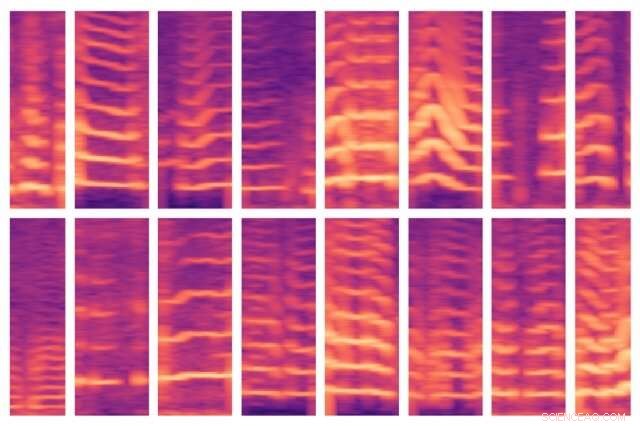
Un nuevo modelo desarrollado por el MIT automatiza un paso crítico en el uso de IA para la toma de decisiones médicas, donde los expertos suelen identificar a mano características importantes en conjuntos de datos de pacientes masivos. El modelo pudo identificar automáticamente los patrones de voz de las personas con nódulos en las cuerdas vocales (que se muestra aquí) y, Sucesivamente, utilice esas funciones para predecir qué personas tienen y no padecen el trastorno. Crédito:Instituto de Tecnología de Massachusetts
Los científicos informáticos del MIT esperan acelerar el uso de la inteligencia artificial para mejorar la toma de decisiones médicas. automatizando un paso clave que generalmente se realiza a mano, y que se vuelve más laborioso a medida que ciertos conjuntos de datos crecen cada vez más.
El campo de la analítica predictiva es cada vez más prometedor para ayudar a los médicos a diagnosticar y tratar a los pacientes. Los modelos de aprendizaje automático se pueden entrenar para encontrar patrones en los datos del paciente para ayudar en el cuidado de la sepsis, diseñar regímenes de quimioterapia más seguros, y predecir el riesgo de una paciente de tener cáncer de mama o morir en la UCI, por nombrar solo algunos ejemplos.
Típicamente, Los conjuntos de datos de entrenamiento consisten en muchos sujetos sanos y enfermos, pero con relativamente pocos datos para cada tema. Luego, los expertos deben encontrar en los conjuntos de datos solo aquellos aspectos, o "características", que serán importantes para hacer predicciones.
Esta "ingeniería de características" puede ser un proceso laborioso y costoso. Pero se está volviendo aún más desafiante con el aumento de los sensores portátiles, porque los investigadores pueden monitorear más fácilmente la biometría de los pacientes durante períodos prolongados, seguimiento de los patrones de sueño, paso, y actividad de voz, por ejemplo. Después de solo una semana de seguimiento, los expertos podrían tener varios miles de millones de muestras de datos para cada tema.
En un artículo que se presenta en la conferencia Machine Learning for Healthcare de esta semana, Los investigadores del MIT demuestran un modelo que aprende automáticamente las características que predicen los trastornos de las cuerdas vocales. Las características provienen de un conjunto de datos de aproximadamente 100 sujetos, cada uno con aproximadamente una semana de datos de monitoreo de voz y varios miles de millones de muestras; en otras palabras, un pequeño número de temas y una gran cantidad de datos por tema. El conjunto de datos contiene señales capturadas de un pequeño sensor de acelerómetro montado en el cuello de los sujetos.
En experimentos, el modelo utilizó características extraídas automáticamente de estos datos para clasificar, con alta precisión, pacientes con y sin nódulos en las cuerdas vocales. Estas son lesiones que se desarrollan en la laringe, a menudo debido a patrones de uso indebido de la voz, como gritar o gritar. En tono rimbombante, el modelo logró esta tarea sin un gran conjunto de datos etiquetados a mano.
"Se está volviendo cada vez más fácil recopilar conjuntos de datos de series de tiempo largas. Pero hay médicos que necesitan aplicar sus conocimientos para etiquetar el conjunto de datos, "dice el autor principal, José Javier González Ortiz, un doctorado estudiante del Laboratorio de Informática e Inteligencia Artificial del MIT (CSAIL). "Queremos eliminar esa parte del manual para los expertos y descargar toda la ingeniería de funciones a un modelo de aprendizaje automático".
El modelo se puede adaptar para aprender patrones de cualquier enfermedad o condición. Pero la capacidad de detectar los patrones de uso diario de la voz asociados con los nódulos de las cuerdas vocales es un paso importante en el desarrollo de métodos mejorados para prevenir, diagnosticar, y tratar el trastorno, dicen los investigadores. Eso podría incluir el diseño de nuevas formas de identificar y alertar a las personas sobre comportamientos vocales potencialmente dañinos.
Junto a González Ortiz en el periódico está John Guttag, el profesor Dugald C. Jackson de Ciencias de la Computación e Ingeniería Eléctrica y director del Grupo de Inferencia Conducida por Datos de CSAIL; Robert Hillman, Jarrad Van Stan, y Daryush Mehta, todo el Centro de Cirugía de Laringe y Rehabilitación de la Voz del Hospital General de Massachusetts; y Marzyeh Ghassemi, profesor asistente de ciencias de la computación y medicina en la Universidad de Toronto.
Aprendizaje forzoso de funciones
Durante años, Los investigadores del MIT han trabajado con el Centro de Cirugía Laríngea y Rehabilitación de la Voz para desarrollar y analizar datos de un sensor para rastrear el uso de la voz del sujeto durante todas las horas de vigilia. El sensor es un acelerómetro con un nodo que se adhiere al cuello y está conectado a un teléfono inteligente. Mientras la persona habla, el teléfono inteligente recopila datos de los desplazamientos en el acelerómetro.
En su trabajo, los investigadores recopilaron el valor de una semana de estos datos, llamados datos de "series de tiempo", de 104 sujetos, la mitad de los cuales fueron diagnosticados con nódulos en las cuerdas vocales. Para cada paciente, también hubo un control de coincidencia, es decir, un sujeto sano de edad similar, sexo, ocupación, y otros factores.
Tradicionalmente, los expertos tendrían que identificar manualmente las características que pueden ser útiles para que un modelo detecte diversas enfermedades o afecciones. Eso ayuda a prevenir un problema común de aprendizaje automático en el cuidado de la salud:el sobreajuste. Es cuando, entrenando, un modelo "memoriza" los datos del sujeto en lugar de aprender solo las características clínicamente relevantes. En prueba, esos modelos a menudo no logran discernir patrones similares en sujetos nunca antes vistos.
"En lugar de aprender características que son clínicamente significativas, un modelo ve patrones y dice, "Esta es Sarah, y sé que Sarah está sana y este es Peter, que tiene un nódulo en las cuerdas vocales ". es solo memorizar patrones de sujetos. Luego, cuando ve datos de Andrew, que tiene un nuevo patrón de uso vocal, no puede averiguar si esos patrones coinciden con una clasificación, "Dice González Ortiz.
El principal desafío, luego, estaba evitando el sobreajuste al tiempo que automatizaba la ingeniería de funciones manual. Con ese fin, los investigadores obligaron al modelo a aprender características sin información del sujeto. Por su tarea, eso significó capturar todos los momentos en los que los sujetos hablan y la intensidad de sus voces.
A medida que su modelo rastrea los datos de un sujeto, está programado para localizar segmentos de voz, que comprenden solo aproximadamente el 10 por ciento de los datos. Para cada una de estas ventanas de voz, el modelo calcula un espectrograma, una representación visual del espectro de frecuencias que varía con el tiempo, que se utiliza a menudo para tareas de procesamiento del habla. Luego, los espectrogramas se almacenan como grandes matrices de miles de valores.
Pero esas matrices son enormes y difíciles de procesar. Entonces, un autocodificador, una red neuronal optimizada para generar codificaciones de datos eficientes a partir de grandes cantidades de datos, primero comprime el espectrograma en una codificación de 30 valores. Luego descomprime esa codificación en un espectrograma separado.
Básicamente, el modelo debe asegurar que el espectrograma descomprimido se parezca mucho a la entrada del espectrograma original. Al hacerlo, se ve obligado a aprender la representación comprimida de cada entrada de segmento del espectrograma sobre los datos completos de la serie temporal de cada sujeto. Las representaciones comprimidas son las características que ayudan a entrenar modelos de aprendizaje automático para hacer predicciones.
Mapeo de características normales y anormales
Entrenando, el modelo aprende a asignar esas características a "pacientes" o "controles". Los pacientes tendrán más patrones de voz que los controles. Al realizar pruebas en sujetos nunca antes vistos, De manera similar, el modelo condensa todos los segmentos del espectrograma en un conjunto reducido de características. Luego, sus reglas de mayoría:si el sujeto tiene segmentos de voz en su mayoría anormales, están clasificados como pacientes; si tienen en su mayoría normales, están clasificados como controles.
En experimentos, el modelo funcionó con tanta precisión como los modelos de última generación que requieren ingeniería de características manual. En tono rimbombante, el modelo de los investigadores funcionó con precisión tanto en el entrenamiento como en las pruebas, indicando que está aprendiendo patrones clínicamente relevantes de los datos, no información específica del tema.
Próximo, los investigadores quieren monitorear cómo varios tratamientos, como la cirugía y la terapia vocal, impactan el comportamiento vocal. Si los comportamientos de los pacientes pasan de anormales a normales con el tiempo, lo más probable es que estén mejorando. También esperan utilizar una técnica similar en los datos del electrocardiograma, que se utiliza para rastrear las funciones musculares del corazón.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.