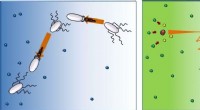
Investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) del MIT han diseñado un dispositivo que ayuda al almacenamiento flash barato a procesar gráficos masivos en una computadora personal. El dispositivo (que se muestra aquí) consta de una matriz de chips flash (ocho chips negros) y un "acelerador" de cálculo (pieza cuadrada directamente a la izquierda de la matriz). Un algoritmo novedoso clasifica todas las solicitudes de acceso a los datos del gráfico en un orden secuencial que parpadea puede acceder rápida y fácilmente, mientras combina algunas solicitudes para reducir la sobrecarga de clasificación. Crédito:Instituto de Tecnología de Massachusetts
En el lenguaje de la ciencia de datos, Los gráficos son estructuras de nodos y líneas de conexión que se utilizan para mapear puntuaciones de relaciones de datos complejas. El análisis de gráficos es útil para una amplia gama de aplicaciones, como clasificar páginas web, analizar las redes sociales en busca de ideas políticas, o trazar estructuras neuronales en el cerebro.
Consta de miles de millones de nodos y líneas, sin embargo, los gráficos grandes pueden alcanzar un tamaño de terabytes. Los datos del gráfico se procesan normalmente en una costosa memoria dinámica de acceso aleatorio (DRAM) en varios servidores que consumen mucha energía.
Investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) del MIT han diseñado ahora un dispositivo que usa almacenamiento flash barato, del tipo que se usa en los teléfonos inteligentes, para procesar gráficos masivos usando una sola computadora personal.
El almacenamiento flash suele ser mucho más lento que la DRAM en el procesamiento de datos gráficos. Pero los investigadores desarrollaron un dispositivo que consta de una matriz de chips flash y un "acelerador de cómputo, "que ayuda a flash a lograr un rendimiento similar al de la DRAM.
La alimentación del dispositivo es un algoritmo novedoso que ordena todas las solicitudes de acceso a los datos del gráfico en un orden secuencial al que Flash puede acceder rápida y fácilmente. También fusiona algunas solicitudes para reducir la sobrecarga:el tiempo de cálculo combinado, memoria, banda ancha, y otros recursos informáticos — de clasificación.
Los investigadores ejecutaron el dispositivo contra varios sistemas tradicionales de alto rendimiento que procesan varios gráficos grandes, incluido el enorme gráfico de hipervínculos de Web Data Commons, que tiene 3.5 mil millones de nodos y 128 mil millones de líneas de conexión. Para procesar ese gráfico, todos los sistemas tradicionales requerían un servidor que costaba miles de dólares y contenía 128 gigabytes de DRAM. Los investigadores lograron el mismo rendimiento conectando dos de sus dispositivos, por un total de 1 gigabyte de DRAM y 1 terabyte de flash, en una computadora de escritorio. Es más, combinando varios dispositivos, podían procesar gráficos masivos (hasta 4 mil millones de nodos y 128 mil millones de líneas de conexión) que ningún otro sistema podría manejar en el servidor de 128 gigabytes.
"La conclusión es que podemos mantener el rendimiento con mucho más pequeño, menos, y más frías, como en temperatura y consumo de energía, máquinas, "dice Sang-Woo Jun, un estudiante graduado de CSAIL y primer autor de un artículo que describe el dispositivo, que se presenta en el Simposio Internacional de Arquitectura de Computadoras (ISCA).
El dispositivo podría usarse para reducir los costos y la energía asociados con el análisis de gráficos, e incluso mejorar el rendimiento, en una amplia gama de aplicaciones. Los investigadores, por ejemplo, actualmente están creando un programa que podría identificar genes que causan cánceres. Las principales empresas de tecnología como Google también podrían aprovechar los dispositivos para reducir su huella energética utilizando muchas menos máquinas para ejecutar análisis.
"El procesamiento de gráficos es una idea tan general, "dice el coautor Arvind, el profesor Johnson en Ingeniería en Ciencias de la Computación. "¿Qué tienen en común el ranking de páginas con la detección de genes? Para nosotros, es el mismo problema de cálculo, solo diferentes gráficos con diferentes significados. El tipo de aplicación que alguien desarrolle determinará el impacto que tiene en la sociedad ".
Los coautores del artículo son el estudiante graduado de CSAIL Shuotao Xu, y Andy Wright y Sizhuo Zhang, dos estudiantes de posgrado en CSAIL y el Departamento de Ingeniería Eléctrica e Informática.
Los investigadores pudieron procesar varios gráficos grandes, con hasta 3.5 mil millones de nodos y 128 mil millones de líneas de conexión, conectando dos de sus dispositivos, totalizando 1 gigabyte de DRAM y 1 terabyte de flash, en una computadora de escritorio. Todos los sistemas tradicionales requerían un servidor que costaba miles de dólares y contenía 128 gigabytes de DRAM para procesar los gráficos. Crédito:Instituto de Tecnología de Massachusetts
Clasificar y reducir
En análisis de gráficos, un sistema básicamente buscará y actualizará el valor de un nodo en función de sus conexiones con otros nodos, entre otras métricas. En el ranking de páginas web, por ejemplo, cada nodo representa una página web. Si el nodo A tiene un valor alto y se conecta al nodo B, entonces el valor del nodo B también aumentará.
Los sistemas tradicionales almacenan todos los datos gráficos en DRAM, lo que los hace rápidos en el procesamiento de datos, pero también caros y con gran consumo de energía. Algunos sistemas descargan parte del almacenamiento de datos en flash, que es más barato pero más lento y menos eficiente, por lo que todavía requieren cantidades sustanciales de DRAM.
El dispositivo de los investigadores funciona con lo que los investigadores llaman un algoritmo de "clasificación y reducción", lo que resuelve un problema importante con el uso de flash como fuente de almacenamiento principal:los desechos.
Los sistemas de análisis de gráficos requieren acceso a nodos que pueden estar muy lejos unos de otros a través de un estructura de gráfico escasa. Los sistemas generalmente solicitan acceso directo a, decir, 4 a 8 bytes de datos para actualizar el valor de un nodo. DRAM proporciona ese acceso directo muy rápidamente. Destello, sin embargo, solo accede a datos en fragmentos de 4 a 8 kilobytes, pero aún actualiza solo unos pocos bytes. Repetir ese acceso para cada solicitud mientras se salta a través del gráfico desperdicia ancho de banda. "Si necesita acceder a los 8 kilobytes completos, y usa solo 8 bytes y tira el resto, terminas tirando 1, 000 veces el rendimiento de distancia, "Dice Jun.
En cambio, el algoritmo de clasificación y reducción toma todas las solicitudes de acceso directo y las clasifica en orden secuencial por identificadores, que muestran el destino de la solicitud, como agrupar todas las actualizaciones para el nodo A, todo para el nodo B, etcétera. Flash puede acceder a fragmentos del tamaño de un kilobyte de miles de solicitudes a la vez, haciéndolo mucho más eficiente.
Para ahorrar aún más potencia de cálculo y ancho de banda, el algoritmo fusiona simultáneamente los datos en las agrupaciones más pequeñas posibles. Siempre que el algoritmo observe identificadores coincidentes, los suma en un solo paquete de datos, como A1 y A2 que se convierten en A3. Sigue haciéndolo, crear paquetes de datos cada vez más pequeños con identificadores coincidentes, hasta que produzca el paquete más pequeño posible para clasificar. Esto reduce drásticamente la cantidad de solicitudes duplicadas para acceder.
Usando el algoritmo ordenar-reducir en dos gráficos grandes, los investigadores redujeron el total de datos que debían actualizarse en flash en aproximadamente un 90 por ciento.
Descarga de cálculo
El algoritmo de clasificación y reducción requiere un uso intensivo de cálculos para una computadora host, sin embargo, por lo que los investigadores implementaron un acelerador personalizado en el dispositivo. El acelerador actúa como un punto intermedio entre el host y los chips flash, ejecutando todos los cálculos para el algoritmo. Esto descarga tanta potencia al acelerador que el host puede ser una PC o computadora portátil de baja potencia que administra datos ordenados y ejecuta otras tareas menores.
"Se supone que los aceleradores ayudan al host a calcular, pero hemos llegado tan lejos [con los cálculos] que el host deja de ser importante, "Dice Arvind.
"El trabajo del MIT muestra una nueva forma de realizar análisis en gráficos muy grandes:su trabajo explota la memoria flash para almacenar los gráficos y explota 'matrices de puertas programables en campo' [circuitos integrados personalizados] de una manera ingeniosa para realizar tanto el análisis como el procesamiento de datos necesario para utilizar la memoria flash de forma eficaz, "dice Keshav Pingali, profesor de informática en la Universidad de Texas en Austin. "A la larga, esto puede conducir a sistemas que pueden procesar grandes cantidades de datos de manera eficiente en computadoras portátiles o de escritorio, lo que revolucionará la forma en que hacemos el procesamiento de macrodatos ".
Debido a que el host puede tener tan poca potencia, Jun dice, un objetivo a largo plazo es crear una plataforma de propósito general y una biblioteca de software para que los consumidores desarrollen sus propios algoritmos para aplicaciones más allá del análisis de gráficos. "Podrías conectar esta plataforma a una computadora portátil, descargar [el software], y escriba programas simples para obtener un rendimiento de clase servidor en su computadora portátil, " él dice.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.