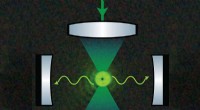
Las partículas que emergen de las colisiones de protones en el Gran Colisionador de Hadrones del CERN viajan a través de esta historia de altura, instrumento de muchas capas, el detector CMS. En 2026, el LHC producirá 20 veces más datos que en la actualidad, y CMS se encuentra actualmente en proceso de actualización para leer y procesar la avalancha de datos. Crédito:Maximilien Brice, CERN
Cada colisión de protones en el Gran Colisionador de Hadrones es diferente, pero solo unos pocos son especiales. Las colisiones especiales generan partículas en patrones inusuales, posibles manifestaciones de nuevos, física que rompe las reglas, o ayuda a completar nuestra imagen incompleta del universo.
Encontrar estas colisiones es más difícil que la proverbial búsqueda de la aguja en el pajar. Pero la ayuda que cambia el juego está en camino. Los científicos de Fermilab y otros colaboradores probaron con éxito un prototipo de tecnología de aprendizaje automático que acelera el procesamiento de 30 a 175 veces en comparación con los métodos tradicionales.
Enfrentando 40 millones de colisiones por segundo, los científicos del LHC utilizan potentes Computadoras ágiles para arrancar las gemas, ya sea una partícula de Higgs o indicios de materia oscura, de la enorme estática de las colisiones ordinarias.
Examinando datos de colisión simulada del LHC, La tecnología de aprendizaje automático aprendió con éxito a identificar un patrón de poscolisión en particular, un rocío particular de partículas que volaban a través de un detector, mientras pasaba a través de la asombrosa cantidad de 600 imágenes por segundo. Los métodos tradicionales procesan menos de una imagen por segundo.
La tecnología podría incluso ofrecerse como un servicio en computadoras externas. El uso de este modelo de descarga permitiría a los investigadores analizar más datos con mayor rapidez y dejar más espacio de cálculo del LHC disponible para realizar otros trabajos.
Es una visión prometedora de cómo los servicios de aprendizaje automático están respaldando un campo en el que ya enormes cantidades de datos solo van a crecer.
El desafío:más datos, más potencia informática
Los investigadores están actualizando el LHC para romper protones a cinco veces su tasa actual. Para 2026, La máquina subterránea circular de 17 millas en el laboratorio europeo CERN producirá 20 veces más datos que ahora.
CMS es uno de los detectores de partículas del Gran Colisionador de Hadrones, y los colaboradores de CMS están en medio de algunas actualizaciones propias, habilitando lo intrincado, instrumento de una altura de una historia para tomar fotografías más sofisticadas de las colisiones de partículas del LHC. Fermilab es el laboratorio líder en EE. UU. Para el experimento CMS.
Si los científicos del LHC quisieran guardar todos los datos de colisión sin procesar que recopilarían en un año del LHC de alta luminosidad, tendrían que encontrar una manera de almacenar aproximadamente 1 exabyte (aproximadamente 1 billón de discos duros externos personales), de los cuales solo una astilla puede revelar nuevos fenómenos. Las computadoras del LHC están programadas para seleccionar esta pequeña fracción, tomar decisiones en una fracción de segundo sobre qué datos son lo suficientemente valiosos como para enviarlos en sentido descendente para su posterior estudio.
En la actualidad, el sistema informático del LHC mantiene aproximadamente uno de cada 100, 000 eventos de partículas. Pero los protocolos de almacenamiento actuales no podrán mantenerse al día con la futura inundación de datos, que se acumulará durante décadas de toma de datos. Y las imágenes de mayor resolución capturadas por el detector CMS actualizado no facilitarán el trabajo. Todo se traduce en una necesidad de más de 10 veces los recursos informáticos que el LHC tiene ahora.

Los físicos de partículas están explorando el uso de computadoras con capacidades de aprendizaje automático para procesar imágenes de colisiones de partículas en CMS, enseñándoles a identificar rápidamente varios patrones de colisión. Crédito:Eamonn Maguire / Antarctic Design
La prueba de prototipo reciente muestra que, con los avances en el aprendizaje automático y el hardware informático, Los investigadores esperan poder analizar los datos que surjan del próximo LHC de alta luminosidad cuando esté en línea.
"La esperanza aquí es que pueda hacer cosas muy sofisticadas con el aprendizaje automático y también hacerlas más rápido, "dijo Nhan Tran, un científico de Fermilab en el experimento CMS y uno de los líderes en la prueba reciente. "Esto es importante, dado que nuestros datos se volverán cada vez más complejos con detectores mejorados y entornos de colisión más ocupados ".
Aprendizaje automático al rescate:la diferencia de inferencia
El aprendizaje automático en física de partículas no es nuevo. Los físicos utilizan el aprendizaje automático para cada etapa del procesamiento de datos en un experimento de colisionador.
Pero con la tecnología de aprendizaje automático que puede procesar los datos del LHC hasta 175 veces más rápido que los métodos tradicionales, Los físicos de partículas están ascendiendo un paso revolucionario en el curso de cálculo de colisiones.
Las tasas rápidas se deben al hardware ingeniosamente diseñado en la plataforma, Azure ML de Microsoft, lo que acelera un proceso llamado inferencia.
Para entender la inferencia, considere un algoritmo que ha sido entrenado para reconocer la imagen de una motocicleta:el objeto tiene dos ruedas y dos asas que están unidas a un cuerpo de metal más grande. El algoritmo es lo suficientemente inteligente como para saber que una carretilla, que tiene atributos similares, no es una motocicleta. A medida que el sistema escanea nuevas imágenes de otros vehículos de dos ruedas, objetos de dos asas, predice —o infiere— cuáles son las motocicletas. Y a medida que se corrigen los errores de predicción del algoritmo, se vuelve bastante hábil para identificarlos. Mil millones de escaneos después está en su juego de inferencia.
La mayoría de las plataformas de aprendizaje automático están diseñadas para comprender cómo clasificar imágenes, pero no imágenes específicas de la física. Los físicos tienen que enseñarles la parte de física, como reconocer pistas creadas por el bosón de Higgs o buscar indicios de materia oscura.
Investigadores de Fermilab, CERN, MIT, la Universidad de Washington y otros colaboradores capacitaron a Azure ML para identificar imágenes de quarks superiores, una partícula elemental de vida corta que es aproximadamente 180 veces más pesada que un protón, a partir de datos CMS simulados. Específicamente, Azure debía buscar imágenes de los mejores chorros de quarks, nubes de partículas extraídas del vacío por un solo quark superior que se aleja zumbando de la colisión.
"Le enviamos las imágenes, entrenarlo con datos físicos, "dijo el científico del Fermilab Burt Holzman, una pista en el proyecto. "Y mostró un rendimiento de vanguardia. Fue muy rápido. Eso significa que podemos canalizar una gran cantidad de estas cosas. En general, estas técnicas son bastante buenas ".
Una de las técnicas detrás de la aceleración de inferencias es combinar procesadores tradicionales con especializados, un matrimonio conocido como arquitectura informática heterogénea.

Los datos de los experimentos de física de partículas se almacenan en granjas informáticas como esta, el Grid Computing Center en Fermilab. Las organizaciones externas ofrecen sus granjas informáticas como un servicio para los experimentos de física de partículas, haciendo más espacio disponible en los servidores de los experimentos. Crédito:Reidar Hahn
Las diferentes plataformas utilizan diferentes arquitecturas. Los procesadores tradicionales son CPU (unidades centrales de procesamiento). Los procesadores especializados más conocidos son las GPU (unidades de procesamiento de gráficos) y las FPGA (matrices de puertas programables en campo). Azure ML combina CPU y FPGA.
"La razón por la que estos procesos deben acelerarse es que se trata de grandes cálculos. Estamos hablando de 25 mil millones de operaciones, "Dijo Tran." Colocando eso en un FPGA, mapeando eso, y hacerlo en un tiempo razonable es un verdadero logro ".
Y está comenzando a ofrecerse como un servicio, también. La prueba fue la primera vez que alguien demostró cómo este tipo de heterogeneidad, La arquitectura como servicio se puede utilizar para la física fundamental.
En el mundo de la informática, usar algo "como un servicio" tiene un significado específico. Una organización externa proporciona recursos (aprendizaje automático o hardware) como un servicio, y los usuarios, los científicos, recurren a esos recursos cuando los necesitan. Es similar a cómo su empresa de transmisión de video ofrece horas de ver televisión en exceso como un servicio. No necesita tener sus propios DVD y reproductor de DVD. En su lugar, usa su biblioteca e interfaz.
Los datos del Gran Colisionador de Hadrones generalmente se almacenan y procesan en servidores informáticos en el CERN y en instituciones asociadas como Fermilab. Con el aprendizaje automático ofrecido tan fácilmente como lo sería cualquier otro servicio web, Se pueden realizar cálculos intensivos en cualquier lugar donde se ofrezca el servicio, incluso fuera del sitio. Esto refuerza las capacidades de los laboratorios con potencia y recursos informáticos adicionales y les evita tener que proporcionar sus propios servidores.
"La idea de hacer computación acelerada ha existido durante décadas, pero el modelo tradicional era comprar un clúster de computadoras con GPU e instalarlo localmente en el laboratorio, ", Dijo Holzman." La idea de descargar el trabajo a una granja fuera del sitio con hardware especializado, proporcionar aprendizaje automático como servicio, que funcionó como se anuncia ".
La granja de Azure ML se encuentra en Virginia. Solo se necesitan 100 milisegundos para las computadoras en Fermilab cerca de Chicago, Illinois, para enviar una imagen de un evento de partículas a la nube de Azure, procesalo, y devuélvelo. Eso es un 2 500 kilómetros, viaje lleno de datos en un abrir y cerrar de ojos.
"La plomería que acompaña a todo eso es otro logro, ", Dijo Tran." El concepto de abstraer esos datos como algo que se envía a otro lugar, y simplemente vuelve, fue lo más gratamente sorprendente de este proyecto. No tenemos que reemplazar todo en nuestro propio centro de cómputo con un montón de cosas nuevas. Lo guardamos todo envíe los cálculos duros y haga que vuelva más tarde ".
Los científicos esperan escalar la tecnología para abordar otros desafíos de big data en el LHC. También planean probar otras plataformas, como Amazon AWS, Google Cloud e IBM Cloud, mientras exploran qué más se puede lograr mediante el aprendizaje automático, que ha experimentado una rápida evolución en los últimos años.
"Los modelos que estaban a la vanguardia en 2015 son estándar hoy en día, "Tran dijo.
Como una herramienta, El aprendizaje automático continúa brindando a la física de partículas nuevas formas de vislumbrar el universo. También es impresionante por derecho propio.
"Que podemos tomar algo que esté entrenado para discriminar entre imágenes de animales y personas, hacer algunos cálculos de cantidades modestas, y ¿me dice la diferencia entre un jet de quark top y el fondo? ", dijo Holzman." Eso es algo que me deja boquiabierto ".