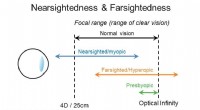
(a) El proceso de aprendizaje utilizando la plasticidad sináptica retardada, y (b) el proceso de aprendizaje optimizando los parámetros de las RNN utilizando el algoritmo de escalada. Crédito:Yaman et al.
El cerebro humano cambia continuamente con el tiempo, formando nuevas conexiones sinápticas basadas en experiencias e información aprendidas a lo largo de la vida. En los ultimos años, Los investigadores de inteligencia artificial (IA) han intentado reproducir esta fascinante capacidad, conocido como 'plasticidad, 'en redes neuronales artificiales (ANN).
Investigadores de la Universidad Tecnológica de Eindhoven (Tu / e) y la Universidad de Trento han propuesto recientemente un nuevo enfoque inspirado en mecanismos biológicos que podrían mejorar el aprendizaje en las RNA. Su estudio, descrito en un artículo publicado previamente en arXiv, fue financiado por el programa de investigación e innovación Horizonte 2020 de la Unión Europea.
"Una de las propiedades fascinantes de las redes neuronales biológicas (BNN) es su plasticidad, lo que les permite aprender cambiando su configuración en función de la experiencia, "Anil Yaman, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Según el conocimiento fisiológico actual, estos cambios se realizan en sinapsis individuales basadas en las interacciones locales de las neuronas. Sin embargo, el surgimiento de un comportamiento de aprendizaje global coherente a partir de estas interacciones individuales no se comprende muy bien ".
Inspirado en la plasticidad de los BNN y su proceso evolutivo, Yaman y sus colegas querían imitar mecanismos de aprendizaje biológicamente plausibles en sistemas artificiales. Para modelar la plasticidad en las RNA, Los investigadores suelen utilizar algo llamado reglas de aprendizaje hebbianas, que son reglas que actualizan las sinapsis basadas en activaciones neuronales y señales de refuerzo recibidas del entorno.

Varias ejecuciones independientes de los procesos de aprendizaje mediante el uso de varias reglas de plasticidad sináptica retardada evolucionadas (la mejor regla de DSP se muestra en verde). Crédito:Yaman et al.
Cuando las señales de refuerzo no están disponibles inmediatamente después de cada salida de red, sin embargo, pueden surgir algunos problemas, dificultando que la red asocie las activaciones neuronales relevantes con la señal de refuerzo. Para superar este problema, conocido como el 'problema de recompensa distal, Los investigadores ampliaron las reglas de plasticidad de Hebb para permitir el aprendizaje en casos de recompensa distal. Su enfoque llamada plasticidad sináptica retardada (DSP), utiliza algo llamado rastros de activación neuronal (NAT) para proporcionar almacenamiento adicional en cada sinapsis, así como para realizar un seguimiento de las activaciones de neuronas a medida que la red realiza una determinada tarea.
"Las reglas de plasticidad sináptica se basan en las activaciones locales de las neuronas y una señal de refuerzo, "Yaman explicó." Sin embargo, en la mayoría de los problemas de aprendizaje, las señales de refuerzo se reciben después de un cierto período de tiempo y no inmediatamente después de cada acción de la red. En este caso, se vuelve problemático asociar las señales de refuerzo con las activaciones de neuronas. En este trabajo, propusimos usar lo que llamamos 'rastros de activación neuronal, 'para almacenar las estadísticas de activaciones de neuronas en cada sinapsis e informar las reglas de plasticidad sináptica sobre cómo realizar cambios sinápticos retardados ".
Uno de los aspectos más significativos del enfoque ideado por Yaman y sus colegas es que no asume información global sobre el problema que la red neuronal estará resolviendo. Es más, no depende de la arquitectura ANN específica y, por lo tanto, es altamente generalizable.
"En terminos practicos, Nuestro estudio puede sentar las bases de nuevos esquemas de aprendizaje que se pueden utilizar en una serie de aplicaciones de redes neuronales. como robótica y vehículos autónomos, y en general en todos los casos en los que un agente tiene que realizar un comportamiento adaptativo en ausencia de una recompensa inmediata obtenida de sus acciones, "Giovanni Iacca, otro investigador involucrado en el estudio, dijo a TechXplore. "Por ejemplo, en IA para videojuegos, una acción en el intervalo de tiempo actual puede no conducir necesariamente a una recompensa en este momento, pero solo después de algún tiempo; un agente que muestra anuncios personalizados puede obtener una "recompensa" por el comportamiento del usuario solo después de un tiempo, etc.) ".
Varias ejecuciones independientes de los procesos de aprendizaje mediante la optimización de los parámetros de las RNN mediante el algoritmo de escalada. Crédito:Yaman et al.
Los investigadores probaron sus reglas de plasticidad de Hebbian recientemente adaptadas en una simulación de un entorno de laberinto en T triple. En este entorno, un agente controlado por una simple red neuronal recurrente (RNN) necesita aprender a encontrar una de las ocho posibles posiciones de objetivo, a partir de una configuración de red aleatoria.
Yaman, Iacca y sus colegas compararon el desempeño logrado usando su enfoque con el logrado cuando un agente fue entrenado usando un algoritmo de búsqueda local iterativo análogo, llamado escalada de colinas (HC). La diferencia clave entre el algoritmo de escalada de HC y su enfoque es que el primero no utiliza ningún conocimiento de dominio (es decir, activaciones locales de neuronas), mientras que este último lo hace.
Los resultados recopilados por los investigadores sugieren que las actualizaciones sinápticas realizadas por sus reglas DSP conducen a un entrenamiento más efectivo y, en última instancia, a un mejor rendimiento que el algoritmo HC. En el futuro, su enfoque podría ayudar a mejorar el aprendizaje a largo plazo en las RNA, permitiendo que los sistemas artificiales construyan de manera efectiva nuevas conexiones basadas en sus experiencias.
"Estamos interesados principalmente en comprender el comportamiento emergente y la dinámica de aprendizaje de las redes neuronales artificiales, y desarrollar un modelo coherente para explicar cómo ocurre la plasticidad sináptica en diferentes escenarios de aprendizaje, ", Dijo Yaman." Creo que hay vastas posibilidades para la investigación futura en esta área, por ejemplo, será interesante escalar el enfoque propuesto a problemas complejos a gran escala (así como redes profundas) y lograr mecanismos de aprendizaje de inspiración biológica que requieran la menor cantidad de supervisión (o ninguna) ".
© 2019 Science X Network