Un algoritmo simplemente sigue reglas diseñadas directa o indirectamente por un ser humano. Crédito:Shutterstock / Billion Photos
El papel de los algoritmos en nuestras vidas está creciendo rápidamente, simplemente sugiriendo resultados de búsqueda en línea o contenido en nuestro feed de redes sociales, a asuntos más críticos como ayudar a los médicos a determinar nuestro riesgo de cáncer.
Pero, ¿cómo sabemos que podemos confiar en la decisión de un algoritmo? En junio, casi 100 conductores en los Estados Unidos aprendieron por las malas que a veces los algoritmos pueden equivocarse mucho.
Google Maps los dejó a todos atascados en una carretera privada embarrada en un desvío fallido para escapar de un atasco de tráfico que se dirigía al Aeropuerto Internacional de Denver. En colorado.
A medida que nuestra sociedad se vuelve cada vez más dependiente de los algoritmos para el asesoramiento y la toma de decisiones, se está volviendo urgente abordar la espinosa cuestión de cómo podemos confiar en ellos.
Los algoritmos son acusados regularmente de sesgo y discriminación. Han despertado la preocupación de los políticos estadounidenses, En medio de afirmaciones, tenemos hombres blancos que desarrollan algoritmos de reconocimiento facial entrenados para funcionar bien solo para hombres blancos.
Pero los algoritmos no son más que programas de computadora que toman decisiones basadas en reglas:reglas que les dimos, o reglas que ellos mismos resolvieron basándose en ejemplos que les dimos.
En ambos casos, los humanos controlan estos algoritmos y cómo se comportan. Si un algoritmo tiene fallas, es obra nuestra.
Entonces, antes de que todos terminemos en un embotellamiento fangoso metafórico (¡o literal!), Existe una necesidad urgente de revisar cómo los humanos elegimos poner a prueba esas reglas y ganar confianza en los algoritmos.
Algoritmos puestos a prueba, mas o menos
Los humanos son criaturas sospechosas por naturaleza, pero la mayoría de nosotros puede ser convencido por la evidencia.
Con suficientes ejemplos de prueba, con respuestas correctas conocidas, desarrollamos confianza si un algoritmo da la respuesta correcta de manera consistente, y no solo para los ejemplos fáciles y obvios, sino también para los desafiantes, ejemplos realistas y diversos. Entonces podemos estar convencidos de que el algoritmo es imparcial y confiable.
Suena bastante fácil ¿Derecha? Pero, ¿es así como se prueban habitualmente los algoritmos? Es más difícil de lo que parece asegurarse de que los ejemplos de prueba sean imparciales y representativos de todos los escenarios posibles que podrían encontrarse.
Mas comunmente, Se utilizan ejemplos de referencia bien estudiados porque están fácilmente disponibles en los sitios web. (Microsoft tenía una base de datos de rostros de celebridades para probar algoritmos de reconocimiento facial, pero recientemente se eliminó debido a problemas de privacidad).
La comparación de algoritmos también es más fácil cuando se prueba en puntos de referencia compartidos, pero estos ejemplos de prueba rara vez se analizan por sus sesgos. Peor aún, el rendimiento de los algoritmos generalmente se informa en promedio a través de los ejemplos de prueba.
Desafortunadamente, saber que un algoritmo funciona bien en promedio no nos dice nada sobre si podemos confiar en él en casos específicos.
No es sorprendente leer que los médicos se muestran escépticos sobre el algoritmo de Google para el diagnóstico de cáncer, que ofrece un 89% de precisión en promedio. ¿Cómo sabe un médico si su paciente es uno del 11% desafortunado con un diagnóstico incorrecto?
Con la creciente demanda de medicina personalizada adaptada al individuo (no solo el promedio de Sr. / Sra.), y con promedios conocidos por ocultar todo tipo de pecados, los resultados promedio no ganarán la confianza humana.
La necesidad de nuevos protocolos de prueba.
Claramente, no es lo suficientemente riguroso para probar un montón de ejemplos (puntos de referencia bien estudiados o no) sin demostrar que son imparciales, y luego sacar conclusiones sobre la confiabilidad de un algoritmo en promedio.
Y, sin embargo, paradójicamente, este es el enfoque del que dependen los laboratorios de investigación de todo el mundo para flexionar sus músculos algorítmicos. El proceso académico de revisión por pares refuerza estos procedimientos de evaluación heredados y rara vez cuestionados.
Un nuevo algoritmo se puede publicar si es mejor en promedio que los algoritmos existentes en ejemplos de referencia bien estudiados. Si no es competitivo de esta manera, está oculto para un mayor escrutinio de revisión por pares, o se presentan nuevos ejemplos para los que el algoritmo parece útil.
De este modo, un calor, se ilumina una luz halagadora sobre cada algoritmo recién publicado, con poco intento de poner a prueba sus fortalezas y debilidades, y presentarlo con verrugas y todo. Es la versión informática de los investigadores médicos que no publican los resultados completos de los ensayos clínicos.
A medida que la confianza algorítmica se vuelve más crucial, Necesitamos urgentemente actualizar esta metodología para analizar si los ejemplos de prueba elegidos son adecuados para su propósito. Hasta aquí, los investigadores se han visto impedidos de realizar análisis más rigurosos por la falta de herramientas adecuadas.
Hemos construido una mejor prueba de esfuerzo
Después de más de una década de investigación, mi equipo ha lanzado una nueva herramienta de análisis de algoritmos en línea llamada MATILDA:Biblioteca de instancias de prueba de algoritmos de Melbourne con análisis de datos.
Ayuda a los algoritmos de prueba de esfuerzo de manera más rigurosa al crear visualizaciones poderosas de un problema, mostrando todos los escenarios o ejemplos que un algoritmo debería considerar para realizar pruebas exhaustivas.
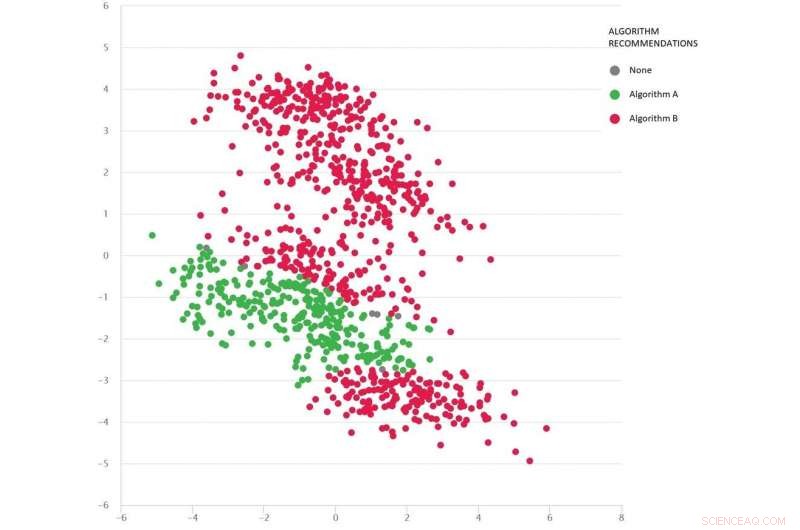
Un problema tipo Google Maps con diversos escenarios de prueba como puntos:el algoritmo B (rojo) es el mejor en promedio, pero el algoritmo A (verde) es mejor en muchos casos. Crédito:MATILDA, Autor proporcionado
MATILDA identifica las fortalezas y debilidades únicas de cada algoritmo, recomendar cuál de los algoritmos disponibles utilizar en diferentes escenarios y por qué.
Por ejemplo, si la lluvia reciente ha convertido en barro las carreteras sin asfaltar, Algunos algoritmos de "ruta más corta" pueden no ser confiables a menos que puedan anticipar el impacto probable del clima en los tiempos de viaje al recomendar la ruta más rápida. A menos que los desarrolladores prueben tales escenarios, nunca sabrán acerca de tales debilidades hasta que sea demasiado tarde y estemos atrapados en el barro.
MATILDA nos ayuda a ver la diversidad y amplitud de los puntos de referencia, y donde se deberían diseñar nuevos ejemplos de prueba para llenar cada rincón del espacio posible en el que se le podría pedir que opere el algoritmo.
La siguiente imagen muestra un conjunto diverso de escenarios (puntos) para un tipo de problema de Google Maps. Cada escenario varía las condiciones, como las ubicaciones de origen y destino, la red de carreteras disponible, las condiciones climáticas, los tiempos de viaje en varias carreteras, y toda esta información se captura matemáticamente y se resume en las coordenadas bidimensionales de cada escenario en el espacio.
Se comparan dos algoritmos (rojo y verde) para ver cuál puede encontrar la ruta más corta. Se ha demostrado que cada algoritmo es el mejor (o se demuestra que no es confiable) en diferentes regiones, dependiendo de cómo se desempeñe en estos escenarios probados.
También podemos adivinar qué algoritmo es probable que sea mejor para los escenarios faltantes (brechas) que aún no hemos probado.
Las matemáticas detrás de MATILDA ayudan a crear esta visualización, analizando los datos de confiabilidad del algoritmo de escenarios de prueba, y encontrar una forma de ver los patrones fácilmente.
Los conocimientos y las explicaciones significan que podemos elegir el mejor algoritmo para el problema en cuestión, en lugar de cruzar los dedos y esperar que podamos confiar en el algoritmo que funciona mejor en promedio.
Al probar rigurosamente los algoritmos de esta manera, con verrugas y todo, deberíamos reducir el riesgo de decisiones erróneas de algoritmos, asegurar la confianza del Sr. / Sra. Promedio, y quizás incluso los humanos más escépticos.
Este artículo se ha vuelto a publicar de The Conversation con una licencia de Creative Commons. Lea el artículo original.