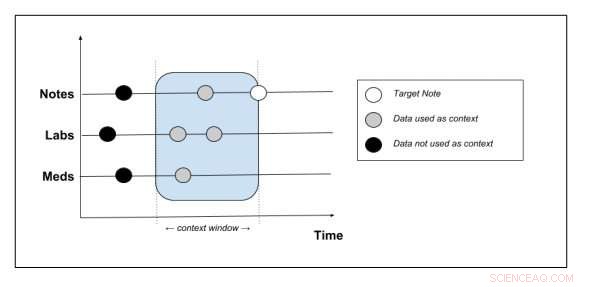
Esquema que muestra qué datos de contexto se extraen del registro del paciente. Crédito:Peter Liu
Actualmente, los médicos dedican mucho tiempo a escribir notas sobre los pacientes e insertarlas en los sistemas de registros médicos electrónicos (EHR). Según un estudio de 2016, los médicos dedican aproximadamente dos horas al trabajo administrativo por cada hora que pasan con un paciente. Gracias a las herramientas de inteligencia artificial de última generación, este proceso de redacción de notas pronto podría automatizarse, ayudar a los médicos a gestionar mejor sus turnos y aliviarlos de esta tediosa tarea.
Peter Liu, investigador de Google Brain, ha desarrollado recientemente una nueva tarea de modelado de lenguaje que puede predecir el contenido de nuevas notas analizando los registros médicos de los pacientes, que incluyen datos como datos demográficos, mediciones de laboratorio, medicamentos y notas pasadas. En su estudio, prepublicado en arXiv, entrenó modelos generativos utilizando el conjunto de datos de EHR MIMIC-III (Centro de información médica para cuidados intensivos), y luego comparó las notas generadas por los modelos con notas reales del conjunto de datos.
Los métodos comúnmente adoptados para reducir el tiempo que los médicos dedican a tomar notas incluyen el uso de servicios de dictado y el empleo de asistentes que pueden escribir notas para ellos. Las herramientas de inteligencia artificial podrían ayudar a abordar este problema, reducir los costos gastados en personal y recursos adicionales.
"Funciones de escritura asistida para notas, como el autocompletado o la verificación de errores, beneficiarse de los modelos lingüísticos, "Liu escribe en su periódico." Cuanto más fuerte es el modelo, cuanto más efectivas serían probablemente esas características. Por lo tanto, el enfoque de este artículo está en la construcción de modelos de lenguaje para notas clínicas ".
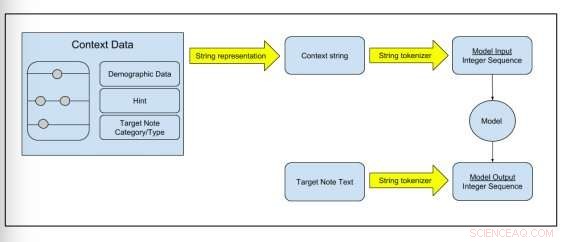
Figura 2:Esquema que muestra cómo se transforman los datos sin procesar en datos de entrenamiento del modelo. Crédito:Peter Liu
Liu empleó dos modelos de lenguaje:el primero se llama arquitectura de transformador, y fue introducido en un estudio publicado el año pasado en el Avances en los sistemas de procesamiento de información neuronal diario. Como este modelo funciona mejor con textos más cortos, como oraciones individuales, También probó un modelo basado en transformadores introducido recientemente, llamado transformador con atención de memoria comprimida (T-DMCA), que resultó ser más eficaz para secuencias más largas.
Entrenó estos modelos en el conjunto de datos MIMIC-III, que contiene HCE anonimizado de 39, 597 pacientes de la unidad de cuidados intensivos de un hospital de tercer nivel. Este es actualmente el conjunto de datos de HCE más completo que está disponible públicamente y se puede acceder fácilmente en línea.
"Hemos introducido una nueva tarea de modelado de lenguaje para notas clínicas basadas en datos de HER y mostramos cómo representar el contexto de datos multimodales en el modelo, ", Explicó Liu en su artículo." Propusimos métricas de evaluación para la tarea y presentamos resultados alentadores que muestran el poder predictivo de tales modelos ".
Los modelos fueron capaces de predecir con eficacia gran parte del contenido de las notas de los médicos. En el futuro, podrían ayudar al desarrollo de funciones de corrección ortográfica y de autocompletado más sofisticadas. Estas características podrían luego integrarse en herramientas que ayuden a los médicos a completar el trabajo administrativo. Si bien los resultados de este estudio son prometedores, Aún deben superarse algunos desafíos antes de que los modelos puedan emplearse a mayor escala.
"En muchos casos, el contexto máximo proporcionado por la HCE es insuficiente para predecir completamente la nota, "Liu explica en su artículo." El caso más obvio es la falta de datos de imágenes en MIMIC-III para los informes de radiología. Para las notas que no son de imágenes, también carecemos de información sobre las últimas interacciones entre el paciente y el proveedor. El trabajo futuro podría intentar aumentar el contexto de la nota con datos más allá de la HCE, p.ej. datos de imágenes, o transcripciones de interacciones médico-paciente. Aunque discutimos la corrección de errores y las funciones de autocompletar en el software EHR, sus efectos sobre la productividad del usuario no se midieron en el contexto clínico, que dejamos como trabajo futuro ".
© 2018 Tech Xplore