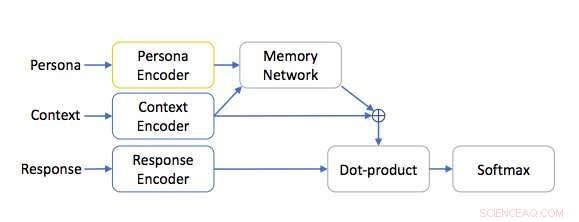
Arquitectura de red basada en personas. Crédito:Mazaré et al.
Los investigadores de Facebook han recopilado recientemente un conjunto de datos de 5 millones de personas y 700 millones de diálogos basados en personas. Esta base de datos podría utilizarse para capacitar sistemas de diálogo de extremo a extremo, resultando en diálogos más atractivos y ricos entre los agentes informáticos y los humanos.
Sistemas de diálogo, o agentes conversacionales (CA), son sistemas informáticos diseñados para comunicarse con los seres humanos a través de texto, habla, gráficos, u otros métodos, de forma coherente. Hasta aquí, sistemas de diálogo basados en arquitecturas neuronales, como LSTM o redes de memoria, se ha encontrado que son particularmente prometedores para lograr una comunicación fluida, en particular cuando se le capacita directamente en los registros de diálogo.
"Una de sus principales ventajas es que pueden confiar en grandes fuentes de datos de diálogos existentes para aprender a cubrir varios dominios sin requerir ningún conocimiento experto, "escribieron los investigadores en su artículo, que fue prepublicado en arXiv. "Sin embargo, la otra cara es que también exhiben un compromiso limitado, especialmente en los entornos de charla:carecen de coherencia y no aprovechan las estrategias de participación proactiva como lo hacen los chatbots con secuencias de comandos (incluso parcialmente) ".
En un estudio reciente, Un equipo diferente de investigadores del Instituto de Algoritmos de Aprendizaje de Montreal (MILA) y Facebook AI crearon un conjunto de datos llamado PERSONA-CHAT, que incluye diálogos entre agentes con perfiles de texto, o personas, adjunto a ellos. Descubrieron que entrenar un sistema de diálogo sobre una persona en particular mejoraba su participación en las interacciones.
"Sin embargo, el conjunto de datos PERSONA-CHAT se creó utilizando un mecanismo de recopilación de datos artificial basado en Mechanical Turk, "explicaron los investigadores en su artículo." Como resultado, ni los diálogos ni las personas pueden ser completamente representativos de las interacciones reales entre el usuario y el robot y la cobertura del conjunto de datos sigue siendo limitada, que contiene un poco más de 1000 personas diferentes ".
Para abordar las limitaciones del conjunto de datos compilado previamente, los investigadores de Facebook crearon un nuevo conjunto de datos de diálogo basado en personas a gran escala, compuesto por conversaciones extraídas de la plataforma en línea Reddit. Su estudio lleva el trabajo de sus predecesores un paso más allá, mediante el uso de interacciones más representativas.
"En este papel, Creamos un conjunto de datos de diálogo basado en personas a gran escala utilizando conversaciones extraídas previamente de Reddit, "escribieron los investigadores". Con heurísticas simples, creamos un corpus de más de 5 millones de personas que abarcan más de 700 millones de conversaciones ".
Para evaluar su efectividad, los investigadores capacitaron sistemas de diálogo de extremo a extremo basados en la persona en su conjunto de datos recientemente desarrollado. Los sistemas entrenados en su conjunto de datos pudieron llevar a cabo conversaciones más atractivas, superando a otros agentes conversacionales que no tuvieron acceso a personas durante su formación.
Curiosamente, su conjunto de datos condujo a resultados de vanguardia incluso cuando los sistemas de diálogo simplemente se entrenaron previamente en él. En el futuro, estos hallazgos podrían conducir al desarrollo de chatbots más atractivos, que también se puede personalizar y entrenar para adquirir una personalidad en particular.
"Demostramos que los modelos de entrenamiento para alinear las respuestas tanto con la personalidad de su autor como con el contexto mejoran el rendimiento de predicción, "escribieron los investigadores." Dado que el entrenamiento previo conduce a una mejora considerable en el rendimiento, el trabajo futuro podría afinar este modelo para varios sistemas de diálogo ".
© 2018 Tech Xplore