Los investigadores del MIT combinaron la química experimental con la inteligencia artificial para descubrir péptidos altamente activos que se pueden unir a oligómeros de fosforodiamidato morfolino (PMO) para ayudar a la administración de fármacos. Al desarrollar estas nuevas secuencias, Los investigadores esperan acelerar rápidamente el desarrollo de terapias genéticas para la distrofia muscular de Duchenne y otras enfermedades. Crédito:Instituto de Tecnología de Massachusetts
Distrofia muscular de Duchenne (DMD), una enfermedad genética rara generalmente diagnosticada en niños pequeños, gradualmente debilita los músculos de todo el cuerpo hasta que el corazón o los pulmones fallan. Los síntomas suelen aparecer a los 5 años; a medida que avanza la enfermedad, los pacientes pierden la capacidad de caminar alrededor de los 12 años. la esperanza de vida promedio de los pacientes con DMD ronda los 26.
Fue una gran noticia luego, cuando Cambridge, Sarepta Therapeutics, con sede en Massachusetts, anunció en 2019 un fármaco revolucionario que se dirige directamente al gen mutado responsable de la DMD. La terapia utiliza oligómeros morfolino fosforodiamidato antisentido (PMO), una gran molécula sintética que impregna el núcleo celular para modificar el gen de la distrofina, permitiendo la producción de una proteína clave que normalmente falta en los pacientes con DMD. "Pero hay un problema con la PMO en sí misma. No es muy buena para ingresar a las células, "dice Carly Schissel, un doctorado candidato en el Departamento de Química del MIT.
Para impulsar la entrega al núcleo, los investigadores pueden fijar péptidos penetrantes de células (CPP) al fármaco, ayudándolo así a cruzar la célula y las membranas nucleares para alcanzar su objetivo. Qué secuencia de péptidos es mejor para el trabajo, sin embargo, sigue siendo una cuestión inminente.
Los investigadores del MIT ahora han desarrollado un enfoque sistemático para resolver este problema mediante la combinación de la química experimental con la inteligencia artificial para descubrir no tóxicos, péptidos altamente activos que se pueden unir a la PMO para ayudar a la administración. Al desarrollar estas nuevas secuencias, esperan acelerar rápidamente el desarrollo de terapias genéticas para la DMD y otras enfermedades.
Los resultados de su estudio ahora se han publicado en la revista Química de la naturaleza en un artículo dirigido por Schissel y Somesh Mohapatra, un doctorado estudiante en el Departamento de Ciencia e Ingeniería de Materiales del MIT, quienes son los autores principales. Rafael Gómez-Bombarelli, profesor asistente de ciencia e ingeniería de materiales, y Bradley Pentelute, profesor de química, son los autores principales del artículo. Otros autores incluyen a Justin Wolfe, Colin Fadzen, Kamela Bellovoda, Chia-Ling Wu, Jenna Wood, Annika Malmberg, y Andrei Loas.
"Proponer nuevos péptidos con una computadora no es muy difícil. Juzgar si son buenos o no, esto es lo difícil ", dice Gomez-Bombarelli." La innovación clave es utilizar el aprendizaje automático para conectar la secuencia de un péptido, particularmente un péptido que incluye aminoácidos no naturales, a la actividad biológica medida experimentalmente ".
Datos de ensueño
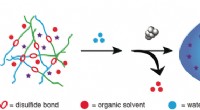
Los CPP son cadenas relativamente cortas, compuesto por entre cinco y 20 aminoácidos. Si bien un CPP puede tener un impacto positivo en la administración de medicamentos, varios enlazados entre sí tienen un efecto sinérgico en el transporte de drogas hasta la línea de meta. Estas cadenas más largas que contiene de 30 a 80 aminoácidos, se llaman miniproteínas.
Antes de que un modelo pudiera hacer predicciones valiosas, Los investigadores del lado experimental necesitaban crear un conjunto de datos robusto. Al mezclar y combinar 57 péptidos diferentes, Schissel y sus colegas pudieron construir una biblioteca de 600 miniproteínas, cada uno adjunto a PMO. Con un ensayo, el equipo pudo cuantificar qué tan bien cada miniproteína podía mover su carga a través de la celda.
La decisión de probar la actividad de cada secuencia, con la PMO ya adjunta, era importante. Dado que es probable que cualquier fármaco cambie la actividad de una secuencia de CPP, es difícil reutilizar los datos existentes, y datos generados en un solo laboratorio, en las mismas maquinas, por la misma gente, cumplen con un estándar de oro para la coherencia en los conjuntos de datos de aprendizaje automático.
Uno de los objetivos del proyecto era crear un modelo que pudiera funcionar con cualquier aminoácido. Si bien solo 20 aminoácidos se encuentran naturalmente en el cuerpo humano, existen cientos más en otros lugares, como un paquete de expansión de aminoácidos para el desarrollo de fármacos. Para representarlos en un modelo de aprendizaje automático, los investigadores suelen utilizar la codificación one-hot, un método que asigna cada componente a una serie de variables binarias. Tres aminoácidos, por ejemplo, se representaría como 100, 010, y 001. Para agregar nuevos aminoácidos, el número de variables debería aumentar, lo que significa que los investigadores estarían atascados en tener que reconstruir su modelo con cada adición.
En lugar de, el equipo optó por representar los aminoácidos con huellas dactilares topológicas, que básicamente crea un código de barras único para cada secuencia, con cada línea en el código de barras indicando la presencia o ausencia de una subestructura molecular particular. "Incluso si el modelo no ha visto [una secuencia] antes, podemos representarlo como un código de barras, que es consistente con las reglas que el modelo ha visto, "dice Mohapatra, quien dirigió los esfuerzos de desarrollo del proyecto. Al utilizar este sistema de representación, los investigadores pudieron ampliar su caja de herramientas de posibles secuencias.
El equipo entrenó una red neuronal convolucional en la biblioteca de miniproteínas, con cada una de las 600 miniproteínas etiquetadas con su actividad, indicando su capacidad para penetrar en la célula. Temprano, el modelo propuesto miniproteínas cargadas con arginina, un aminoácido que abre un agujero en la membrana celular, lo cual no es ideal para mantener vivas las células. Para solucionar este problema, los investigadores utilizaron un optimizador para descentivizar la arginina, evitar que el modelo haga trampas.
En el final, la capacidad de interpretar las predicciones propuestas por el modelo fue clave. "Por lo general, no es suficiente tener una caja negra, porque los modelos podrían estar fijándose en algo que no es correcto, o porque podría estar explotando un fenómeno de forma imperfecta, "Dice Gómez-Bombarelli.
En este caso, los investigadores podrían superponer las predicciones generadas por el modelo con el código de barras que representa la estructura de la secuencia. "Hacer eso resalta ciertas regiones que, según el modelo, juegan el papel más importante en la alta actividad, ", Dice Schissel." No es perfecto, pero te ofrece regiones enfocadas para jugar. That information would definitely help us in the future to design new sequences empirically."
Delivery boost
Por último, the machine-learning model proposed sequences that were more effective than any previously known variant. One in particular can boost PMO delivery by 50-fold. By injecting mice with these computer-suggested sequences, the researchers validated their predictions and demonstrated that the miniproteins are nontoxic.
It is too early to tell how this work will affect patients down the line, but better PMO delivery will be beneficial in several ways. If patients are exposed to lower levels of the drug, they may experience fewer side effects, por ejemplo, or require less-frequent doses (PMO is administered intravenously, often on a weekly basis). The treatment may also become less costly. As a testament to the concept, recent clinical trials demonstrated that a proprietary CPP from Sarepta Therapeutics could decrease exposure to PMO by 10-fold. También, PMO is not the only drug that stands to be improved by miniproteins. In additional experiments, the model-generated miniproteins carried other functional proteins into the cell.
Noticing a disconnect between the work of machine-learning researchers and experimental chemists, Mohapatra has posted the model on GitHub, along with a tutorial for experimentalists who have their own list of sequences and activities. He notes that over a dozen people from across the world have adopted the model so far, repurposing it to make their own powerful predictions for a wide range of drugs.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.