Crédito:arXiv:1905.09773 [cs.CV]
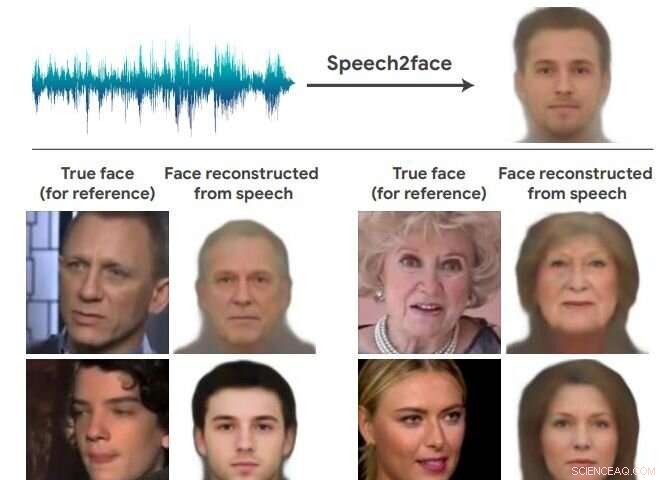
Una vez más, Los equipos de inteligencia artificial se burlan del reino de lo imposible y ofrecen resultados sorprendentes. Este equipo en las noticias descubrió cómo se vería la cara de una persona simplemente basándose en la voz. Bienvenido a Speech2Face. El equipo de investigación encontró una manera de reconstruir la semejanza muy aproximada de algunas personas basándose en clips de audio cortos.
El documento que describe su trabajo está en arXiv, y se titula "Speech2Face:Aprendiendo el rostro detrás de una voz". Los autores son Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William Freemany, Michael Rubinstein y Wojciech Matusiky. "Nuestro objetivo en este trabajo es estudiar hasta qué punto podemos inferir cómo se ve una persona a partir de su forma de hablar".
Evalúan y cuantifican numéricamente cómo, y de que manera, sus reconstrucciones de Speech2Face a partir de audio se asemejan a las verdaderas imágenes faciales de los altavoces.
Los autores aparentemente querían asegurarse de que su intención fuera clara, no como un intento de vincular voces con imágenes de personas específicas que realmente hablaron, ya que "nuestro objetivo no es predecir una imagen reconocible del rostro exacto, sino más bien para capturar los rasgos faciales dominantes de la persona que se correlacionan con el discurso de entrada ".
Los autores de GitHub dijeron que también sentían que era importante discutir en el artículo las consideraciones éticas "debido a la posible sensibilidad de la información facial".
Dijeron en su artículo que su método "no puede recuperar la verdadera identidad de una persona a partir de su voz (es decir, una imagen exacta de su rostro). Esto se debe a que nuestro modelo está capacitado para capturar características visuales (relacionadas con la edad, género, etc.) que son comunes a muchas personas, y solo en los casos en que exista evidencia suficientemente sólida para conectar esas características visuales con los atributos vocales / del habla en los datos ".
También dijeron que el modelo producirá caras de apariencia promedio, solo caras de apariencia promedio, con rasgos visuales característicos correlacionados con el habla de entrada.
Jackie Snow, Empresa rápida , escribió sobre su método. Snow dijo que el conjunto de datos que tomaron estaba compuesto por clips de YouTube. Speech2Face fue capacitado por científicos en videos de Internet que mostraban a personas hablando. Crearon un modelo basado en una red neuronal que "aprende los atributos vocales asociados con los rasgos faciales de los videos".
Snow agregó, "Ahora, cuando el sistema escucha un nuevo fragmento de sonido, la IA puede usar lo que ha aprendido para adivinar cómo se vería la cara ".
Neurohive habló sobre su trabajo:"De los videos, extraen pares habla-rostro, que se alimentan en dos ramas de la arquitectura. Las imágenes se codifican en un vector latente utilizando el modelo de reconocimiento facial preentrenado, mientras que la forma de onda se alimenta a un codificador de voz en forma de espectrograma, para utilizar el poder de las arquitecturas convolucionales. El vector codificado del codificador de voz se alimenta al decodificador de rostros para obtener la reconstrucción de rostros final ".
También se puede obtener un informe preciso sobre su método y cómo lo probaron con un artículo sobre Packt :
"Dijeron que evaluaron y cuantificaron numéricamente cómo reconstruye su Speech2Face, obtiene resultados directamente del audio, y cómo se asemeja a las verdaderas imágenes faciales de los oradores. Para esto, probaron su modelo tanto cualitativa como cuantitativamente en el conjunto de datos AVSpeech y el conjunto de datos VoxCeleb ".
¿Cómo podrían sus hallazgos ayudar a las aplicaciones del mundo real? Ellos dijeron, "Creemos que la predicción de imágenes faciales directamente desde la voz puede admitir aplicaciones útiles, como adjuntar un rostro representativo a las llamadas telefónicas o de video en función de la voz del orador ".
Por qué su trabajo es importante:Piense en patrones. "Investigaciones anteriores han explorado métodos para predecir la edad y el género a partir del habla, "dijo Snow, "pero en este caso, los investigadores afirman que también han detectado correlaciones con algunos patrones faciales ".
© 2019 Science X Network