Crédito:Prasad, Das y Bhowmick.
Investigadores del grupo Embedded Systems and Robotics de TCS Research &Innovation han desarrollado recientemente una red de profundidad de dos vistas para inferir la profundidad y el movimiento del ego a partir de secuencias monoculares consecutivas. Su enfoque presentado en un artículo publicado previamente en arXiv, también incorpora restricciones epipolares, que mejoran la comprensión geométrica de la red.
"Nuestra idea principal era intentar predecir la profundidad de píxeles y el movimiento de la cámara directamente a partir de secuencias de imágenes individuales, "Dr. Brojeshwar Bhowmick, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Tradicionalmente, La estructura de los algoritmos de reconstrucción basados en el movimiento proporciona salidas de profundidad escasa para puntos de interés destacados en la imagen, que se rastrean sobre varias imágenes utilizando geometría de múltiples vistas. Con el aprendizaje profundo ganando popularidad en las tareas de visión por computadora, pensamos en aprovechar los métodos existentes para ayudar a nuestra causa abordando el problema de una manera más fundamental utilizando una combinación de conceptos de la geometría epipolar y el aprendizaje profundo ".
La mayoría de los enfoques de aprendizaje profundo existentes para predecir la profundidad monocular y el movimiento del ego optimizan la consistencia fotométrica en las secuencias de imágenes al deformar una vista en otra. Al inferir la profundidad de una sola vista, sin embargo, estos métodos pueden fallar en capturar la relación entre píxeles y por lo tanto proporcionar correspondencias de píxeles adecuadas.
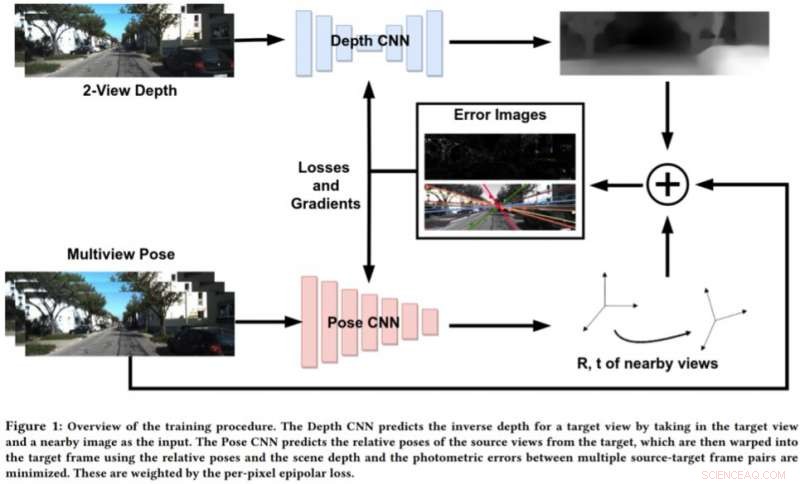
Para abordar las limitaciones de estos enfoques, Bhowmick y sus colegas desarrollaron un nuevo enfoque que combina la visión geométrica por computadora y los paradigmas de aprendizaje profundo. Su enfoque utiliza dos redes neuronales, uno para predecir la profundidad de una única vista de referencia y otro para predecir las poses relativas de un conjunto de vistas con respecto a la vista de referencia.

Crédito:Prasad, Das y Bhowmick.
"La escena de la imagen de destino se puede reconstruir a partir de cualquiera de las poses dadas al deformarlas según la profundidad y las poses relativas, ", Explicó Bhowmick." Dada esta imagen reconstruida y la imagen de referencia, calculamos el error en las intensidades de píxeles, que actúa como nuestra principal pérdida. Agregamos la novedad de utilizar la pérdida epipolar por píxel, un concepto de geometría multivista, en la pérdida total, lo que asegura mejores correspondencias y tiene la ventaja adicional de descontar los objetos en movimiento en la escena que de otra manera pueden deteriorar el aprendizaje ".
En lugar de predecir la profundidad analizando una sola imagen, este nuevo enfoque funciona analizando un par de imágenes de un video y aprendiendo las relaciones entre píxeles para predecir la profundidad. Se parece un poco a los algoritmos SLAM / SfM tradicionales, que puede observar los movimientos de los píxeles a lo largo del tiempo.
"Los hallazgos más significativos de nuestro estudio son que usar dos vistas para predecir la profundidad funciona mejor que una sola imagen, y que incluso una aplicación débil de las correspondencias de nivel de píxeles a través de restricciones epipolares funciona bien, ", Dijo Bhowmick." Una vez que dichos métodos maduran y mejoran la generalización, podríamos aplicarlos para la percepción en drones, donde uno querría extraer la máxima información sensorial consumiendo la menor cantidad de energía posible, que se puede lograr utilizando una sola cámara ".
En evaluaciones preliminares, los investigadores encontraron que su método podía predecir la profundidad con mayor precisión que los enfoques existentes, produciendo estimaciones de profundidad más precisas y estimaciones de pose mejoradas. Sin embargo, en la actualidad, su enfoque solo puede realizar inferencias a nivel de píxel. El trabajo futuro podría abordar esta limitación integrando la semántica de la escena en el modelo, lo que podría conducir a mejores correlaciones entre los objetos en la escena y estimaciones de profundidad y movimiento del ego.
"Estamos investigando más a fondo la posibilidad de generalizar este método y otros métodos similares en varias escenas, tanto en interiores como en exteriores, ", Dijo Bhowmick." Actualmente, la mayoría de los trabajos funcionan bien con datos exteriores, como datos de conducción, pero funcionan muy mal en secuencias en interiores con movimientos arbitrarios ".
© 2019 Science X Network