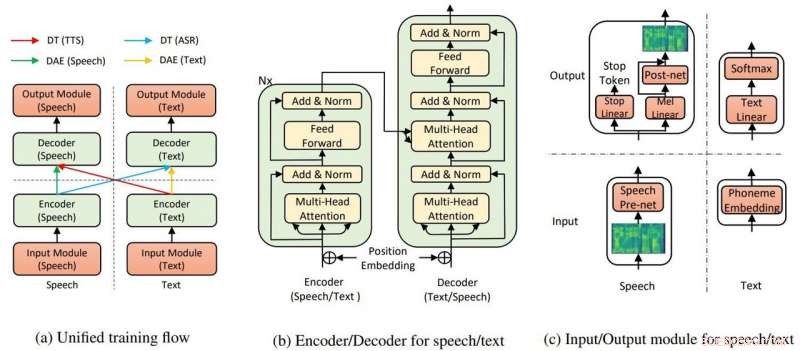
La estructura general del modelo para TTS y ASR. Crédito:Yi Ren, Xu Tan y col.
Microsoft Research Asia ha recibido aplausos por llevar texto a voz que requiere poca capacitación y muestra resultados "increíblemente" realistas.
Kyle Wiggers en VentureBeat dijo que los algoritmos de texto a voz no eran nuevos y que otros eran bastante capaces, pero todavía, el esfuerzo del equipo en Microsoft todavía tiene una ventaja.
Abdullah Matloob en Mundo de la información digital :"La conversión de texto a voz se está volviendo inteligente con el tiempo, pero el inconveniente es que aún se necesitará una cantidad excesiva de tiempo y recursos de capacitación para construir un producto que suene natural ".
Buscando una manera de hacer frente a la carga de tiempo y recursos de capacitación para crear resultados que suenen naturales, Microsoft Research e investigadores chinos descubrieron otra forma de convertir texto a voz.
Fabienne Lang en Ingenieria interesante :Su respuesta resulta ser una conversión de texto a voz con IA que utiliza 200 muestras de voz (solo 200) para crear un discurso con un sonido realista que coincida con las transcripciones. Lang dijo:"Esto significa aproximadamente 20 minutos".
Que el requisito fuera solo 200 clips de audio y las transcripciones correspondientes impresionó a Wiggers en VentureBeat . También señaló que los investigadores diseñaron un sistema de inteligencia artificial "que aprovecha el aprendizaje no supervisado, una rama del aprendizaje automático que obtiene conocimiento de desclasificado, y datos de prueba sin categorizar ".
Su artículo está en arXiv. "Texto a voz casi sin supervisión y reconocimiento automático de voz" es de Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu. Las afiliaciones de los autores son la Universidad de Zhejiang, Microsoft Research y Microsoft Search Technology Center (STC) Asia.
En su papel el equipo dijo que el TTS AI utiliza dos componentes clave, un transformador y un codificador automático de eliminación de ruido, para que todo funcione.
"A través de los transformadores, La inteligencia artificial de texto a voz de Microsoft pudo reconocer la voz o el texto como entrada o salida, "decía un artículo en Tenso de Rechelle Fuertes.
Tyler Lee en Ubergizmo proporcionó una definición de transformador:"Los transformadores ... son redes neuronales profundas diseñadas para emular las neuronas de nuestro cerebro ..."
MathWorks tenía una definición de codificador automático. "Un codificador automático es un tipo de red neuronal artificial que se utiliza para aprender datos eficientes (codificaciones) de forma no supervisada. El objetivo de un codificador automático es aprender una representación (codificación) de un conjunto de datos, eliminar el ruido de los codificadores automáticos es típicamente un tipo de codificadores automáticos entrenados para ignorar el 'ruido' en las muestras de entrada dañadas ".
¿Los resultados de su experimento demostraron que vale la pena perseguir su idea? "Nuestro método alcanza el 99,84% en términos de tasa inteligible a nivel de palabra y 2,68 MOS para TTS, y 11,7% PER para ASR [reconocimiento automático de voz] en el conjunto de datos LJSpeech, al aprovechar solo 200 datos de voz y texto emparejados (aproximadamente 20 minutos de audio), junto con datos de texto y voz adicionales no emparejados ".
Por qué es importante:este enfoque puede hacer que la conversión de texto a voz sea más accesible, dichos informes.
"Los investigadores trabajan continuamente para mejorar el sistema, y tenemos la esperanza de que en el futuro, se necesitará aún menos trabajo para generar un discurso realista, "dijo Lang.
El documento se presentará en la Conferencia Internacional sobre Aprendizaje Automático, en Long Beach, California, a finales de este año, y el equipo planea lanzar el código en las próximas semanas, dijo Wiggers.
Mientras tanto, los investigadores aún no se están alejando de su trabajo al presentar transformaciones con pocos datos emparejados.
"En este trabajo, hemos propuesto el método casi sin supervisión de texto a voz y reconocimiento automático de voz, que aprovecha solo unos pocos datos emparejados de voz y texto y datos adicionales no emparejados ... Para el trabajo futuro, avanzaremos hacia el límite del aprendizaje no supervisado aprovechando únicamente los datos de voz y texto no emparejados, con la ayuda de otros métodos de preentrenamiento ".
© 2019 Science X Network