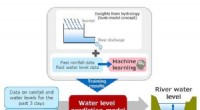
Página de una versión francesa del "Narrenschiff" (Barco de los tontos). Estas fuentes antiguas se pueden convertir de manera confiable en texto legible por computadora con OCR4all. Crédito:Biblioteca Estatal y Universitaria de Dresde, CC BY-SA 4.0
Los historiadores y los estudiosos de otras humanidades a menudo tienen que lidiar con objetos de investigación difíciles:obras impresas centenarias que son difíciles de descifrar y, a menudo, en un estado de conservación insatisfactorio. Muchos de estos documentos ahora se han digitalizado, generalmente fotografiados o escaneados, y están disponibles en línea en todo el mundo. Para fines de investigacion, esto ya es un paso adelante.
Sin embargo, Todavía hay un desafío que superar:llevar las fuentes antiguas digitalizadas a una forma moderna con un software de reconocimiento de texto que sea legible tanto para los no especialistas como para las computadoras. Científicos del Centro de Filología y Digitalidad de Julius-Maximilians-Universität Würzburg (JMU) en Baviera, Alemania, han hecho una contribución significativa a un mayor desarrollo en este campo.
Con OCR4all, el equipo de investigación de JMU está poniendo a disposición de la comunidad científica una nueva herramienta. Convierte impresiones históricas digitalizadas con una tasa de error inferior al uno por ciento en textos legibles por computadora. Y ofrece una interfaz gráfica de usuario que no requiere experiencia en TI. Con herramientas anteriores de este tipo, la facilidad de uso no siempre fue un hecho, ya que la mayoría de los usuarios tenían que trabajar con comandos de programación.
Desarrollado en cooperación con las humanidades.
La nueva herramienta OCR4all fue desarrollada bajo la dirección de Christian Reul junto con sus colegas de ciencias de la computación, el profesor Frank Puppe (presidente de Inteligencia Artificial e Informática Aplicada) y Christoph Wick, así como Uwe Springmann (experto en Humanidades Digitales) y numerosos estudiantes y asistentes.
OCR4all se origina en el proyecto JMU Kallimachos, que está financiado por el Ministerio Federal de Educación e Investigación de Alemania. Esta cooperación entre las humanidades y las ciencias de la computación continuará e institucionalizará en el recién fundado Centro JMU de Filología y Digitalidad.
Al desarrollar OCR4all, Los informáticos han colaborado con las humanidades en JMU, incluidos los estudios de literatura y estudios alemanes y romances en el proyecto "Narragonien digital". El objetivo era digitalizar el "Narrenschiff, "una sátira moral de Sebastian Brant, un bestseller del siglo XV que fue traducido a muchos idiomas. Es más, OCR4all se ha utilizado con frecuencia en Kolleg "Tiempos medievales y modernos tempranos" de la JMU.
OCR4all está disponible gratuitamente para el público en la plataforma GitHub (con instrucciones y ejemplos):https://github.com/OCR4all
Cada imprenta tenía su propia fuente
Christian Reul explica los desafíos involucrados en el desarrollo de OCR4all:El reconocimiento automático de texto (OCR =reconocimiento óptico de caracteres) ha estado funcionando muy bien para las fuentes modernas desde hace algún tiempo. Sin embargo, este no ha sido aún el caso de las fuentes históricas.
"Uno de los mayores problemas fue la tipografía, "dice Reul. Una de las razones de esto es que las primeras imprentas del siglo XV no usaban fuentes uniformes". Sus sellos de impresión fueron todos tallados por ellos mismos, cada imprenta tenía prácticamente sus propias letras ".
Tasas de error por debajo del uno por ciento
Ya sea "e" o "c, "ya sea" v "o" r ", a menudo no es fácil de distinguir en impresiones antiguas, pero el software puede aprender a reconocer tales sutilezas. Para hacerlo tiene que ser entrenado en material de muestra. En su trabajo, Reul ha desarrollado métodos para hacer que la formación sea más eficiente. En un estudio de caso con seis grabados históricos de los años 1476 a 1572, la tasa de error promedio en el reconocimiento automático de texto se redujo de 3.9 a 1.7 por ciento.
No solo se mejoró la metodología, El científico informático de JMU, Christoph Wick, también ha perfeccionado de forma decisiva el componente técnico mediante el desarrollo de la herramienta Calamari OCR. que también está disponible gratuitamente y desde entonces se ha integrado completamente en OCR4all, prometiendo resultados aún mejores. Ahora, incluso para las obras impresas más antiguas, En general, se pueden lograr tasas de error inferiores al uno por ciento.
Proyectos léxicos
Reul también ha convencido a socios externos de la calidad de la investigación OCR de Würzburg. En cooperación con el "Zentrum für digitale Lexikographie der deutschen Sprache" (Berlín), El "Wörterbuch der deutschen Sprache" (Diccionario de la lengua alemana) de Daniel Sanders ha sido indexado digitalmente, y actualmente se está preparando una publicación científica sobre este trabajo. Las distintas líneas de este texto suelen contener fuentes diferentes, que representa información semántica diferente. Aquí, El enfoque existente para el reconocimiento de caracteres se amplió de tal manera que no solo el texto, sino también la tipografía y, por lo tanto, la compleja estructura de contenido del léxico, se pueden reproducir con mucha precisión.
El informático de Würzburg pronto completará su tesis doctoral, pero también está dispuesto a seguir trabajando con OCR en el futuro:"La informática detrás de OCR es extremadamente emocionante, ", dice. Un posible proyecto en un futuro próximo:los creadores del" Idiotikon, "un diccionario de la lengua suizo-alemana, han manifestado su interés en la colaboración, ya que es posible que necesiten los conocimientos especializados de Würzburg.