Un sistema de "visión por computadora" desarrollado en UCLA puede identificar objetos basándose solo en destellos parciales, como usando estos fragmentos de fotos de una motocicleta. Crédito:Universidad de California, los Angeles
Los ingenieros de UCLA y de la Universidad de Stanford han demostrado un sistema informático que puede descubrir e identificar los objetos del mundo real que "ve" basándose en el mismo método de aprendizaje visual que usan los humanos.
El sistema es un avance en un tipo de tecnología llamada "visión por computadora, "que permite a las computadoras leer e identificar imágenes visuales. Podría ser un paso importante hacia los sistemas generales de inteligencia artificial:computadoras que aprenden por sí mismas, son intuitivos, tomar decisiones basadas en el razonamiento e interactuar con los humanos de una manera mucho más humana. Aunque los sistemas de visión por computadora de IA actuales son cada vez más poderosos y capaces, son específicas de la tarea, lo que significa que su capacidad para identificar lo que ven está limitada por cuánto han sido entrenados y programados por humanos.
Incluso los mejores sistemas de visión por computadora de hoy en día no pueden crear una imagen completa de un objeto después de ver solo ciertas partes de él, y los sistemas pueden engañarse al ver el objeto en un entorno desconocido. Los ingenieros tienen como objetivo crear sistemas informáticos con esas habilidades, al igual que los humanos pueden entender que están mirando a un perro, incluso si el animal se esconde detrás de una silla y solo se ven las patas y la cola. Humanos por supuesto, también puede intuir fácilmente dónde está la cabeza del perro y el resto de su cuerpo, pero esa capacidad aún elude a la mayoría de los sistemas de inteligencia artificial.
Los sistemas de visión por computadora actuales no están diseñados para aprender por sí mismos. Deben estar capacitados sobre qué aprender exactamente, generalmente revisando miles de imágenes en las que los objetos que están tratando de identificar están etiquetados para ellos. Ordenadores, por supuesto, Tampoco puede explicar su razón de ser para determinar qué representa el objeto en una foto:los sistemas basados en IA no construyen una imagen interna o un modelo de sentido común de objetos aprendidos como lo hacen los humanos.
El nuevo método de los ingenieros, descrito en el procedimientos de la Academia Nacional de Ciencias , muestra una forma de evitar esas deficiencias.
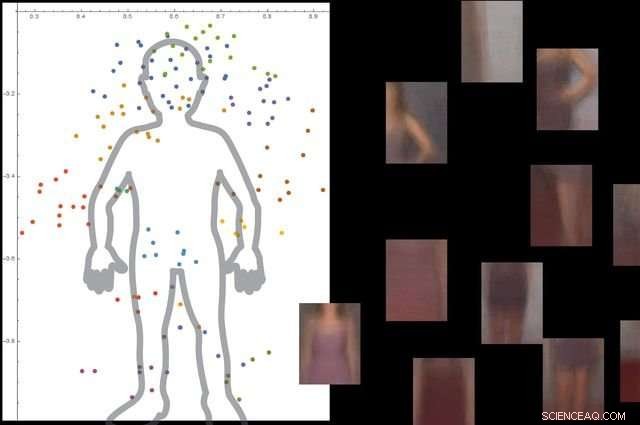
El sistema comprende lo que es un cuerpo humano al mirar miles de imágenes con personas en ellas, y luego ignorar los objetos de fondo no esenciales. Crédito:Universidad de California, los Angeles
El enfoque consta de tres grandes pasos. Primero, el sistema divide una imagen en pequeños fragmentos, que los investigadores llaman "viewlets". Segundo, la computadora aprende cómo encajan esos viewlets para formar el objeto en cuestión. Y finalmente, mira qué otros objetos hay en el área circundante, y si la información sobre esos objetos es relevante para describir e identificar el objeto principal.
Para ayudar al nuevo sistema a "aprender" más como los humanos, los ingenieros decidieron sumergirlo en una réplica de Internet del entorno en el que viven los humanos.
"Afortunadamente, Internet proporciona dos cosas que ayudan a un sistema de visión por computadora inspirado en el cerebro a aprender de la misma manera que lo hacen los humanos, "dijo Vwani Roychowdhury, profesor de UCLA de ingeniería eléctrica e informática e investigador principal del estudio. "Una es una gran cantidad de imágenes y videos que representan los mismos tipos de objetos. La segunda es que esos objetos se muestran desde muchas perspectivas:oscurecidas, ojo de pájaro, de cerca, y se colocan en diferentes tipos de entornos ".
Para desarrollar el marco, los investigadores obtuvieron conocimientos de la psicología cognitiva y la neurociencia.
"Comenzando como bebés, aprendemos qué es algo porque vemos muchos ejemplos de ello, en muchos contextos, ", Dijo Roychowdhury." Ese aprendizaje contextual es una característica clave de nuestro cerebro, y nos ayuda a construir modelos robustos de objetos que son parte de una cosmovisión integrada donde todo está conectado funcionalmente ".
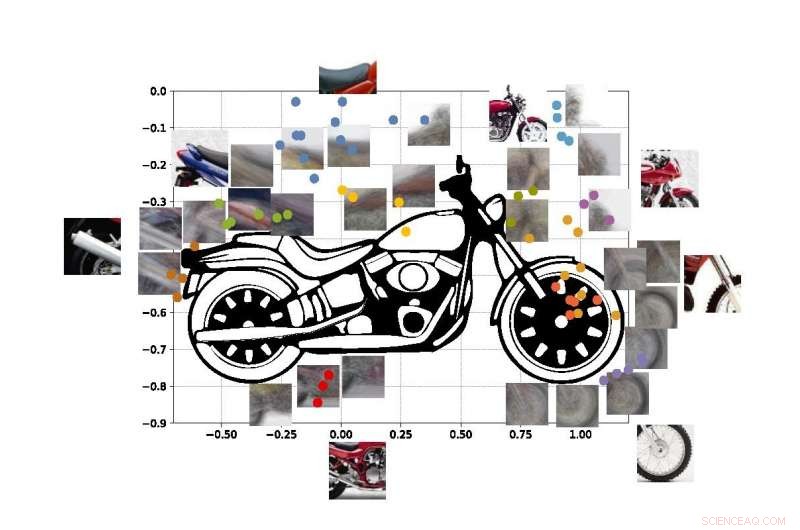
Los puntos de colores de la figura muestran las coordenadas estimadas de los centros de algunos de los viewlets de nuestra moto SUVM. Cada representación de viewlet es una combinación de vistas / parches de ejemplo que tienen apariencias similares. Crédito:Lichao Chen, Tianyi Wang, y Vwani Roychowdhury (Universidad de California, Los Angeles).
Los investigadores probaron el sistema con aproximadamente 9, 000 imágenes, cada uno mostrando personas y otros objetos. La plataforma pudo construir un modelo detallado del cuerpo humano sin guía externa y sin que las imágenes estuvieran etiquetadas.
Los ingenieros realizaron pruebas similares utilizando imágenes de motocicletas, coches y aviones. En todos los casos, su sistema funcionó mejor o al menos tan bien como los sistemas tradicionales de visión por computadora que se han desarrollado con muchos años de capacitación.
El coautor principal del estudio es Thomas Kailath, profesor emérito de ingeniería eléctrica en Stanford que fue asesor de doctorado de Roychowdhury en la década de 1980. Otros autores son los ex estudiantes de doctorado de UCLA Lichao Chen (ahora ingeniero de investigación en Google) y Sudhir Singh (quien fundó una empresa que construye compañeros de enseñanza robóticos para niños).
Singh, Roychowdhury y Kailath trabajaron juntos anteriormente para desarrollar uno de los primeros motores de búsqueda visual automatizados para la moda, el StileEye ahora cerrado, lo que dio lugar a algunas de las ideas básicas detrás de la nueva investigación.