Centro de datos del CERN. Crédito:Robert Hradil, Monika Majer / ProStudio22.ch
El 29 de junio de 2017, el CERN DC superó el hito de 200 petabytes de datos archivados permanentemente en sus bibliotecas de cintas. ¿De dónde provienen estos datos? Las partículas chocan en los detectores del Gran Colisionador de Hadrones (LHC) aproximadamente mil millones de veces por segundo, generando alrededor de un petabyte de datos de colisión por segundo. Sin embargo, tales cantidades de datos son imposibles de registrar para los sistemas informáticos actuales y, por lo tanto, son filtrados por los experimentos, manteniendo solo los más "interesantes". Los datos filtrados del LHC se agregan luego en el Centro de datos del CERN (DC), donde se realiza la reconstrucción de datos inicial, y dónde se archiva una copia en un almacenamiento en cinta a largo plazo. Incluso después de la drástica reducción de datos realizada por los experimentos, el CERN DC procesa en promedio un petabyte de datos por día. Así se alcanzó el pasado 29 de junio el hito de 200 petabytes de datos archivados de forma permanente en sus librerías de cintas.
Los cuatro grandes experimentos del LHC han producido volúmenes de datos sin precedentes en los dos últimos años. Esto se debe en gran parte al excelente rendimiento y disponibilidad del propio LHC. En efecto, en 2016, Las expectativas eran inicialmente de alrededor de 5 millones de segundos de toma de datos, mientras que el total final fue de alrededor de 7,5 millones de segundos, un aumento del 50% muy bienvenido. 2017 sigue una tendencia similar.
Más lejos, dado que la luminosidad es mayor que en 2016, muchas colisiones se superponen y los eventos son más complejos, requiriendo una reconstrucción y un análisis cada vez más sofisticados. Esto tiene un fuerte impacto en los requisitos informáticos. Como consecuencia, Se están batiendo récords en muchos aspectos de la adquisición de datos, velocidades de datos y volúmenes de datos, con niveles excepcionales de uso de recursos informáticos y de almacenamiento.
Para enfrentar estos desafíos, la infraestructura informática en general, y en particular los sistemas de almacenamiento, pasó por importantes actualizaciones y consolidación durante los dos años del cierre prolongado 1. Estas actualizaciones permitieron al centro de datos hacer frente a los 73 petabytes de datos recibidos en 2016 (49 de los cuales eran datos del LHC) y al flujo de datos entregados hasta ahora en 2017. Estas actualizaciones también permitieron que el sistema CERN Advanced STORage (CASTOR) superara el desafiante hito de 200 petabytes de datos archivados de forma permanente. Estos datos archivados permanentemente representan una fracción importante de la cantidad total de datos recibidos en el centro de datos del CERN. el resto son datos temporales que se limpian periódicamente.
Otra consecuencia de los mayores volúmenes de datos es una mayor demanda de transferencia de datos y, por lo tanto, la necesidad de una mayor capacidad de red. Desde principios de febrero, un tercer circuito de fibra óptica de 100 Gb / s (gigabit por segundo) conecta el CERN DC con su extensión remota alojada en el Centro de Investigación de Física Wigner (RCP) en Hungría, 1800km de distancia. El ancho de banda adicional y la redundancia proporcionados por este tercer enlace ayudan al CERN a beneficiarse de manera confiable de la potencia informática y el almacenamiento en la extensión remota. ¡Imprescindible en el contexto de las crecientes necesidades informáticas!
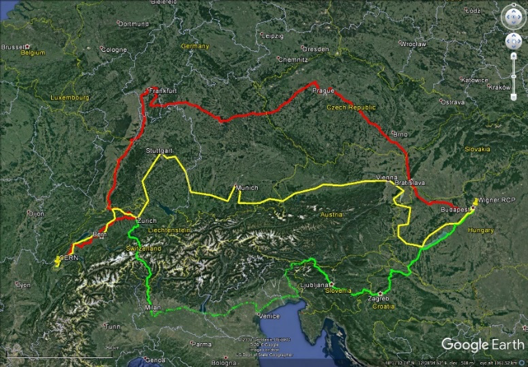
Este mapa muestra las rutas para los tres enlaces de fibra de 100 Gbit / s entre el CERN y Wigner RCP. Las rutas se han elegido cuidadosamente para garantizar que mantenemos la conectividad en caso de incidentes. (Imagen:Google)