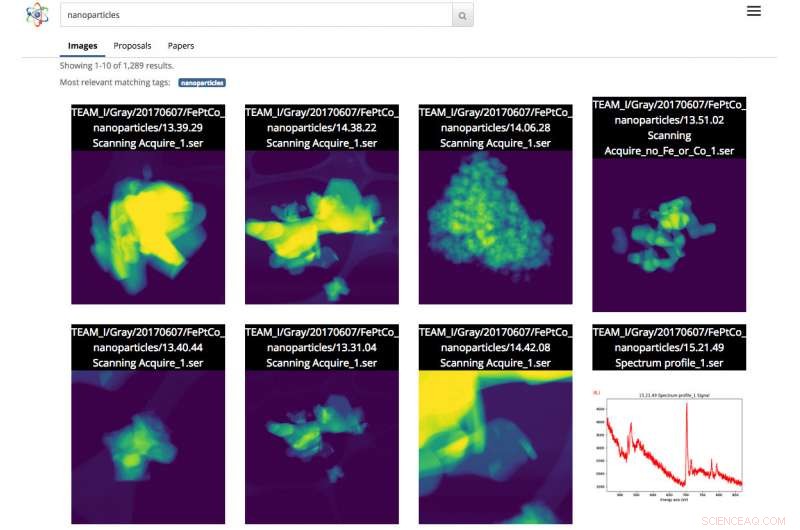
Captura de pantalla de la interfaz de Science Search. En este caso, el usuario realizó una búsqueda de imágenes de nanopartículas. Crédito:Gonzalo Rodrigo, Laboratorio de Berkeley
A medida que los conjuntos de datos científicos aumentan tanto en tamaño como en complejidad, la capacidad de etiquetar, filtrar y buscar este diluvio de información se ha convertido en un laborioso, tarea que requiere mucho tiempo y, a veces, es imposible, sin la ayuda de herramientas automatizadas.
Teniendo esto en cuenta, un equipo de investigadores del Laboratorio Nacional Lawrence Berkeley (Berkeley Lab) y UC Berkeley están desarrollando herramientas innovadoras de aprendizaje automático para extraer información contextual de conjuntos de datos científicos y generar automáticamente etiquetas de metadatos para cada archivo. Luego, los científicos pueden buscar estos archivos a través de un motor de búsqueda basado en la web para obtener datos científicos, llamado Science Search, que está construyendo el equipo de Berkeley.
Como prueba de concepto, el equipo está trabajando con el personal de la Fundición Molecular del Departamento de Energía (DOE), ubicado en Berkeley Lab, demostrar los conceptos de Science Search sobre las imágenes captadas por los instrumentos de la instalación. Se ha puesto a disposición de los investigadores de Foundry una versión beta de la plataforma.
"Una herramienta como Science Search tiene el potencial de revolucionar nuestra investigación, "dice Colin Ophus, un científico de investigación de fundición molecular dentro del Centro Nacional de Microscopía Electrónica (NCEM) y Science Search Collaborator. "Somos una Facilidad Nacional de Usuarios financiada por los contribuyentes, y nos gustaría que todos los datos estuvieran ampliamente disponibles. en lugar de la pequeña cantidad de imágenes elegidas para su publicación. Sin embargo, hoy dia, la mayoría de los datos que se recopilan aquí solo son examinados por un puñado de personas:los productores de datos, incluido el PI (investigador principal), sus postdoctorados o estudiantes de posgrado, porque actualmente no existe una manera fácil de examinar y compartir los datos. Al hacer que estos datos sin procesar se puedan buscar y compartir fácilmente, vía Internet, Science Search podría abrir este depósito de 'datos oscuros' a todos los científicos y maximizar el impacto científico de nuestras instalaciones ".
Los desafíos de la búsqueda de datos científicos
Hoy dia, Los motores de búsqueda se utilizan de forma ubicua para encontrar información en Internet, pero la búsqueda de datos científicos presenta un conjunto diferente de desafíos. Por ejemplo, El algoritmo de Google se basa en más de 200 pistas para lograr una búsqueda eficaz. Estas pistas pueden venir en forma de palabras clave en una página web, metadatos en imágenes o comentarios de la audiencia de miles de millones de personas cuando hacen clic en la información que buscan. A diferencia de, Los datos científicos vienen en muchas formas que son radicalmente diferentes a las de una página web promedio, requiere un contexto específico de la ciencia y, a menudo, también carece de los metadatos para proporcionar el contexto que se requiere para búsquedas efectivas.
En instalaciones de usuarios nacionales como Molecular Foundry, Investigadores de todo el mundo solicitan tiempo y luego viajan a Berkeley para utilizar instrumentos extremadamente especializados de forma gratuita. Ophus señala que las cámaras actuales de los microscopios en Foundry pueden recopilar hasta un terabyte de datos en menos de 10 minutos. Luego, los usuarios deben examinar manualmente estos datos para encontrar imágenes de calidad con "buena resolución" y guardar esa información en un sistema de archivos compartido seguro. como Dropbox, o en un disco duro externo que eventualmente se llevarán a casa para analizar.
A menudo, los investigadores que vienen a Molecular Foundry solo tienen un par de días para recopilar sus datos. Debido a que es muy tedioso y requiere mucho tiempo agregar notas manualmente a terabytes de datos científicos y no existe un estándar para hacerlo, la mayoría de los investigadores simplemente escriben descripciones abreviadas en el nombre del archivo. Esto podría tener sentido para la persona que guarda el archivo, pero a menudo no tiene mucho sentido para nadie más.
"La falta de etiquetas de metadatos reales eventualmente causa problemas cuando el científico intenta encontrar los datos más tarde o intenta compartirlos con otros, "dice Lavanya Ramakrishnan, científico de planta en la División de Investigación Computacional (CRD) de Berkeley Lab y co-investigador principal del proyecto Science Search. "Pero con las técnicas de aprendizaje automático, podemos hacer que las computadoras ayuden con lo que es laborioso para los usuarios, incluida la adición de etiquetas a los datos. Luego, podemos usar esas etiquetas para buscar los datos de manera efectiva ".
Para abordar el problema de los metadatos, el equipo de Berkeley Lab utiliza técnicas de aprendizaje automático para extraer el "ecosistema científico", incluidas las marcas de tiempo de los instrumentos, registros de usuarios de las instalaciones, propuestas científicas, publicaciones y estructuras del sistema de archivos:para obtener información contextual. La información colectiva de estas fuentes, incluida la marca de tiempo del experimento, notas sobre la resolución y el filtro utilizados y la solicitud de tiempo del usuario, todo proporciona información contextual crítica. El equipo del laboratorio de Berkeley ha creado una pila de software innovadora que utiliza técnicas de aprendizaje automático, incluido el procesamiento del lenguaje natural, extrae palabras clave contextuales sobre el experimento científico y crea automáticamente etiquetas de metadatos para los datos.
Para la prueba de concepto, Ophus compartió datos del microscopio electrónico TEAM 1 de Molecular Foundry en NCEM que fue recopilado recientemente por el personal de la instalación, con el equipo de Science Search. También se ofreció a etiquetar algunos miles de imágenes para dar a las herramientas de aprendizaje automático algunas etiquetas desde las que empezar a aprender. Si bien este es un buen comienzo, El co-investigador principal de Science Search, Gunther Weber, señala que la mayoría de las aplicaciones de aprendizaje automático exitosas generalmente requieren significativamente más datos y comentarios para ofrecer mejores resultados. Por ejemplo, en el caso de motores de búsqueda como Google, Weber señala que se crean conjuntos de datos de entrenamiento y se validan las técnicas de aprendizaje automático cuando miles de millones de personas en todo el mundo verifican su identidad haciendo clic en todas las imágenes con letreros de calles o escaparates después de escribir sus contraseñas. o en Facebook cuando etiquetan a sus amigos en una imagen.
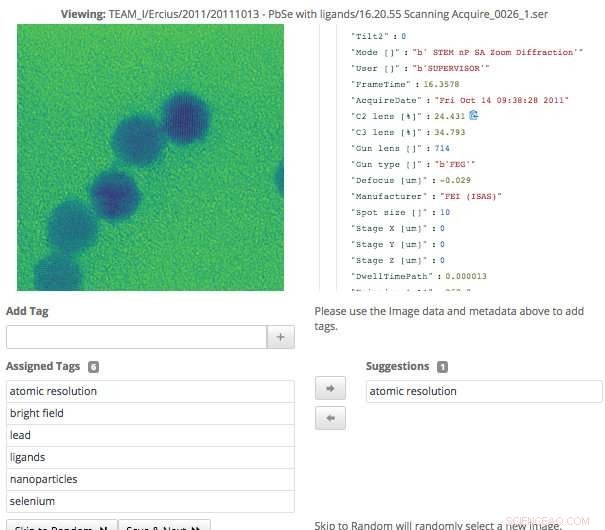
Esta captura de pantalla de la interfaz de Science Search muestra cómo los usuarios pueden validar fácilmente las etiquetas de metadatos que se han generado a través del aprendizaje automático. o agregue información que aún no haya sido capturada. Crédito:Gonzalo Rodrigo, Laboratorio de Berkeley
"En el caso de los datos científicos, solo un puñado de expertos en el dominio puede crear conjuntos de capacitación y validar técnicas de aprendizaje automático, por lo que uno de los grandes problemas continuos que enfrentamos es una cantidad extremadamente pequeña de conjuntos de entrenamiento, "dice Weber, quien también es científico de planta en el CRD de Berkeley Lab.
Para superar este desafío, los investigadores del Berkeley Lab utilizaron el aprendizaje por transferencia para limitar los grados de libertad, o recuentos de parámetros, en sus redes neuronales convolucionales (CNN). El aprendizaje por transferencia es un método de aprendizaje automático en el que un modelo desarrollado para una tarea se reutiliza como punto de partida para un modelo en una segunda tarea. lo que permite al usuario obtener resultados más precisos con un conjunto de entrenamiento más pequeño. En el caso del microscopio TEAM I, los datos producidos contienen información sobre en qué modo de funcionamiento se encontraba el instrumento en el momento de la recopilación. Con esa información, Weber pudo entrenar a la red neuronal en esa clasificación para que pudiera generar esa etiqueta de modo de operación automáticamente. Luego congeló esa capa convolucional de la red, lo que significaba que solo tendría que volver a entrenar las capas densamente conectadas. Este enfoque reduce efectivamente la cantidad de parámetros en la CNN, permitiendo que el equipo obtenga resultados significativos a partir de sus datos de entrenamiento limitados.
Aprendizaje automático para minar el ecosistema científico
Además de generar etiquetas de metadatos a través de conjuntos de datos de entrenamiento, El equipo de Berkeley Lab también desarrolló herramientas que utilizan técnicas de aprendizaje automático para extraer el ecosistema científico para el contexto de datos. Por ejemplo, el módulo de ingesta de datos puede examinar una multitud de fuentes de información del ecosistema científico, incluidas las marcas de tiempo de los instrumentos, registros de usuario, propuestas y publicaciones, e identificar puntos en común. Las herramientas desarrolladas en Berkeley Lab que utilizan métodos de procesamiento del lenguaje natural pueden identificar y clasificar las palabras que dan contexto a los datos y facilitan resultados significativos para los usuarios más adelante. El usuario verá algo similar a la página de resultados de una búsqueda en Internet, donde el contenido con la mayor cantidad de texto que coincida con las palabras de búsqueda del usuario aparecerá más arriba en la página. El sistema también aprende de las consultas de los usuarios y de los resultados de búsqueda en los que hacen clic.
Dado que los instrumentos científicos están generando un conjunto de datos cada vez mayor, Todos los aspectos del motor de búsqueda científica del equipo de Berkeley debían ser escalables para mantener el ritmo de la velocidad y la escala de los volúmenes de datos que se producían. El equipo logró esto configurando su sistema en una instancia Spin en la supercomputadora Cori en el Centro Nacional de Computación Científica de Investigación Energética (NERSC). Spin es una tecnología de servicios de borde basada en Docker desarrollada en NERSC que puede acceder a los sistemas informáticos de alto rendimiento de la instalación y al almacenamiento en el back-end.
"Una de las razones por las que podemos crear una herramienta como Science Search es nuestro acceso a los recursos de NERSC, "dice Gonzalo Rodrigo, investigador postdoctoral de Berkeley Lab que trabaja en el procesamiento del lenguaje natural y los desafíos de infraestructura en Science Search. "Tenemos que almacenar, analizar y recuperar conjuntos de datos realmente grandes, y es útil tener acceso a una instalación de supercomputación para hacer el trabajo pesado de estas tareas. Spin de NERSC es una gran plataforma para ejecutar nuestro motor de búsqueda que es una aplicación de cara al usuario que requiere acceso a grandes conjuntos de datos y datos analíticos que solo se pueden almacenar en grandes sistemas de almacenamiento de supercomputación ".
Una interfaz para validar y buscar datos
Cuando el equipo de Berkeley Lab desarrolló la interfaz para que los usuarios interactuaran con su sistema, sabían que tendría que lograr un par de objetivos, incluida la búsqueda efectiva y permitiendo la participación humana en los modelos de aprendizaje automático. Debido a que el sistema se basa en expertos en el dominio para ayudar a generar los datos de entrenamiento y validar el resultado del modelo de aprendizaje automático, la interfaz necesaria para facilitar eso.
"La interfaz de etiquetado que desarrollamos muestra los datos originales y los metadatos disponibles, así como cualquier etiqueta generada por máquina que tengamos hasta ahora. Los usuarios expertos pueden examinar los datos y crear nuevas etiquetas y revisar las etiquetas generadas por la máquina para verificar su precisión. "dice Matt Henderson, quien es un ingeniero de sistemas informáticos en CRD y lidera el esfuerzo de desarrollo de la interfaz de usuario.
Para facilitar una búsqueda efectiva de usuarios basada en la información disponible, La interfaz de búsqueda del equipo proporciona un mecanismo de consulta para los archivos disponibles. propuestas y artículos de los que las herramientas de aprendizaje automático desarrolladas por Berkeley han analizado y extraído etiquetas. Cada elemento de resultado de búsqueda enumerado representa un resumen de esos datos, con una vista secundaria más detallada disponible, incluida información sobre las etiquetas que coincidían con este artículo. Actualmente, el equipo está explorando cómo incorporar mejor los comentarios de los usuarios para mejorar los modelos y las etiquetas.
"Tener la capacidad de explorar conjuntos de datos es importante para los avances científicos, y esta es la primera vez que se ha intentado algo como Science Search, ", dice Ramakrishnan." Nuestra visión final es construir las bases que eventualmente respaldarán un 'Google' para los datos científicos, donde los investigadores pueden incluso buscar conjuntos de datos distribuidos. Nuestro trabajo actual proporciona la base necesaria para lograr esa ambiciosa visión ".
"Berkeley Lab es realmente un lugar ideal para crear una herramienta como Science Search porque tenemos varias instalaciones para el usuario, como la Fundición Molecular, que tienen décadas de datos que proporcionarían aún más valor a la comunidad científica si los datos pudieran ser buscados y compartidos, "agrega Katie Antypas, quien es el investigador principal de Science Search y jefe del Departamento de Datos de NERSC. "Además, tenemos un gran acceso a la experiencia en aprendizaje automático en el Área de Ciencias de la Computación del Laboratorio de Berkeley, así como a los recursos de HPC en NERSC para desarrollar estas capacidades".