Esta animación muestra una serie de eventos de colisión en STAR, cada uno con miles de pistas de partículas y las señales registradas cuando algunas de esas partículas golpean varios componentes del detector. Debería darle una idea de lo complejo que es el desafío de reconstruir un registro completo de cada partícula y las condiciones en las que se creó para que los científicos puedan comparar cientos de millones de eventos para buscar tendencias y hacer descubrimientos. Crédito:Laboratorio Nacional Brookhaven
Por primera vez, Los científicos han utilizado la computación de alto rendimiento (HPC) para reconstruir los datos recopilados por un experimento de física nuclear, un avance que podría reducir drásticamente el tiempo necesario para que los datos detallados estén disponibles para los descubrimientos científicos.
El proyecto de demostración utilizó la supercomputadora Cori en el Centro Nacional de Computación Científica de Investigación Energética (NERSC), un centro de computación de alto rendimiento en el Laboratorio Nacional Lawrence Berkeley en California, reconstruir múltiples conjuntos de datos recopilados por el detector STAR durante colisiones de partículas en el colisionador de iones pesados relativista (RHIC), una instalación de investigación de física nuclear en el Laboratorio Nacional Brookhaven en Nueva York. Al ejecutar varios trabajos de computación simultáneamente en los núcleos de supercomputación asignados, el equipo transformó 4,73 petabytes de datos sin procesar en 2,45 petabytes de datos "preparados para la física" en una fracción del tiempo que habría tardado utilizando recursos informáticos internos de alto rendimiento, incluso con un viaje de datos transcontinental de dos vías.
"La razón por la que esto es realmente fantástico, "dijo el físico de Brookhaven Jérôme Lauret, quién gestiona las necesidades informáticas de STAR, "es que estos recursos informáticos de alto rendimiento son elásticos. Puede llamar para reservar una gran cantidad de potencia informática cuando la necesite, por ejemplo, justo antes de una gran conferencia cuando los físicos tienen prisa por presentar nuevos resultados ". Según Lauret, preparar los datos sin procesar para el análisis suele llevar muchos meses, lo que hace que sea casi imposible proporcionar una capacidad de respuesta a tan corto plazo. "Pero con HPC, tal vez podría condensar esa cantidad de meses de tiempo de producción en una semana. ¡Eso realmente empoderaría a los científicos! "
El logro muestra las capacidades sinérgicas de RHIC y NERSC — EE. UU. Instalaciones para usuarios de la Oficina de ciencia del Departamento de Energía (DOE) ubicadas en laboratorios nacionales administrados por el DOE en costas opuestas, conectadas por una de las redes de intercambio de datos de alto rendimiento más extensas del mundo, Red de Ciencias de la Energía del DOE (ESnet), otra instalación para usuarios de la Oficina de Ciencias del DOE.
"Este es un modelo de uso clave de la informática de alto rendimiento para datos experimentales, demostrando que los investigadores pueden realizar sus campañas de simulación o procesamiento de datos sin procesar en unos pocos días o semanas en un momento crítico en lugar de extenderse a lo largo de meses con sus propios recursos dedicados, "dijo Jeff Porter, miembro del equipo de servicios de datos y análisis de NERSC.
Miles de millones de puntos de datos
Para hacer descubrimientos de física en RHIC, los científicos deben clasificar cientos de millones de colisiones entre iones acelerados a muy alta energía. ESTRELLA, un sofisticado, instrumento electrónico del tamaño de una casa, registra los desechos subatómicos que fluyen desde estos aplastamientos de partículas. En los eventos más enérgicos, muchos miles de partículas golpean los componentes del detector, produciendo exhibiciones similares a fuegos artificiales de coloridas pistas de partículas. Pero para averiguar qué significan estas señales complejas, y lo que pueden decirnos sobre la forma intrigante de la materia creada en las colisiones de RHIC, los científicos necesitan descripciones detalladas de todas las partículas y las condiciones en las que se produjeron. También deben comparar enormes muestras estadísticas de muchos tipos diferentes de eventos de colisión.
Catalogar esa información requiere algoritmos sofisticados y software de reconocimiento de patrones para combinar señales de los diversos componentes electrónicos de lectura, y una forma perfecta de hacer coincidir esos datos con los registros de las condiciones de colisión. Luego, toda la información debe empaquetarse de manera que los físicos puedan utilizarla para sus análisis.

Cori, la supercomputadora más nueva del Centro Nacional de Computación Científica de Investigación en Energía (NERSC), es un Cray XC40 con un rendimiento máximo de unos 30 petaflops. Crédito:Laboratorio Nacional Brookhaven
Desde que RHIC comenzó a funcionar en el año 2000, este procesamiento de datos sin procesar, o reconstrucción, se ha llevado a cabo en recursos informáticos dedicados en RHIC y ATLAS Computing Facility (RACF) en Brookhaven. Los clústeres de computación de alto rendimiento (HTC) procesan los datos, evento por evento, y escriba los detalles codificados de cada colisión en un espacio de almacenamiento masivo centralizado accesible a los físicos de STAR de todo el mundo.
Pero el desafío de mantenerse al día con los datos ha crecido con las tasas de colisión en constante mejora de RHIC y a medida que se han agregado nuevos componentes de detectores. En años recientes, Los conjuntos de datos brutos anuales de STAR han alcanzado miles de millones de eventos con tamaños de datos en el rango de varios petabytes. Entonces, el equipo de computación de STAR investigó el uso de recursos externos para satisfacer la demanda de acceso oportuno a datos listos para la física.
Muchos núcleos facilitan el trabajo
A diferencia de las computadoras de alto rendimiento del RACF, que analizan los eventos uno por uno, Los recursos de HPC como los de NERSC dividen los problemas grandes en tareas más pequeñas que pueden ejecutarse en paralelo. Así que el primer desafío fue "paralelizar" el procesamiento de datos de eventos STAR.
"Escribimos programas de flujo de trabajo que lograron el primer nivel de paralelización:paralelización de eventos, "Dijo Lauret. Eso significa que envían menos trabajos hechos de muchos eventos que se pueden procesar simultáneamente en los muchos núcleos de computación HPC.
"Imagínese construir una ciudad con 100 casas. Si esto se hiciera con un alto rendimiento, cada casa tendría un constructor que haría todas las tareas en secuencia:construir los cimientos, los muros, etcétera, "Dijo Lauret." Pero con HPC cambiamos el paradigma. En lugar de un trabajador por casa, tenemos 100 trabajadores por casa, y cada trabajador tiene una tarea:construir las paredes o el techo. Trabajan en paralelo, al mismo tiempo, y armamos todo junto al final. Con este enfoque, construiremos esa casa 100 veces más rápido ".
Por supuesto, se necesita algo de creatividad para pensar en cómo estos problemas se pueden dividir en tareas que pueden ejecutarse simultáneamente en lugar de secuencialmente, Lauret agregó.
HPC también ahorra tiempo haciendo coincidir las señales del detector sin procesar con los datos sobre las condiciones ambientales durante cada evento. Para hacer esto, las computadoras deben acceder a una "base de datos de condiciones":un registro del voltaje, temperatura, presión, y otras condiciones del detector que deben tenerse en cuenta para comprender el comportamiento de las partículas producidas en cada colisión. En evento por evento, reconstrucción de alto rendimiento, las computadoras acceden a la base de datos para recuperar datos de cada evento. Pero como los núcleos HPC comparten algo de memoria, los eventos que ocurren cerca en el tiempo pueden usar los mismos datos de condición almacenados en caché. Menos llamadas a la base de datos significan un procesamiento de datos más rápido.
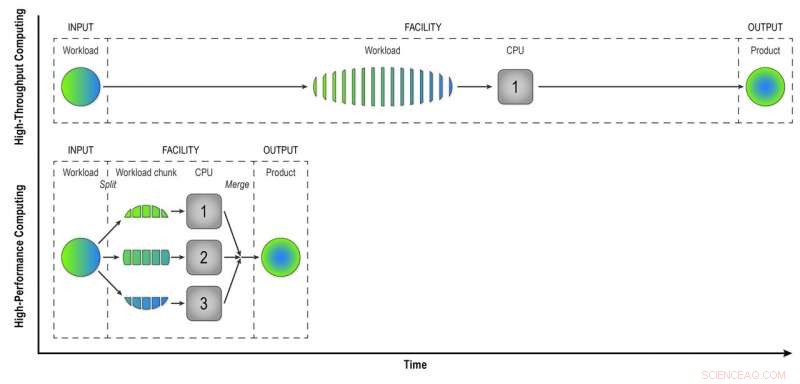
En informática de alto rendimiento, una carga de trabajo compuesta de datos de muchas colisiones STAR se procesa evento por evento de manera secuencial para brindar a los físicos "datos reconstruidos", el producto que necesitan para analizar completamente los datos. La informática de alto rendimiento divide la carga de trabajo en trozos más pequeños que se pueden ejecutar a través de CPU independientes para acelerar la reconstrucción de datos. En esta simple ilustración, Al dividir una carga de trabajo de 15 eventos en tres partes de cinco eventos procesados en paralelo, se obtiene el mismo producto en un tercio del tiempo que el método de alto rendimiento. El uso de 32 CPU en una supercomputadora como Cori puede reducir en gran medida el tiempo que lleva transformar los datos sin procesar de un conjunto de datos STAR real, con muchos millones de eventos, en información útil que los físicos pueden analizar para hacer descubrimientos. Crédito:Laboratorio Nacional Brookhaven
Trabajo en equipo en red
Otro desafío en la migración de la tarea de reconstrucción de datos sin procesar a un entorno HPC fue simplemente llevar los datos de Nueva York a las supercomputadoras en California y viceversa. Tanto los conjuntos de datos de entrada como de salida son enormes. El equipo comenzó poco a poco con un experimento de prueba de principio, solo unos pocos cientos de trabajos, para ver cómo funcionarían sus nuevos programas de flujo de trabajo.
"Tuvimos mucha ayuda de los profesionales de redes de Brookhaven, "dijo Lauret, "especialmente Mark Lukascsyk, uno de nuestros ingenieros de redes, que estaba tan entusiasmado con la ciencia y nos ayudó a hacer descubrimientos ". Los colegas de RACF y ESnet también ayudaron a identificar problemas de hardware y desarrollaron soluciones mientras el equipo trabajaba en estrecha colaboración con Jeff Porter, Mustafa Mustafa, y otros en NERSC para optimizar la transferencia de datos y el flujo de trabajo de un extremo a otro.
Empieza pequeño, aumentar proporcionalmente
Después de ajustar sus métodos en función de las pruebas iniciales, el equipo comenzó a escalar hasta usar 6, 400 núcleos informáticos en NERSC, luego hacia arriba y hacia arriba y hacia arriba.
"6, 400 núcleos ya es la mitad del tamaño de los recursos disponibles para la reconstrucción de datos en RACF, ", Dijo Lauret." Finalmente, llegamos a 25, 600 núcleos en nuestra prueba más reciente ". Con todo listo de antemano para una asignación de tiempo de reserva anticipada en la supercomputadora Cori, "Hicimos esta prueba durante unos días y completamos una producción de datos completa en poco tiempo, "Lauret dijo. Según Porter en NERSC, "Este modelo es potencialmente bastante transformador, y NERSC ha trabajado para respaldar dicha utilización de recursos mediante, por ejemplo, conectando su sistema de disco de alto rendimiento en todo el centro directamente a su infraestructura de transferencia de datos y permitiendo una flexibilidad significativa en cómo se pueden programar los espacios de trabajo ".
La eficiencia de un extremo a otro de todo el proceso:el tiempo que el programa estuvo en ejecución (no inactivo, esperando recursos informáticos) multiplicado por la eficiencia de usar las ranuras de supercomputación asignadas y obtener resultados útiles hasta Brookhaven, fue del 98 por ciento.
"Hemos demostrado que podemos utilizar los recursos de HPC de manera eficiente para eliminar los atrasos de datos sin procesar y resolver las demandas temporales de recursos para acelerar los descubrimientos científicos, "Dijo Lauret.
Ahora está explorando formas de generalizar el flujo de trabajo a Open Science Grid, un consorcio global que agrega recursos informáticos, para que toda la comunidad de físicos nucleares y de alta energía pueda utilizarlo.