Los investigadores consideran el problema de la navegación desde una posición inicial hasta una posición objetivo. Su enfoque (WayPtNav) consiste en un módulo de percepción basado en el aprendizaje y un módulo de planificación basado en modelos dinámicos. El módulo de percepción predice un waypoint basado en la observación actual de imágenes RGB en primera persona. Este punto de ruta es utilizado por el módulo de planificación basado en modelos para diseñar un controlador que regule sin problemas el sistema hasta este punto de ruta. Este proceso se repite para la siguiente imagen hasta que el robot alcanza la meta. Crédito:Bansal et al.
Investigadores de UC Berkeley y Facebook AI Research han desarrollado recientemente un nuevo enfoque para la navegación de robots en entornos desconocidos. Su enfoque presentado en un artículo publicado previamente en arXiv, combina técnicas de control basadas en modelos con la percepción basada en el aprendizaje.
El desarrollo de herramientas que permitan a los robots navegar por los entornos circundantes es un desafío clave y continuo en el campo de la robótica. En décadas recientes, Los investigadores han intentado abordar este problema de diversas formas.
La comunidad de investigación de control ha investigado principalmente la navegación de un agente (o sistema) conocido dentro de un entorno conocido. En estos casos, se dispone de un modelo de dinámica del agente y un mapa geométrico del entorno por el que estará navegando, por lo tanto, se pueden utilizar esquemas de control óptimo para obtener trayectorias suaves y sin colisiones para que el robot alcance la ubicación deseada.
Estos esquemas se utilizan normalmente para controlar una serie de sistemas físicos reales, como aviones o robots industriales. Sin embargo, estos enfoques son algo limitados, ya que requieren un conocimiento explícito del entorno por el que navegará un sistema. En la comunidad de investigación del aprendizaje, por otra parte, La navegación robótica generalmente se estudia para un agente desconocido que explora un entorno desconocido. Esto significa que un sistema adquiere políticas para mapear directamente las lecturas de los sensores incorporados para controlar los comandos de un extremo a otro.
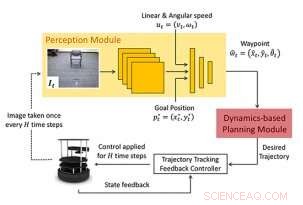
Marco propuesto:El nuevo enfoque de la navegación consiste en un módulo de percepción basado en el aprendizaje y un módulo de planificación basado en modelos dinámicos. El módulo de percepción consta de una CNN que emite un siguiente estado o punto de ruta deseado. Este punto de ruta lo utiliza el módulo de planificación basado en modelos para diseñar un controlador que regule sin problemas el sistema hasta el punto de ruta. Crédito:Bansal et al.
Estos enfoques pueden tener varias ventajas, ya que permiten que las políticas se aprendan sin ningún conocimiento del sistema y el entorno por el que se navegará. Sin embargo, Los estudios anteriores sugieren que estas técnicas no se generalizan bien entre diferentes agentes. Además, El aprendizaje de tales políticas a menudo requiere una gran cantidad de muestras de capacitación.
"En este papel, Estudiamos la navegación del robot en entornos estáticos bajo el supuesto de una medición perfecta del estado del robot. "Los investigadores escribieron en su artículo." Hacemos la observación crucial de que los problemas más interesantes involucran un sistema conocido en un entorno desconocido. Esta observación motiva el diseño de un enfoque factorizado que utiliza el aprendizaje para abordar entornos desconocidos y aprovecha el control óptimo utilizando dinámicas de sistema conocidas para producir una locomoción suave ".
El equipo de investigadores de UC Berkeley y Facebook entrenó un modelo basado en una red neuronal convolucional (CNN) en políticas de alto nivel, que utilizan observaciones de imágenes RGB actuales para producir una secuencia de estados intermedios, o 'puntos de referencia'. Estos puntos de referencia finalmente guían a un robot a su ubicación deseada siguiendo una ruta libre de colisiones, en entornos previamente desconocidos.
Su enfoque navegación basada en puntos de referencia (WayPtNav), esencialmente combina las técnicas de control basadas en modelos con la percepción basada en el aprendizaje. El módulo de percepción basado en el aprendizaje genera puntos de referencia, que guían al robot a su ubicación objetivo a través de una ruta libre de colisiones. El planificador basado en modelos, por otra parte, utiliza estos puntos de referencia para generar una trayectoria fluida y dinámicamente factible, que luego se ejecuta en el sistema usando control de retroalimentación.
Los investigadores evaluaron su enfoque en un banco de pruebas de hardware, llamado TurtleBot2. Sus pruebas obtuvieron resultados muy prometedores, con WayPtNav que permite la navegación en entornos desordenados y dinámicos, al mismo tiempo que supera en rendimiento a un enfoque de aprendizaje de principio a fin.
"Nuestros experimentos en entornos desordenados del mundo real simulados y en un vehículo terrestre real demuestran que el enfoque propuesto puede llegar a las ubicaciones de los objetivos de manera más confiable y eficiente en entornos novedosos en comparación con una alternativa basada puramente en el aprendizaje de un extremo a otro, "escribieron los investigadores.
El nuevo enfoque presentado por este equipo de investigadores podría mejorar la navegación del robot en entornos interiores novedosos. Los estudios futuros podrían intentar mejorar aún más WayPtNav, abordar algunas de sus limitaciones actuales.
"Nuestro enfoque propuesto asume una estimación perfecta del estado del robot y emplea una política puramente reactiva, ", explicaron los investigadores." Estas suposiciones y elecciones pueden no ser óptimas, especialmente para tareas de largo alcance. La incorporación de la memoria espacial o visual para abordar estas limitaciones sería una dirección futura fructífera ".
© 2019 Science X Network