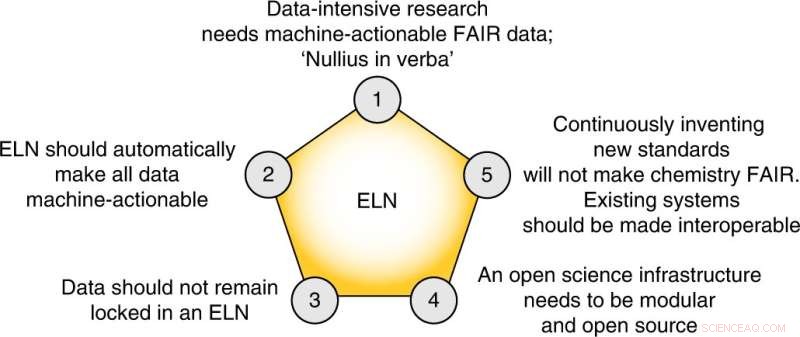
Las cinco tesis centrales de esta perspectiva. Crédito:Química de la naturaleza (2022). DOI:10.1038/s41557-022-00910-7
Uno de los aspectos más desafiantes de la química moderna es la gestión de datos. Por ejemplo, al sintetizar un nuevo compuesto, los científicos realizarán múltiples intentos de prueba y error para encontrar las condiciones adecuadas para la reacción, generando en el proceso cantidades masivas de datos sin procesar. Estos datos tienen un valor increíble, ya que, al igual que los humanos, los algoritmos de aprendizaje automático pueden aprender mucho de experimentos fallidos y parcialmente exitosos.
Sin embargo, la práctica actual es publicar solo los experimentos más exitosos, ya que ningún ser humano puede procesar de manera significativa la gran cantidad de experimentos fallidos. Pero la IA ha cambiado esto; es exactamente lo que pueden hacer estos métodos de aprendizaje automático, siempre que los datos se almacenen en un formato procesable por máquina para que cualquiera pueda usarlos.
"Durante mucho tiempo, necesitábamos comprimir la información debido al número limitado de páginas en los artículos de revistas impresas", dice el profesor Berend Smit, director del Laboratorio de Simulación Molecular de la EPFL Valais Wallis. "Hoy en día, muchas revistas ya ni siquiera tienen ediciones impresas; sin embargo, los químicos todavía luchan con problemas de reproducibilidad porque a los artículos de las revistas les faltan detalles cruciales. Los investigadores 'pierden' tiempo y recursos replicando experimentos 'fallidos' de los autores y luchan por construir sobre la base de resultados publicados ya que los datos sin procesar rara vez se publican".
Pero el volumen no es el único problema aquí; la diversidad de datos es otra:los grupos de investigación utilizan diferentes herramientas como el software Electronic Lab Notebook, que almacena datos en formatos propietarios que a veces son incompatibles entre sí. Esta falta de estandarización hace que sea casi imposible que los grupos compartan datos.
Ahora, Smit, con Luc Patiny y Kevin Jablonka en EPFL, han publicado una perspectiva en Nature Chemistry presentando una plataforma abierta para todo el flujo de trabajo de la química:desde el inicio de un proyecto hasta su publicación.
Los científicos visualizan la plataforma como una integración "perfecta" de tres pasos cruciales:recopilación de datos, procesamiento de datos y publicación de datos, todo con un costo mínimo para los investigadores. El principio rector es que los datos deben ser JUSTOS:fáciles de encontrar, accesibles, interoperables y reutilizables. "En el momento de la recopilación de datos, los datos se convertirán automáticamente a un formato FAIR estándar, lo que permitirá publicar automáticamente todos los experimentos 'fallidos' y parcialmente exitosos junto con el experimento más exitoso", dice Smit.
Pero los autores van un paso más allá y proponen que los datos también deberían ser procesables por máquinas. "Estamos viendo cada vez más estudios de ciencia de datos en química", dice Jablonka. "De hecho, los resultados recientes en el aprendizaje automático intentan abordar algunos de los problemas que los químicos creen que no tienen solución. Por ejemplo, nuestro grupo ha logrado un enorme progreso en la predicción de las condiciones de reacción óptimas utilizando modelos de aprendizaje automático. Pero esos modelos serían mucho más valiosos si también podría aprender las condiciones de reacción que fallan, pero de lo contrario, siguen estando sesgadas porque solo se publican las condiciones exitosas".
Finalmente, los autores proponen cinco pasos concretos que el campo debe tomar para crear un plan de gestión de datos FAIR:
"Creemos que no hay necesidad de inventar nuevos formatos de archivo o tecnologías", dice Patiny. "En principio, toda la tecnología está ahí y debemos adoptar las tecnologías existentes y hacerlas interoperables".
Los autores también señalan que el simple hecho de almacenar datos en cualquier cuaderno de laboratorio electrónico, la tendencia actual, no significa necesariamente que los humanos y las máquinas puedan reutilizar los datos. Más bien, los datos deben estar estructurados y publicados en un formato estandarizado, y también deben contener suficiente contexto para permitir acciones basadas en datos.
"Nuestra perspectiva ofrece una visión de lo que creemos que son los componentes clave para cerrar la brecha entre los datos y el aprendizaje automático para los problemas centrales de la química", dice Smit. "También proporcionamos una solución de ciencia abierta en la que la EPFL puede tomar la iniciativa". El aprendizaje automático descifra los estados de oxidación de las estructuras cristalinas