Crédito:CC0 Public Domain
Los libros pueden arder. Las computadoras son pirateadas. Los DVD se degradan. Tecnologías para almacenar información:tinta sobre papel, ordenadores, CD y DVD, e incluso el ADN, continúan mejorando. Y todavía, Las amenazas tan simples como el agua y tan complejas como los ciberataques pueden dañar nuestros registros.
A medida que el auge de los datos continúa en auge, cada vez se archiva más información en cada vez menos espacio. Incluso la nube, cuyo nombre promete opaco, espacio infinito:eventualmente se quedará sin espacio, no puede frustrar a todos los piratas informáticos, y devora energía. Ahora, una nueva forma de almacenar información podría albergar datos de forma estable durante millones de años, vive fuera de Internet pirateable, y, una vez escrito, no utiliza energía. Todo lo que necesitas es un químico algunas moléculas baratas, y tu valiosa información.
"Piense en almacenar el contenido de la Biblioteca Pública de Nueva York con una cucharadita de proteína, "dice Brian Cafferty, primer autor del artículo que describe la nueva técnica y becario postdoctoral en el laboratorio de George Whitesides, el profesor de la Universidad Woodford L. y Ann A. Flowers en la Universidad de Harvard. El trabajo se realizó en colaboración con Milan Mrksich y su grupo en la Northwestern University.
"Al menos en esta etapa, no vemos que este método compita con los métodos existentes de almacenamiento de datos, ", Dice Cafferty." En cambio, lo vemos como un complemento de esas tecnologías y, como objetivo inicial, muy adecuado para el almacenamiento de datos de archivo a largo plazo ".
Es posible que la herramienta química de Cafferty no reemplace a la nube. Pero el sistema de archivo ofrece una atractiva alternativa a las herramientas de almacenamiento biológico como el ADN. Recientemente, Los científicos descubrieron cómo manipular a nuestro fiel guardián de la información genética para codificar algo más que el color de los ojos. Los investigadores ahora pueden sintetizar cadenas de ADN para registrar cualquier información, incluyendo videos de gatos, tendencias dietéticas, y tutoriales de cocina (si deberían hacerlo es otra cuestión).
Pero si bien el ADN es pequeño en comparación con los chips de computadora, la macromolécula es grande en el mundo molecular. Y, La síntesis de ADN requiere un trabajo especializado y, a menudo, repetitivo. Si cada mensaje debe diseñarse desde cero, El almacenamiento de macromoléculas podría convertirse en un trabajo largo y costoso.
"Nos propusimos explorar una estrategia que no toma prestada directamente de la biología, "Dice Cafferty." En cambio, confiamos en técnicas comunes en la química orgánica y analítica, y desarrolló un enfoque que utiliza pequeños moléculas de bajo peso molecular para codificar información ".
Con solo una síntesis, el equipo puede producir suficientes moléculas pequeñas para codificar varios videos de gatos a la vez, haciendo que este enfoque sea menos laborioso y más barato que uno basado en el ADN.
Por sus moléculas de bajo peso, el equipo seleccionó oligopéptidos (dos o más péptidos unidos entre sí), que son comunes, estable, y más pequeño que el ADN, ARN o proteínas.
Los oligopéptidos también varían en masa, dependiendo de su número y tipo de aminoácidos. Mezclados, se distinguen entre sí, como letras en una sopa de letras.
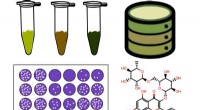
Hacer palabras a partir de las letras es un poco complicado:en un micropocillo, como una versión en miniatura de un whack-a-mole pero con 384 agujeros topo, cada pozo contiene oligopéptidos con masas variables. Así como la tinta se absorbe en una página, las mezclas de oligopéptidos se ensamblan luego sobre una superficie metálica donde se almacenan. Si el equipo quiere volver a leer lo que "escribieron, "miran uno de los pozos a través de un espectrómetro de masas, que clasifica las moléculas por masa. Esto les dice qué oligopéptidos están presentes o ausentes:su masa los delata.
Luego, traducir el revoltijo de moléculas en letras y palabras, tomaron prestado el código binario. Una "M, " por ejemplo, utiliza cuatro de los ocho posibles oligopéptidos, cada uno con una masa diferente. Los cuatro que flotan en el pozo reciben un "1, "mientras que los cuatro que faltan reciben un" 0 ". El código binario molecular apunta a una letra correspondiente o, si la información es una imagen, un píxel correspondiente.
Con este método, una mezcla de ocho oligopéptidos puede almacenar un byte de información; 32 pueden almacenar cuatro bytes; y más podría almacenar aún más.
Hasta aquí, Cafferty y su equipo "escribieron:"almacenado, y "leer" la famosa conferencia del físico Richard Feynman "Hay mucho espacio en la parte inferior, "una foto de Claude Shannon (conocido como el padre de la teoría de la información), y la pintura en madera de Hokusai La gran ola frente a Kanagawa. Dado que se estima que el archivo digital global alcanzará los 44 billones de gigabytes en 2020 (diez veces más que en 2013), una imagen de un tsunami parece apropiada.
Ahora, el equipo puede recuperar sus obras maestras almacenadas con una precisión del 99,9%. Su "escritura" promedia 8 bits por segundo y la "lectura" promedia 20 bits por segundo. Aunque su velocidad de "escritura" supera con creces la escritura con ADN sintético, la lectura podría ser más rápida y económica con la macromolécula.
Pero, con tecnología más rápida, las velocidades del equipo seguramente aumentarán. Una impresora de inyección de tinta por ejemplo, podría generar caídas a tasas de 1, 000 por segundo y atesora más información en áreas más pequeñas. Y, Los espectrómetros de masas mejorados podrían absorber aún más información a la vez.
El equipo también podría mejorar la estabilidad, precio, y capacidad de su almacenamiento molecular con diferentes clases de moléculas. Sus oligopéptidos están hechos a medida y, por lo tanto, más caro. Pero los futuros constructores de bibliotecas podrían comprar moléculas económicas (como alcanetioles) que costarían solo un centavo para registrar 100, 000, 000 bits de información.
A diferencia de otros sistemas de almacenamiento de información molecular, que dependen de una molécula específica, este enfoque puede utilizar cualquier molécula maleable siempre que pueda manipularse en trozos distinguibles.
Los oligopéptidos, y opciones similares, ya son resistentes. "Los oligopéptidos tienen estabilidades de cientos o miles de años en condiciones adecuadas, "según el documento. Las resistentes moléculas podrían resistir sin luz ni oxígeno, en altas temperaturas y sequía. Y, a diferencia de la nube, a qué piratas informáticos pueden acceder desde su sillón favorito, solo se puede acceder al almacenamiento molecular en persona. Incluso si un ladrón encuentra el alijo de datos, se necesita un poco de química para recuperar el código.
La biblioteca molecular escalable de Cafferty es un energía cero, y opción resistente a la corrupción para el almacenamiento de información en el futuro. Entonces, si los libros se queman, las computadoras son pirateadas, y los DVD fallan, un whack-a-mole lleno de información podría persistir para recordarle a la humanidad futura cuánto amamos un buen video de gatos.
El estudio se publica en Ciencia Central ACS .