
Un modelo de respuesta inmune innata basado en agentes simula mecánicamente la sepsis en 2-D. Crédito:Laboratorio Nacional Lawrence Livermore
Un enfoque de aprendizaje profundo diseñado originalmente para enseñar a las computadoras a jugar videojuegos mejor que los humanos podría ayudar a desarrollar un tratamiento médico personalizado para la sepsis. una enfermedad que causa alrededor de 300, 000 muertes al año y para las que no existe cura conocida.
Laboratorio Nacional Lawrence Livermore (LLNL), en colaboración con investigadores de la Universidad de Vermont, está explorando cómo el aprendizaje por refuerzo profundo puede descubrir estrategias de fármacos terapéuticos para la sepsis mediante el uso de una simulación del sistema inmunológico innato de un paciente como plataforma para experimentos virtuales. El aprendizaje por refuerzo profundo es un enfoque de aprendizaje automático de última generación desarrollado originalmente por Google DeepMind para enseñar a una red neuronal cómo jugar videojuegos. dado solo píxeles como entrada y la puntuación del juego como señal de aprendizaje. Los algoritmos a menudo superan el rendimiento humano, a pesar de no tener ningún conocimiento sobre la mecánica del juego.
El enfoque de aprendizaje profundo de LLNL trata la simulación del sistema inmunológico desarrollada por sus colaboradores como un videojuego. Usando salidas de la simulación, una "puntuación" basada en la salud del paciente y un algoritmo de optimización, la red neuronal aprende a manipular 12 mediadores de citocinas diferentes (reguladores del sistema inmunológico) para hacer que la respuesta inmunitaria a la infección vuelva a niveles normales. La investigación aparece en un artículo publicado por la Conferencia Internacional sobre Aprendizaje Automático.
"Es un sistema complejo, "dijo el investigador de LLNL Dan Faissol, investigador principal del proyecto. "Hasta ahora, las investigaciones anteriores se han basado en la manipulación de un solo mediador / citocina, generalmente se administra con una sola dosis o en un ciclo muy corto. Creemos que nuestro enfoque tiene un gran potencial porque explora mucho más complejo, Estrategias terapéuticas listas para usar que tratan a cada paciente de manera diferente según las mediciones del paciente a lo largo del tiempo ".
La estrategia de tratamiento que proponen los investigadores es adaptativa y personalizada, mejorando a sí mismo en un circuito de retroalimentación al observar continuamente los niveles de citocinas y prescribir medicamentos específicos para el paciente individual. Cada ejecución de la simulación representa un tipo de paciente diferente y diferentes condiciones iniciales de infección.
"El desafío era mantener las cosas clínicamente relevantes, "explicó el investigador de LLNL Brenden Petersen, el líder técnico del proyecto. "Teníamos que asegurarnos de que todos los aspectos del problema simulado fueran relevantes en el mundo real, que la computadora no estuviera usando ninguna información que realmente no estaría disponible en un hospital. Entonces, solo proporcionamos a la red neuronal información que realmente se puede medir clínicamente, como los niveles de citocinas y el recuento de células de una extracción de sangre ".
Usando el modelo basado en agentes con aprendizaje de refuerzo profundo, los investigadores identificaron una política de tratamiento que logra una tasa de supervivencia del 100 por ciento para los pacientes en los que se capacitó, y una mortalidad de menos del 1 por ciento en 500 pacientes seleccionados al azar.
"La simulación es de naturaleza mecanicista, lo que significa que podemos experimentar virtualmente con medicamentos y combinaciones de medicamentos que no se hayan probado antes para ver si pueden ser prometedores, ", Dijo Faissol." La cantidad de posibles estrategias de tratamiento es enorme, especialmente cuando se consideran estrategias de múltiples fármacos que varían con el tiempo. Sin usar simulación, no hay forma de evaluarlos todos. La parte difícil es descubrir una estrategia que funcione para todo tipo de pacientes. La infección de todos es diferente y el cuerpo de todos es diferente ".
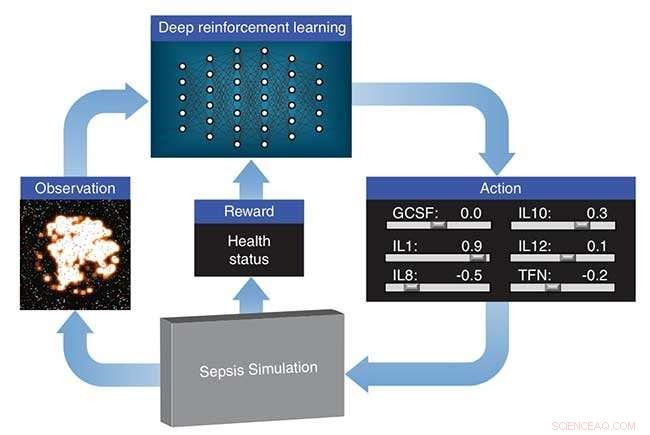
El enfoque de aprendizaje profundo de LLNL trata la simulación del sistema inmunológico desarrollada por sus colaboradores como un videojuego. Usando salidas de la simulación, una "puntuación" basada en la salud del paciente y un algoritmo de optimización, la red neuronal aprende a manipular 12 mediadores de citocinas diferentes (reguladores del sistema inmunológico) para hacer que la respuesta inmunitaria a la infección vuelva a niveles normales. Crédito:Laboratorio Nacional Lawrence Livermore
La investigación del equipo ha demostrado que este enfoque adaptativo puede conducir a conocimientos novedosos, y los investigadores esperan convencer a otros para que adopten el enfoque sobre la sepsis y otras enfermedades.
"Nuestro gran, La visión a largo plazo es un sistema de cabecera de 'circuito cerrado' en el que las mediciones de un paciente se introducen en una herramienta de apoyo a la toma de decisiones. que luego administra los medicamentos correctos en las dosis correctas en el momento correcto, ", Dijo Petersen." Tales estrategias de tratamiento primero tendrían que ser examinadas y ajustadas en modelos animales y de laboratorio húmedo, eventualmente informando tratamientos reales ".
Petersen dijo que la mayor parte del hardware para ejecutar un sistema de circuito cerrado de este tipo ya existe, como con sistemas más simples como bombas de insulina que monitorean constantemente la sangre y administran insulina en el momento adecuado.
El enfoque de aprendizaje por refuerzo profundo del laboratorio aún no se ha probado en el mundo real, pero basado en el éxito con la simulación, los Institutos Nacionales de Salud otorgaron a LLNL y a los investigadores de la Universidad de Vermont una subvención de cinco años para continuar el trabajo, principalmente en la sepsis pero también en el cáncer.
"Este es un proyecto apasionante, "dijo Gary An, médico de cuidados intensivos de la Universidad de Vermont y científico computacional que desarrolló la versión original de la simulación de sepsis. "Este es un proyecto increíblemente novedoso que reúne tres áreas de vanguardia de la investigación computacional:simulaciones multiescala de alta resolución de procesos biológicos, extensión del aprendizaje por refuerzo profundo a la investigación biomédica y el uso de la informática de alto rendimiento para unirlo todo ".
El director de Bioingeniería de LLNL, Shankar Sundaram, describió el enfoque como "un ejemplo ilustrativo del laboratorio que contribuye al desarrollo de una posible solución terapéutica a un problema de salud complejo y crítico para nuestra misión de bioseguridad". aplicar y promover nuestras capacidades de vanguardia en el aprendizaje automático científico y enfocar la mejora causal, comprensión mecanicista ".
Los investigadores de LLNL también han iniciado una colaboración con Moffitt Cancer Center en Florida para ver si un enfoque similar podría aprender estrategias efectivas de terapia con medicamentos usando una simulación de cáncer. Moffitt lanzó una versión de videojuego de su simulación llamada "Cancer Crusade" que se ejecuta en teléfonos móviles.
"Una estrategia consiste en colaborar con el aprendizaje mediante el análisis de los tratamientos registrados por los jugadores con mayor puntuación de todo el mundo, Petersen dijo. "Aplicamos nuestro enfoque de aprendizaje profundo y queremos ver cómo nuestros tratamientos computados se comparan con los mejores jugadores:un enfrentamiento 'hombre contra máquina'".
El proyecto de sepsis también ha llevado a un nuevo esfuerzo en LLNL que investiga estrategias de ciberdefensa adaptativas y autónomas utilizando simulación y aprendizaje por refuerzo profundo.














