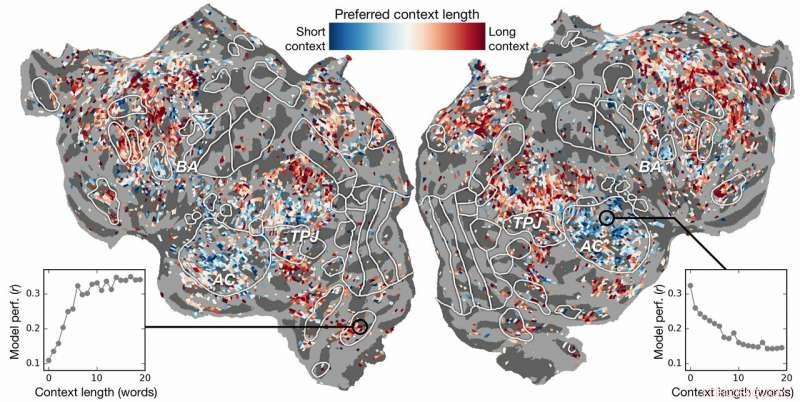
Preferencia de longitud de contexto a través de la corteza. Se calcula un índice de preferencia de longitud de contexto para cada vóxel en un sujeto y se proyecta sobre la superficie cortical de ese sujeto. Los vóxeles que se muestran en azul se modelan mejor utilizando un contexto breve, mientras que los vóxeles rojos se modelan mejor con un contexto extenso. Crédito:laboratorio de Huth, UT Austin
¿Puede la inteligencia artificial (IA) ayudarnos a comprender cómo el cerebro entiende el lenguaje? ¿Puede la neurociencia ayudarnos a comprender por qué la inteligencia artificial y las redes neuronales son efectivas para predecir la percepción humana?
La investigación de Alexander Huth y Shailee Jain de la Universidad de Texas en Austin (UT Austin) sugiere que ambos son posibles.
En un artículo presentado en la Conferencia de 2018 sobre sistemas de procesamiento de información neuronal (NeurIPS), los académicos describieron los resultados de experimentos que utilizaron redes neuronales artificiales para predecir con mayor precisión que nunca cómo las diferentes áreas del cerebro responden a palabras específicas.
"A medida que las palabras vienen a nuestra cabeza, nos formamos ideas de lo que alguien nos está diciendo, y queremos entender cómo nos llega eso dentro del cerebro, "dijo Huth, profesor asistente de Neurociencia y Ciencias de la Computación en UT Austin. "Parece que debería haber sistemas, pero practicamente así no es como funciona el lenguaje. Como todo en biología, es muy difícil reducirlo a un simple conjunto de ecuaciones ".
El trabajo empleó un tipo de red neuronal recurrente llamada memoria larga a corto plazo (LSTM) que incluye en sus cálculos las relaciones de cada palabra con lo que vino antes para preservar mejor el contexto.
"Si una palabra tiene varios significados, infieres el significado de esa palabra para esa oración en particular dependiendo de lo que se dijo anteriormente, "dijo Jain, un doctorado estudiante en el laboratorio de Huth en UT Austin. "Nuestra hipótesis es que esto conduciría a mejores predicciones de la actividad cerebral porque el cerebro se preocupa por el contexto".
Suena obvio pero durante décadas los experimentos de neurociencia consideraron la respuesta del cerebro a palabras individuales sin un sentido de su conexión con cadenas de palabras u oraciones. (Huth describe la importancia de hacer "neurociencia del mundo real" en un artículo de marzo de 2019 en el Revista de neurociencia cognitiva .)
En su trabajo, los investigadores realizaron experimentos para probar, y en última instancia predecir, cómo responderían las diferentes áreas del cerebro al escuchar historias (específicamente, la hora de la radio de la polilla). Utilizaron datos recopilados de máquinas de resonancia magnética funcional (fMRI, por sus siglas en inglés) que capturan los cambios en el nivel de oxigenación de la sangre en el cerebro en función de la actividad de los grupos de neuronas. Esto sirve como corresponsal de dónde se "representan" los conceptos del lenguaje en el cerebro.
Usando supercomputadoras poderosas en el Centro de Computación Avanzada de Texas (TACC), entrenaron un modelo de lenguaje usando el método LSTM para que pudiera predecir de manera efectiva qué palabra vendría después, una tarea similar a las búsquedas de autocompletar de Google, que la mente humana es particularmente experta.
"Al intentar predecir la siguiente palabra, este modelo tiene que aprender implícitamente todas estas otras cosas sobre cómo funciona el lenguaje, "dijo Huth, "como qué palabras tienden a seguir a otras palabras, sin tener acceso al cerebro ni a ningún dato sobre el cerebro ".
Basado tanto en el modelo de lenguaje como en los datos de fMRI, entrenaron un sistema que podía predecir cómo respondería el cerebro cuando escuchara cada palabra en una nueva historia por primera vez.
Los esfuerzos anteriores habían demostrado que es posible localizar las respuestas del lenguaje en el cerebro de manera eficaz. Sin embargo, la nueva investigación mostró que agregar el elemento contextual, en este caso hasta 20 palabras que vinieron antes, mejoró significativamente las predicciones de la actividad cerebral. Descubrieron que sus predicciones mejoran incluso cuando se utiliza la menor cantidad de contexto. Cuanto más contexto se proporcione, mejor será la precisión de sus predicciones.
"Nuestro análisis mostró que si el LSTM incorpora más palabras, luego mejora en la predicción de la siguiente palabra, "dijo Jain, "lo que significa que debe incluir información de todas las palabras del pasado".
La investigación fue más allá. Exploró qué partes del cerebro eran más sensibles a la cantidad de contexto incluido. Ellos encontraron, por ejemplo, que los conceptos que parecen estar localizados en la corteza auditiva eran menos dependientes del contexto.
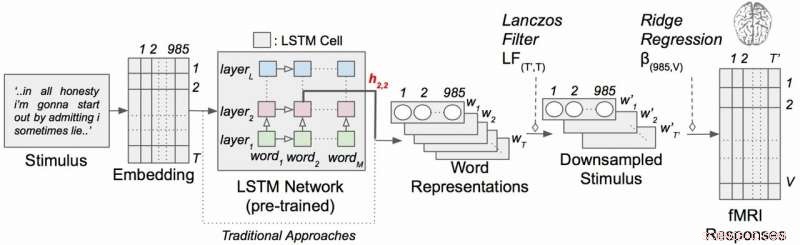
Modelo de codificación del lenguaje contextual con estímulos narrativos. Cada palabra de la historia se proyecta primero en un espacio de incrustación de 985 dimensiones. Las secuencias de representaciones de palabras se introducen en una red LSTM que se entrenó previamente como modelo de lenguaje. Crédito:laboratorio de Huth, UT Austin
"Si escuchas la palabra perro, a esta área no le importa cuáles eran las 10 palabras antes de eso, simplemente va a responder al sonido de la palabra perro ", Huth explicó.
Por otra parte, Las áreas del cerebro que se ocupan del pensamiento de alto nivel eran más fáciles de identificar cuando se incluía más contexto. Esto apoya las teorías de la comprensión de la mente y el lenguaje.
"Había una correspondencia realmente agradable entre la jerarquía de la red artificial y la jerarquía del cerebro, que nos pareció interesante, "Dijo Huth.
El procesamiento del lenguaje natural, o PNL, ha avanzado mucho en los últimos años. Pero cuando se trata de responder preguntas, tener conversaciones naturales, o analizar los sentimientos en textos escritos, La PNL todavía tiene un largo camino por recorrer. Los investigadores creen que su modelo de lenguaje desarrollado por LSTM puede ayudar en estas áreas.
El LSTM (y las redes neuronales en general) funciona asignando valores en el espacio de alta dimensión a los componentes individuales (aquí, palabras) para que cada componente pueda definirse por sus miles de relaciones dispares con muchas otras cosas.
Los investigadores entrenaron el modelo de lenguaje alimentándolo con decenas de millones de palabras extraídas de publicaciones de Reddit. Luego, su sistema hizo predicciones sobre cómo miles de vóxeles (píxeles tridimensionales) en los cerebros de seis sujetos responderían a un segundo conjunto de historias que ni el modelo ni los individuos habían escuchado antes. Debido a que estaban interesados en los efectos de la longitud del contexto y el efecto de las capas individuales en la red neuronal, esencialmente probaron 60 factores diferentes (20 longitudes de retención de contexto y tres dimensiones de capa diferentes) para cada tema.
Todo esto conduce a problemas computacionales de enorme escala, requiriendo cantidades masivas de potencia informática, memoria, almacenamiento, y recuperación de datos. Los recursos de TACC estaban bien adaptados al problema. Los investigadores utilizaron la supercomputadora Maverick, que contiene tanto GPU como CPU para las tareas informáticas, y Corral, un recurso de almacenamiento y gestión de datos, para preservar y distribuir los datos. Al paralelizar el problema en muchos procesadores, pudieron ejecutar el experimento computacional en semanas en lugar de años.
"Para desarrollar estos modelos de forma eficaz, necesitas muchos datos de entrenamiento, "Dijo Huth." Eso significa que tienes que pasar por todo tu conjunto de datos cada vez que quieras actualizar los pesos. Y eso es inherentemente muy lento si no usa recursos paralelos como los de TACC ".
Si suena complejo, Bueno, lo es.
Esto está llevando a Huth y Jain a considerar una versión más optimizada del sistema, donde en lugar de desarrollar un modelo de predicción del lenguaje y luego aplicarlo al cerebro, desarrollan un modelo que predice directamente la respuesta cerebral. A esto lo llaman un sistema de extremo a extremo y es donde Huth y Jain esperan ir en sus investigaciones futuras. Tal modelo mejoraría su desempeño directamente en las respuestas cerebrales. Una predicción incorrecta de la actividad cerebral retroalimentaría el modelo y estimularía mejoras.
"Si esto funciona, entonces es posible que esta red pueda aprender a leer texto o lenguaje de entrada de manera similar a como lo hacen nuestros cerebros, ", Dijo Huth." Imagínese el Traductor de Google, pero entiende lo que dices en lugar de simplemente aprender un conjunto de reglas ".
Con tal sistema en su lugar, Huth cree que es solo cuestión de tiempo hasta que sea factible un sistema de lectura de mentes que pueda traducir la actividad cerebral al lenguaje. Mientras tanto, están obteniendo conocimientos sobre neurociencia e inteligencia artificial a partir de sus experimentos.
"El cerebro es una máquina de cálculo muy eficaz y el objetivo de la inteligencia artificial es construir máquinas que sean realmente buenas en todas las tareas que puede realizar un cerebro". "Dijo Jain." Pero, no entendemos mucho sobre el cerebro. Entonces, intentamos usar la inteligencia artificial para preguntar primero cómo funciona el cerebro, y luego, basado en los conocimientos que obtenemos a través de este método de interrogatorio, y a través de la neurociencia teórica, usamos esos resultados para desarrollar una mejor inteligencia artificial.
"La idea es comprender los sistemas cognitivos, tanto biológicos como artificiales, y utilizarlos en conjunto para comprender y construir mejores máquinas ".