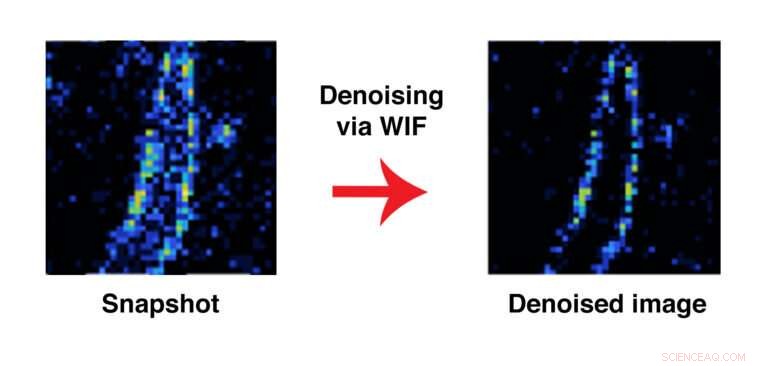
Investigadores de la Escuela de Ingeniería McKelvey han desarrollado un método computacional que les permite determinar no si una imagen de imagen completa es precisa, pero si algún punto de la imagen es probable, basado en los supuestos incorporados en el modelo. Aquí, una imagen de una fibrilla de amiloide antes y después de aplicar el método conocido como WIF. Crédito:Lew Lab
Un agente de bienes raíces envía a un posible comprador de vivienda una fotografía borrosa de una casa tomada desde el otro lado de la calle. El comprador puede compararlo con el producto real:mire la imagen, luego mire la casa real y vea que el ventanal son en realidad dos ventanas juntas, las flores del frente son de plástico y lo que parecía una puerta es en realidad un agujero en la pared.
¿Qué pasa si no estás mirando una foto de una casa, pero algo muy pequeño, ¿como una proteína? No hay forma de verlo sin un dispositivo especializado, por lo que no hay nada contra lo que juzgar la imagen. no hay verdad fundamental, 'como se llama. No hay mucho que hacer, pero confiar en que el equipo de imágenes y el modelo de computadora utilizado para crear imágenes son precisos.
Ahora, sin embargo, La investigación del laboratorio de Matthew Lew en la Escuela de Ingeniería McKelvey de la Universidad de Washington en St. Louis ha desarrollado un método computacional para determinar cuánta confianza debe tener un científico en que sus mediciones, en cualquier punto dado, son precisos, dado el modelo utilizado para producirlos.
La investigación fue publicada el 11 de diciembre en Comunicaciones de la naturaleza .
"Fundamentalmente, esta es una herramienta forense para decirle si algo está bien o no, "dijo Lew, profesor asistente en el Departamento de Ingeniería Eléctrica y de Sistemas de Preston M. Green. No es simplemente una forma de obtener una imagen más nítida. "Esta es una forma completamente nueva de validar la confiabilidad de cada detalle dentro de una imagen científica.
"No se trata de ofrecer una mejor resolución, ", agregó sobre el método computacional, llamado flujo inducido por Wasserstein (WIF). "Está diciendo, 'Esta parte de la imagen puede estar mal o fuera de lugar' ".
El proceso utilizado por los científicos para "ver" la microscopía de localización de una sola molécula (SMLM) muy pequeña se basa en capturar cantidades masivas de información del objeto que se está fotografiando. Luego, esa información es interpretada por un modelo de computadora que finalmente elimina la mayoría de los datos, reconstruir una imagen aparentemente precisa, una imagen real de una estructura biológica, como una proteína amiloide o una membrana celular.
Ya se utilizan algunos métodos para ayudar a determinar si una imagen es, generalmente hablando, una buena representación de la cosa que se está imaginando. Estos métodos, sin embargo, no puede determinar qué tan probable es que un solo punto de datos dentro de una imagen sea preciso.
Hesam Mazidi, un recién graduado que era estudiante de doctorado en el laboratorio de Lew para esta investigación, abordó el problema.
"Queríamos ver si había una manera de hacer algo sobre este escenario sin una verdad fundamental, ", dijo." Si pudiéramos usar el modelado y el análisis algorítmico para cuantificar si nuestras mediciones son fieles, o lo suficientemente precisa ".
Los investigadores no tenían la verdad básica, ninguna casa para comparar con la foto del agente inmobiliario, pero no tenían las manos vacías. Tenían una gran cantidad de datos que generalmente se ignoran. Mazidi aprovechó la enorme cantidad de información recopilada por el dispositivo de imágenes que generalmente se descarta como ruido. La distribución del ruido es algo que los investigadores pueden utilizar como verdad fundamental porque se ajusta a leyes específicas de la física.
"Pudo decir, 'Yo sé cómo se manifiesta el ruido de la imagen, esa es una ley física fundamental, Lew dijo sobre la perspicacia de Mazidi.
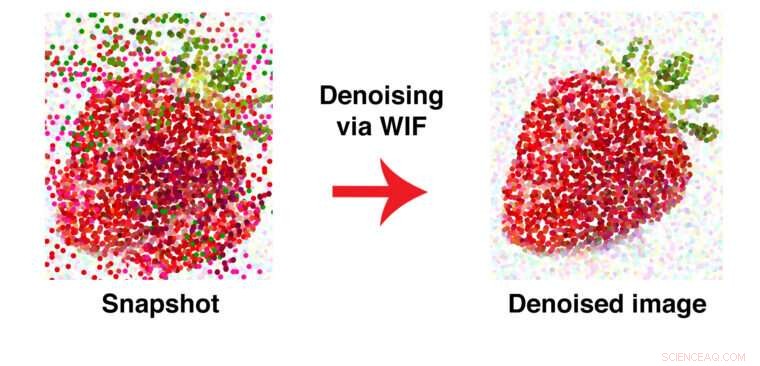
Este gráfico ilustra la forma en que WIF elimina los puntos de datos extraviados. Después de eliminar el ruido, los trozos verdes de "hoja" se eliminan del cuerpo rojo de la fruta. Crédito:Universidad de Washington en St. Louis
"Volvió al ruidoso, dominio imperfecto de la medición científica real, "Dijo Lew. Todos los puntos de datos registrados por el dispositivo de imágenes." Hay datos reales allí que la gente tira e ignora ".
En lugar de ignorarlo, Mazidi miró para ver qué tan bien el modelo predijo el ruido, dada la imagen final y el modelo que lo creó.
Analizar tantos puntos de datos es similar a ejecutar el dispositivo de imágenes una y otra vez, realizar varias pruebas para calibrarlo.
"Todas esas mediciones nos brindan confianza estadística, Lew dijo.
WIF les permite determinar no si la imagen completa es probable según el modelo, pero, considerando la imagen, si algún punto de la imagen es probable, basado en los supuestos incorporados en el modelo.
Por último, Mazidi desarrolló un método que puede decir con gran confianza estadística que cualquier punto de datos dado en la imagen final debe o no debe estar en un lugar en particular.
Es como si el algoritmo analizara la imagen de la casa y, sin haber visto nunca el lugar, limpiara la imagen, revelando el agujero en la pared.
En el final, el análisis arroja un solo número por punto de datos, entre -1 y 1. Cuanto más cerca de uno, Cuanto más seguro pueda estar un científico de que un punto de una imagen es, De hecho, representando con precisión la cosa que se está imaginando.
Este proceso también puede ayudar a los científicos a mejorar sus modelos. "Si puede cuantificar el rendimiento, entonces también puedes mejorar tu modelo usando la puntuación, "Dijo Mazidi. Sin acceso a la verdad básica, "Nos permite evaluar el rendimiento en condiciones experimentales reales en lugar de una simulación".
Los usos potenciales de WIF son de gran alcance. Lew dijo que el siguiente paso es usarlo para validar el aprendizaje automático, donde los conjuntos de datos sesgados pueden producir resultados inexactos.
¿Cómo sabría un investigador, en cuyo caso, que sus datos estaban sesgados? "Con este modelo, podría realizar pruebas en datos que no tienen verdad básica, donde no sabe si la red neuronal se entrenó con datos que son similares a los datos del mundo real.
"Hay que tener cuidado en cada tipo de medición que realice, "Dijo Lew." A veces solo queremos presionar el gran botón rojo y ver lo que obtenemos, pero tenemos que recordar hay muchas cosas que suceden cuando presionas ese botón ".