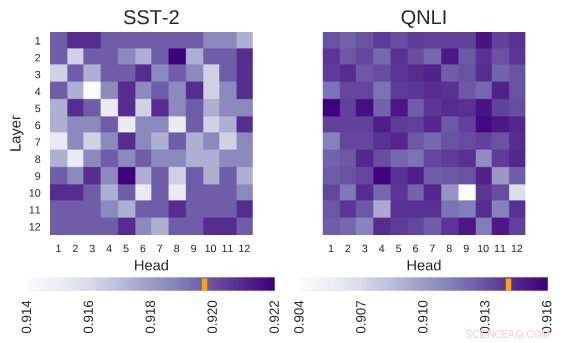
La arquitectura BERT investigada tiene la arquitectura de 12 capas por 12 cabezas. Cada celda de esta figura muestra el rendimiento de BERT si el cabezal correspondiente está apagado. Los colores más oscuros indican un mayor rendimiento, y los glóbulos blancos indican cabezas sin las cuales el rendimiento de BERT disminuye. Stanford Sentiment Treebank (SST-2):hay varias cabezas que codifican la información necesaria para la tarea. Pregunta Inferencia del lenguaje natural (QNLI):la mayoría de los cabezales mejoran el rendimiento general cuando están apagados. Crédito:Kovaleva et al.
BERT, un modelo basado en transformadores caracterizado por un mecanismo de auto-atención único, hasta ahora ha demostrado ser una alternativa válida a las redes neuronales recurrentes (RNN) para abordar las tareas de procesamiento del lenguaje natural (NLP). A pesar de sus ventajas, hasta aquí, muy pocos investigadores han estudiado estas arquitecturas basadas en BERT en profundidad, o trató de comprender las razones detrás de la efectividad de su mecanismo de auto-atención.
Consciente de esta brecha en la literatura, Investigadores del Laboratorio de máquinas de texto de la Universidad de Massachusetts Lowell para el procesamiento del lenguaje natural han llevado a cabo recientemente un estudio que investiga la interpretación de la auto-atención, el componente más vital de los modelos BERT. El investigador principal y autor principal de este estudio fueron Olga Kovaleva y Anna Rumshisky, respectivamente. Su artículo prepublicado en arXiv y que se presentará en la conferencia EMNLP 2019, sugiere que una cantidad limitada de patrones de atención se repiten en diferentes subcomponentes de BERT, insinuando su sobre-parametrización.
"BERT es un modelo reciente que hizo un gran avance en la comunidad de PNL, hacerse cargo de las tablas de clasificación en múltiples tareas. Inspirado por esta tendencia reciente, teníamos curiosidad por investigar cómo y por qué funciona, ", dijo el equipo de investigadores a TechXplore por correo electrónico." Esperábamos encontrar una correlación entre la auto-atención, el principal mecanismo subyacente del BERT, y relaciones lingüísticamente interpretables dentro del texto de entrada dado ".
Las arquitecturas basadas en BERT tienen una estructura de capas, y cada una de sus capas consta de las llamadas "cabezas". Para que el modelo funcione, cada uno de estos jefes está capacitado para codificar un tipo específico de información, contribuyendo así al modelo general a su manera. En su estudio, los investigadores analizaron la información codificada por estos jefes individuales, centrándose tanto en su cantidad como en su calidad.
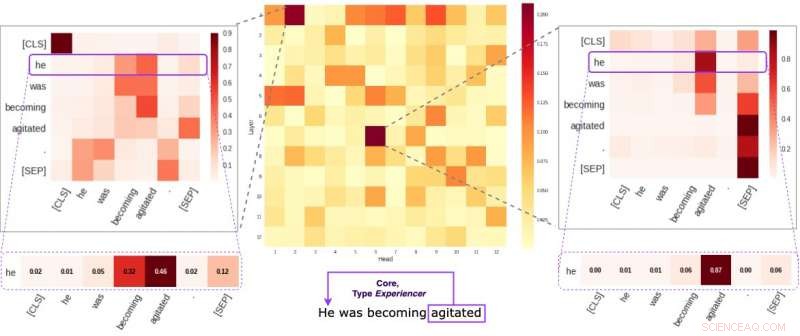
Cada celda en la figura del medio refleja cómo los jefes individuales prestan atención a los enlaces semánticos centrales dentro de una oración dada (en promedio). Identificamos dos cabezas específicas que tienden a codificar información semántica más que las demás. Las dos imágenes a los lados demuestran cómo estas dos cabezas asignan pesos a palabras individuales dentro de una oración aleatoria de nuestro conjunto de datos. Crédito:Kovaleva et al.
"Nuestra metodología se centró en examinar las cabezas individuales y los patrones de atención que producían, "explicaron los investigadores." Esencialmente, intentábamos responder a la pregunta:"Cuando BERT codifica una sola palabra de una oración, ¿presta atención a las otras palabras de una manera significativa para los humanos? "
Los investigadores llevaron a cabo una serie de experimentos utilizando modelos BERT básicos previamente entrenados y ajustados. Esto les permitió recopilar numerosas observaciones interesantes relacionadas con el mecanismo de auto-atención que se encuentra en el núcleo de las arquitecturas basadas en BERT. Por ejemplo, observaron que un conjunto limitado de patrones de atención a menudo se repite en diferentes cabezas, lo que sugiere que los modelos BERT están sobre parametrizados.
"Descubrimos que BERT tiende a estar sobre parametrizado, y hay mucha redundancia en la información que codifica, ", dijeron los investigadores. Esto significa que la huella computacional de entrenar un modelo tan grande no está bien justificada".
Otro hallazgo interesante recopilado por el equipo de investigadores de la Universidad de Massachusetts Lowell es que, dependiendo de la tarea abordada por un modelo BERT, apagar aleatoriamente algunos de sus cabezales puede conducir a una mejora, en lugar de un declive, en rendimiento. Además, los investigadores no identificaron ningún patrón lingüístico que sea de particular importancia para determinar el desempeño de BERT en las tareas posteriores.
"Hacer que el aprendizaje profundo sea interpretable es importante tanto para la investigación fundamental como para la aplicada, y seguiremos trabajando en esta dirección, ", dijeron los investigadores." Recientemente se han lanzado nuevos modelos basados en BERT, y planeamos ampliar nuestra metodología para investigarlos también ".
© 2019 Science X Network