Comparación de clasificaciones de conceptos para un informe de Human Rights Watch. La columna 'Verdad fundamental' muestra las ocho personas mencionadas con más frecuencia en el informe 'La crisis humanitaria de Venezuela', mientras que las otras columnas muestran valores devueltos por varios métodos de descubrimiento. Los valores que se encuentran entre los conceptos básicos de verdad se indican mediante recuadros oscuros. El método de contexto devuelve valores que son todos relevantes (incluso si faltan en el artículo original), mientras que el método de co-ocurrencia devuelve muchos conceptos populares pero irrelevantes (por ejemplo, políticos que hacen declaraciones generales sobre el tema). Crédito:IBM
En IBM Research AI, creamos una solución basada en inteligencia artificial para ayudar a los analistas a preparar informes. El artículo que describe este trabajo ganó recientemente el premio al mejor artículo en la sección "En uso" de la Extended Semantic Web Conference (ESWC) de 2018.
Los analistas a menudo tienen la tarea de preparar informes completos y precisos sobre temas determinados o preguntas de alto nivel, que pueden ser utilizados por organizaciones, empresas, o agencias gubernamentales para tomar decisiones informadas, reduciendo el riesgo asociado con sus planes futuros. Para preparar dichos informes, los analistas necesitan identificar temas, gente, organizaciones y eventos relacionados con las preguntas. Como ejemplo, con el fin de preparar un informe sobre las consecuencias del Brexit en los mercados financieros de Londres, un analista debe estar al tanto de los temas clave relacionados (por ejemplo, mercados financieros, economía, Brexit, Proyecto de ley de divorcio Brexit), personas y organizaciones (por ejemplo, La Unión Europea, tomadores de decisiones en la UE y el Reino Unido, personas involucradas en las negociaciones del Brexit), y eventos (por ejemplo, Reuniones de negociación, Elecciones parlamentarias dentro de la UE, etc.). Una solución asistida por IA puede ayudar a los analistas a preparar informes completos y también evitar sesgos basados en experiencias pasadas. Por ejemplo, un analista podría perder una fuente importante de información si no se ha utilizado eficazmente en el pasado.
El equipo de inducción del conocimiento de IBM Research AI creó la solución utilizando aprendizaje profundo y datos de eventos estructurados. El equipo, dirigido por Alfio Gliozzo, también ganó el prestigioso premio Semantic Web Challenge el año pasado.
Incrustaciones semánticas de bases de datos de eventos
La novedad técnica clave de este trabajo es la creación de incrustaciones semánticas a partir de datos de eventos estructurados. La entrada a nuestro motor de incrustaciones semánticas es una gran fuente de datos estructurados (p. Ej., tablas de base de datos con millones de filas) y la salida es una gran colección de vectores con un tamaño constante (por ejemplo, 300) donde cada vector representa el contexto semántico de un valor en los datos estructurados. La idea central es similar a la idea popular y ampliamente utilizada de incrustaciones de palabras en el procesamiento del lenguaje natural. pero en lugar de palabras, representamos valores en los datos estructurados. El resultado es una solución potente que permite una búsqueda semántica rápida y eficaz en diferentes campos de la base de datos. Una sola consulta de búsqueda toma solo unos pocos milisegundos, pero recupera resultados basados en la extracción de cientos de millones de registros y miles de millones de valores.
Si bien experimentamos con varios modelos de redes neuronales para crear incrustaciones, obtuvimos resultados muy prometedores utilizando una simple adaptación del modelo original de skip-gram word2vec. Este es un modelo de red neuronal superficial eficiente basado en una arquitectura que predice el contexto (palabras circundantes) dada a una palabra en un documento. En nuestro trabajo, no se trata de documentos de texto, sino de registros de bases de datos estructurados. Para esto, ya no necesitamos usar una ventana deslizante de tamaño fijo o aleatorio para capturar el contexto. En datos estructurados, el contexto está definido por todos los valores en la misma fila independientemente de la posición de la columna, ya que dos columnas adyacentes en una base de datos están tan relacionadas como otras dos columnas. La otra diferencia en nuestra configuración es la necesidad de capturar diferentes campos (o columnas) en la base de datos. Nuestro motor necesita habilitar consultas semánticas generales (es decir, devolver cualquier valor de la base de datos relacionado con el valor dado) y valores específicos del campo (es decir, devuelve valores de un campo dado relacionado con el valor de entrada). Para esto, asignamos un tipo a los vectores construidos a partir de cada campo y construimos un índice que admite consultas genéricas o específicas de tipo.
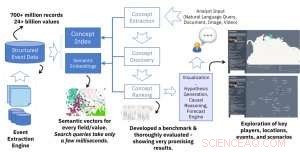
Crédito:IBM
Para el trabajo descrito en nuestro artículo, utilizamos tres bases de datos de eventos disponibles públicamente como entrada:GDELT, ICEWS, y EventRegistry. En general, estas bases de datos constan de cientos de millones de registros (objetos JSON o filas de bases de datos) y miles de millones de valores en varios campos (atributos). Usando nuestro motor de incrustaciones, cada valor se convierte en un vector que representa el contexto en los datos.
Una consulta de recuperación simple
Se puede ver qué tan bien captura el contexto nuestro motor utilizando una consulta de recuperación simple. Por ejemplo, al consultar el valor "Hilary Clinton" (mal escrito) en el campo "persona" en GDELT GKG, el primer resultado o el vector más similar es "Hilary Clinton" (mal escrito) debajo del campo "nombre" y los siguientes vectores más similares son "Hillary Clinton" (ortografía correcta) debajo de los campos "persona" y "nombre". Esto se debe al contexto muy similar del valor mal escrito y la ortografía correcta, y también los valores de los campos "nombre" y "persona". El resto de los resultados de la consulta anterior incluyen políticos de EE. UU., particularmente los activos durante las últimas elecciones presidenciales, así como organizaciones relacionadas, personas con roles laborales similares en el pasado, y miembros de la familia.
Búsqueda de similitudes en consultas combinadas
Por supuesto, nuestra solución es capaz de lograr mucho más que una simple consulta de recuperación. En particular, uno puede combinar estas consultas para convertir un conjunto de valores extraídos de una consulta de lenguaje natural en un vector y realizar una búsqueda de similitud. Evaluamos el resultado de este enfoque utilizando un punto de referencia creado a partir de informes escritos por expertos humanos, y examinó la capacidad de nuestro motor para devolver los conceptos descritos en los informes utilizando el título del informe como única entrada. Los resultados mostraron claramente la superioridad de nuestro enfoque de descubrimiento de conceptos basado en incrustaciones semánticas en comparación con un enfoque de línea de base que se basa únicamente en la co-ocurrencia de los valores.
Nuevas aplicaciones en el descubrimiento de conceptos
Un aspecto muy interesante de nuestro marco es que a cualquier valor y a cualquier campo se le asigna un vector que representa su contexto, lo que permite nuevas aplicaciones interesantes. Por ejemplo, incrustamos coordenadas de latitud y longitud de eventos en las bases de datos en el mismo espacio semántico de conceptos, y trabajé con el Laboratorio de IA Visual dirigido por Mauro Martino para construir un marco de visualización que resalte ubicaciones relacionadas en un mapa geográfico dada una pregunta en lenguaje natural. Otra aplicación interesante que estamos investigando actualmente es usar los conceptos recuperados y sus incrustaciones semánticas como características para un modelo de aprendizaje automático que el analista necesita construir. Esto se puede utilizar en un motor de ciencia de datos y aprendizaje automático automatizado (AutoML), y apoyar a los analistas en otro aspecto importante de sus trabajos. Estamos planeando integrar esta solución en el Asesor de planificación de escenarios de IBM, un sistema de apoyo a la toma de decisiones para analistas de riesgos.
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.