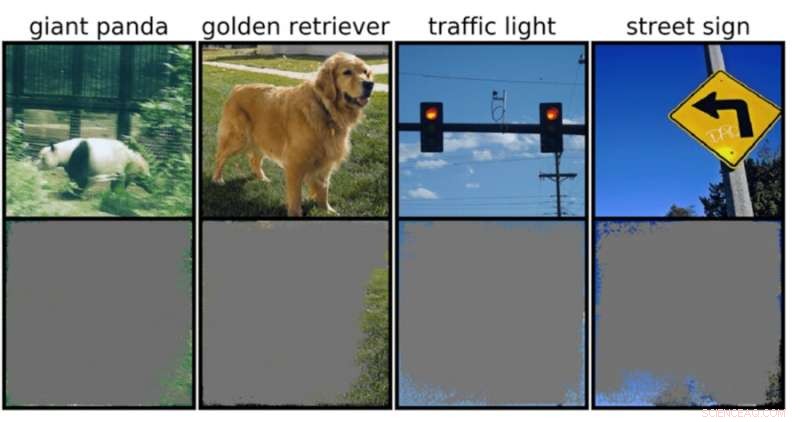
Un clasificador de imágenes profundas puede determinar clases de imágenes con más del 90 por ciento de confianza utilizando principalmente bordes de imágenes, en lugar de un objeto en sí. Crédito:Rachel Gordon
A pesar de todo lo que pueden lograr las redes neuronales, todavía no entendemos realmente cómo funcionan. Claro, podemos programarlos para que aprendan, pero dar sentido al proceso de toma de decisiones de una máquina sigue siendo muy parecido a un rompecabezas elegante con un patrón complejo y vertiginoso en el que aún deben encajar muchas piezas integrales.
Si un modelo estaba tratando de clasificar una imagen de dicho rompecabezas, por ejemplo, podría encontrar ataques de adversarios bien conocidos pero molestos, o incluso más problemas de procesamiento o datos comunes y corrientes. Pero un nuevo tipo de falla más sutil identificado recientemente por los científicos del MIT es otro motivo de preocupación:la "interpretación excesiva", donde los algoritmos hacen predicciones confiables basadas en detalles que no tienen sentido para los humanos, como patrones aleatorios o bordes de imágenes.
Esto podría ser particularmente preocupante para entornos de alto riesgo, como decisiones en una fracción de segundo para automóviles autónomos y diagnósticos médicos para enfermedades que necesitan una atención más inmediata. Los vehículos autónomos, en particular, dependen en gran medida de sistemas que pueden comprender con precisión el entorno y luego tomar decisiones rápidas y seguras. La red usó fondos específicos, bordes o patrones particulares del cielo para clasificar los semáforos y los letreros de las calles, independientemente de qué más hubiera en la imagen.
El equipo descubrió que las redes neuronales entrenadas en conjuntos de datos populares como CIFAR-10 e ImageNet sufrían de sobreinterpretación. Los modelos entrenados en CIFAR-10, por ejemplo, hicieron predicciones confiables incluso cuando faltaba el 95 por ciento de las imágenes de entrada, y el resto no tiene sentido para los humanos.
"La sobreinterpretación es un problema del conjunto de datos causado por estas señales sin sentido en los conjuntos de datos. Estas imágenes de alta confianza no solo son irreconocibles, sino que contienen menos del 10 por ciento de la imagen original en áreas sin importancia, como los bordes. Descubrimos que estas imágenes eran sin sentido para los humanos, pero los modelos aún pueden clasificarlos con gran confianza", dice Brandon Carter, Ph.D. del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT. estudiante y autor principal de un artículo sobre la investigación.
Los clasificadores de imágenes profundas son ampliamente utilizados. Además del diagnóstico médico y el impulso de la tecnología de vehículos autónomos, hay casos de uso en seguridad, juegos e incluso una aplicación que te dice si algo es o no un perrito caliente, porque a veces necesitamos tranquilidad. La tecnología en discusión funciona procesando píxeles individuales de toneladas de imágenes preetiquetadas para que la red "aprenda".
La clasificación de imágenes es difícil, porque los modelos de aprendizaje automático tienen la capacidad de captar estas señales sutiles sin sentido. Luego, cuando los clasificadores de imágenes se entrenan en conjuntos de datos como ImageNet, pueden hacer predicciones aparentemente confiables basadas en esas señales.
Aunque estas señales sin sentido pueden conducir a la fragilidad del modelo en el mundo real, las señales son realmente válidas en los conjuntos de datos, lo que significa que la sobreinterpretación no se puede diagnosticar utilizando métodos de evaluación típicos basados en esa precisión.
Para encontrar la justificación de la predicción del modelo sobre una entrada en particular, los métodos en el presente estudio comienzan con la imagen completa y preguntan repetidamente, ¿qué puedo eliminar de esta imagen? Esencialmente, sigue cubriendo la imagen, hasta que te quedas con la pieza más pequeña que todavía toma una decisión segura.
Con ese fin, también podría ser posible utilizar estos métodos como un tipo de criterio de validación. Por ejemplo, si tiene un automóvil de conducción autónoma que utiliza un método de aprendizaje automático entrenado para reconocer las señales de alto, puede probar ese método identificando el subconjunto de entrada más pequeño que constituye una señal de alto. Si eso consiste en la rama de un árbol, una hora particular del día o algo que no sea una señal de alto, es posible que le preocupe que el automóvil se detenga en un lugar en el que no debe hacerlo.
Si bien puede parecer que el modelo es el probable culpable aquí, es más probable que los conjuntos de datos sean los culpables. "Está la cuestión de cómo podemos modificar los conjuntos de datos de una manera que permita entrenar a los modelos para imitar más de cerca cómo pensaría un humano sobre la clasificación de imágenes y, por lo tanto, con suerte, generalizar mejor en estos escenarios del mundo real, como la conducción autónoma. y diagnóstico médico, para que los modelos no tengan este comportamiento sin sentido", dice Carter.
Esto puede significar crear conjuntos de datos en entornos más controlados. Actualmente, son solo las imágenes que se extraen de los dominios públicos las que luego se clasifican. Pero si desea realizar la identificación de objetos, por ejemplo, podría ser necesario entrenar modelos con objetos con un fondo no informativo.














