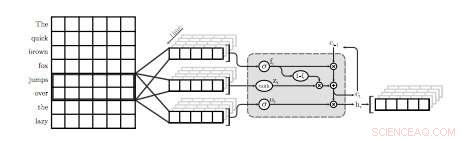
Una ilustración de la primera capa QRNN para modelado de lenguaje. En esta visualización, una capa QRNN con un tamaño de ventana de dos convolves y agrupaciones que utilizan incrustaciones de la entrada. Tenga en cuenta la ausencia de ponderaciones recurrentes. Crédito:Tang &Lin.
Un equipo de investigadores de la Universidad de Waterloo en Canadá ha llevado a cabo recientemente un estudio que explora las compensaciones entre precisión y eficiencia de los modelos de lenguaje neuronal (NLM) aplicados específicamente a dispositivos móviles. En su papel que fue prepublicado en arXiv, los investigadores también propusieron una técnica sencilla para recuperar cierta perplejidad, una medida del desempeño de un modelo de lenguaje, utilizando una cantidad insignificante de memoria.
Los NLM son modelos de lenguaje basados en redes neuronales a través de los cuales los algoritmos pueden aprender la distribución típica de secuencias de palabras y hacer predicciones sobre la siguiente palabra en una oración. Estos modelos tienen una serie de aplicaciones útiles, por ejemplo, permitiendo teclados de software más inteligentes para teléfonos móviles u otros dispositivos.
"Los modelos de lenguaje neuronal (NLM) existen en un espacio de compensación de precisión-eficiencia donde una mayor perplejidad generalmente tiene el costo de una mayor complejidad de cálculo, "escribieron los investigadores en su artículo". En una aplicación de teclado de software en dispositivos móviles, esto se traduce en un mayor consumo de energía y una menor duración de la batería ".
Cuando se aplica a teclados de software, Los NLM pueden conducir a una predicción de la siguiente palabra más precisa, permitiendo a los usuarios ingresar la siguiente palabra en una oración determinada con un solo toque. Dos aplicaciones existentes que utilizan redes neuronales para proporcionar esta función son SwiftKey1 y Swype2. Sin embargo, estas aplicaciones a menudo requieren mucha potencia para funcionar, agotando rápidamente las baterías de los dispositivos móviles.
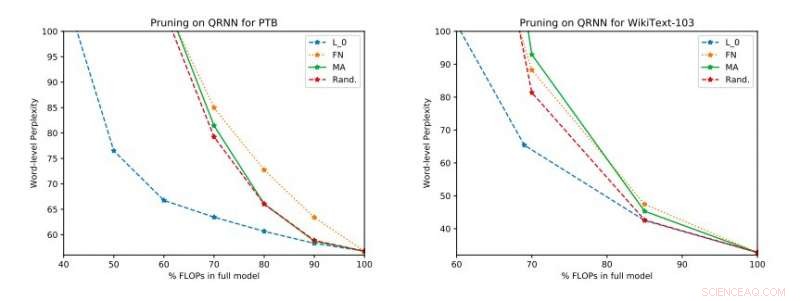
Resultados experimentales completos en Penn Treebank y WikiText-103. Ilustramos el espacio de compensación perplejidad-eficiencia en el conjunto de prueba obtenido antes de aplicar la actualización de rango único. Crédito:Tang &Lin.
"Basado en métricas estándar como perplejidad, Las técnicas neuronales representan un avance en el modelado del lenguaje de última generación, ", explicaron los investigadores en su artículo." Mejores modelos, sin embargo, tienen un costo en complejidad computacional, lo que se traduce en un mayor consumo de energía. En el contexto de los dispositivos móviles, la eficiencia energética es, por supuesto, un importante objetivo de optimización ".
Según los investigadores, Hasta ahora, los NLM se han evaluado principalmente en el contexto del reconocimiento de imágenes y la detección de palabras clave, mientras que su equilibrio entre precisión y eficiencia en las aplicaciones de procesamiento del lenguaje natural (NLP) aún no se ha investigado a fondo. Su estudio se centra en esta área de investigación inexplorada, llevar a cabo una evaluación de los NLM y sus compensaciones entre precisión y eficiencia en una Raspberry Pi.
"Nuestras evaluaciones empíricas consideran tanto la perplejidad como el consumo de energía en una Raspberry Pi, donde demostramos qué métodos proporcionan el mejor punto de operación de consumo de energía de perplejidad, ", dijeron los investigadores." En un punto operativo, una de las técnicas es capaz de proporcionar ahorros de energía del 40 por ciento en comparación con los [métodos] de última generación con solo un aumento relativo de perplejidad del 17 por ciento ".
En su estudio, los investigadores también evaluaron una serie de técnicas de poda del tiempo de inferencia en redes neuronales cuasi recurrentes (QRNN). Extender la usabilidad de los métodos de poda de tiempo de capacitación existentes a QRNN en tiempo de ejecución, alcanzaron varios puntos operativos dentro del espacio de compensación precisión-eficiencia. Para mejorar el rendimiento con una pequeña cantidad de memoria, sugirieron entrenar y almacenar actualizaciones de peso de un solo rango en los puntos operativos deseados.
© 2018 Tech Xplore