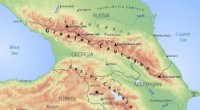
Un ejemplo de cómo el brazo robótico usa preguntas de encuesta para determinar las preferencias de la persona que lo usa. En este caso, la persona prefiere la trayectoria # 1 (T1) sobre la trayectoria # 2. Crédito:Andy Palan y Gleb Shevchuk
Se le dijo que optimizara la velocidad mientras corría por una pista en un juego de computadora, un coche empuja el pedal hasta el fondo… y procede a girar en un pequeño círculo cerrado. Nada en las instrucciones le dijo al auto que condujera en línea recta. y así improvisó.
Este ejemplo, divertido en un juego de computadora pero no tanto en la vida, es uno de los que motivó a los investigadores de la Universidad de Stanford a construir una mejor manera de establecer metas para los sistemas autónomos.
Dorsa Sadigh, profesor asistente de informática y de ingeniería eléctrica, y su laboratorio han combinado dos formas diferentes de establecer objetivos para los robots en un solo proceso, que funcionó mejor que cualquiera de sus partes por sí sola tanto en simulaciones como en experimentos del mundo real. Los investigadores presentaron el trabajo el 24 de junio en el Robótica:ciencia y sistemas conferencia.
"En el futuro, Espero que haya más sistemas autónomos en el mundo y van a necesitar algún concepto de lo que es bueno y lo que es malo. "dijo Andy Palan, estudiante de posgrado en informática y coautor principal del artículo. "Es crucial, si queremos implementar estos sistemas autónomos en el futuro, que lo hacemos bien ".
El nuevo sistema del equipo para proporcionar instrucción a los robots, conocido como funciones de recompensa, combina demostraciones, en el que los humanos le muestran al robot lo que debe hacer, y encuestas de preferencias de los usuarios, en el que las personas responden preguntas sobre cómo quieren que se comporte el robot.
"Las demostraciones son informativas, pero pueden ser ruidosas. Por otro lado, las preferencias proporcionan, a lo sumo, un poco de información, pero son mucho más precisos, ", dijo Sadigh." Nuestro objetivo es obtener lo mejor de ambos mundos, y combinar datos provenientes de ambas fuentes de manera más inteligente para conocer mejor la función de recompensa preferida por los humanos ".
Demostraciones y encuestas
En trabajos anteriores, Sadigh se había centrado únicamente en las encuestas de preferencias. Estos piden a las personas que comparen escenarios, como dos trayectorias para un coche autónomo. Este método es eficiente, pero podría tardar hasta tres minutos en generar la siguiente pregunta, que todavía es lento para crear instrucciones para sistemas complejos como un automóvil.
Para acelerar eso, Posteriormente, el grupo desarrolló una forma de producir múltiples preguntas a la vez, que podría ser contestada en rápida sucesión por una persona o distribuida entre varias personas. Esta actualización aceleró el proceso de 15 a 50 veces en comparación con la producción de preguntas una por una.
El nuevo sistema de combinación comienza con una persona que le demuestra un comportamiento al robot. Eso puede dar mucha información a los robots autónomos, pero el robot a menudo se esfuerza por determinar qué partes de la demostración son importantes. La gente tampoco siempre quiere que un robot se comporte como el humano que lo entrenó.
"No siempre podemos hacer demostraciones, e incluso cuando podamos, a menudo no podemos confiar en la información que la gente da, "dijo Erdem Biyik, un estudiante de posgrado en ingeniería eléctrica que dirigió el trabajo de desarrollo de las encuestas de preguntas múltiples. "Por ejemplo, estudios anteriores han demostrado que la gente quiere que los coches autónomos conduzcan de forma menos agresiva que ellos mismos ".
Ahí es donde entran las encuestas, dándole al robot una forma de preguntar, por ejemplo, ya sea que el usuario lo prefiera, mueva el brazo hacia el suelo o hacia el techo. Para este estudio, el grupo utilizó el método más lento de una sola pregunta, pero planean integrar encuestas de preguntas múltiples en trabajos posteriores.
En pruebas, el equipo descubrió que combinar demostraciones y encuestas era más rápido que solo especificar preferencias y, en comparación con las demostraciones solas, alrededor del 80 por ciento de las personas prefirieron cómo se comportaba el robot cuando se entrenaba con el sistema combinado.
"Este es un paso para comprender mejor lo que la gente quiere o espera de un robot, ", dijo Sadigh." Nuestro trabajo hace que sea más fácil y más eficiente para los humanos interactuar y enseñar a los robots, y estoy emocionado de llevar este trabajo más lejos, particularmente en el estudio de cómo los robots y los humanos pueden aprender unos de otros ".
Mejor, más rápido, mas inteligente
Las personas que utilizaron el método combinado informaron tener dificultades para comprender a qué se refería el sistema con algunas de sus preguntas, que a veces les pedía que seleccionaran entre dos escenarios que parecían iguales o parecían irrelevantes para la tarea, un problema común en el aprendizaje basado en preferencias. Los investigadores esperan abordar esta deficiencia con encuestas más sencillas que también funcionan más rápidamente.
"Mirando hacia el futuro, no es 100% obvio para mí cuál es la forma correcta de realizar funciones de recompensa, pero, de manera realista, tendrá algún tipo de combinación que pueda abordar situaciones complejas con participación humana, ", dijo Palan." Ser capaz de diseñar funciones de recompensa para sistemas autónomos es un gran, problema importante que no ha recibido la atención académica que se merece ".
El equipo también está interesado en una variación de su sistema, lo que permitiría a las personas crear simultáneamente funciones de recompensa para diferentes escenarios. Por ejemplo, una persona puede querer que su automóvil conduzca de manera más conservadora en tráfico lento y de manera más agresiva cuando el tráfico es ligero.
Cuando las demostraciones fallan
A veces, las demostraciones por sí solas no logran transmitir el objetivo de una tarea. Por ejemplo, una demostración en este estudio hizo que las personas enseñaran al brazo del robot a moverse hasta que apuntó a un lugar específico en el suelo, y hacerlo evitando un obstáculo y sin moverse por encima de una determinada altura.
Después de que un humano corriera al robot a través de sus pasos durante 30 minutos, el robot intentó realizar la tarea de forma autónoma. Simplemente apuntó hacia arriba. Estaba tan concentrado en aprender a no golpear el obstáculo, no alcanzó por completo el objetivo real de la tarea, señalar el lugar, y la preferencia por mantenerse agachado.
Codificación manual y piratería de recompensas
Otra forma de enseñarle a un robot es escribir código que actúe como instrucciones. El desafío es explicar exactamente lo que quiere que haga un robot, especialmente si la tarea es compleja. Un problema común se conoce como "piratería de recompensas, "donde el robot descubre una manera más fácil de alcanzar los objetivos especificados, como que el automóvil gire en círculos para lograr el objetivo de ir rápido.
Biyik experimentó el hackeo de recompensas cuando estaba programando un brazo robótico para agarrar un cilindro y sostenerlo en el aire.
"Le dije que la mano debe estar cerrada, el objeto debe tener una altura superior a X y la mano debe estar a la misma altura, "describió Biyik." El robot hizo rodar el objeto cilíndrico hasta el borde de la mesa, lo golpeó hacia arriba y luego hizo un puño junto a él en el aire ".