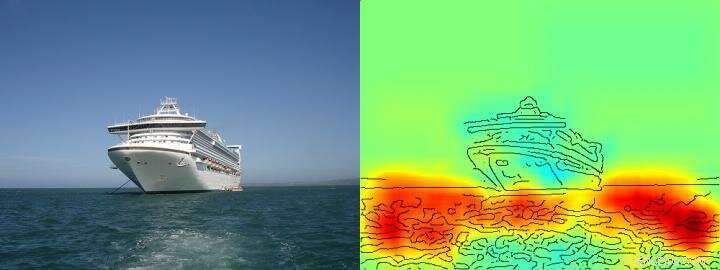
El mapa de calor muestra con bastante claridad que el algoritmo toma su decisión de barco / no barco sobre la base de píxeles que representan el agua y no sobre la base de píxeles que representan el barco. Crédito: Comunicaciones de la naturaleza , CC POR Lizenz
La inteligencia artificial (IA) y las arquitecturas de aprendizaje automático, como el aprendizaje profundo, se han convertido en parte integral de nuestra vida diaria:permiten asistentes de voz digitales o servicios de traducción. mejoran los diagnósticos médicos y son una parte indispensable de tecnologías futuras como la conducción autónoma. Basado en una cantidad cada vez mayor de datos y en arquitecturas informáticas novedosas y potentes, los algoritmos de aprendizaje aparentemente se acercan a las capacidades humanas, a veces incluso superándolos. Hasta aquí, sin embargo, A menudo, los usuarios desconocen cómo los sistemas de inteligencia artificial llegan a sus conclusiones. Por lo tanto, A menudo, puede no quedar claro si el comportamiento de toma de decisiones de la IA es realmente inteligente o si los procedimientos tienen un éxito medio.
Investigadores de TU Berlín, El Instituto Fraunhofer Heinrich Hertz HHI y la Universidad de Tecnología y Diseño de Singapur (SUTD) han abordado esta cuestión y han proporcionado un vistazo al espectro diverso de "inteligencia" observado en los sistemas de IA actuales. analizando específicamente estos sistemas de IA con una novedosa tecnología que permite el análisis y la cuantificación automatizados.
El requisito previo más importante para esta nueva tecnología es un método desarrollado anteriormente por TU Berlin y Fraunhofer HHI, el llamado algoritmo de Propagación de relevancia por capas (LRP) que permite visualizar según qué variables de entrada los sistemas de IA toman sus decisiones. Ampliación de LRP, El novedoso análisis de relevancia espectral (SpRAy) puede identificar y cuantificar un amplio espectro de conductas de toma de decisiones aprendidas. De esta manera, ahora es posible detectar tomas de decisiones indeseables incluso en conjuntos de datos muy grandes.
Esta llamada 'IA explicable' ha sido uno de los pasos más importantes hacia una aplicación práctica de la IA, según el Dr. Klaus-Robert Müller, profesor de aprendizaje automático en TU Berlín. "Específicamente en diagnóstico médico o en sistemas críticos para la seguridad, no se deberían utilizar sistemas de IA que empleen estrategias de resolución de problemas inestables o incluso engañosas ".
Mediante el uso de sus algoritmos recientemente desarrollados, Los investigadores finalmente pueden poner a prueba cualquier sistema de IA existente y también obtener información cuantitativa sobre ellos:un espectro completo que comienza con un comportamiento ingenuo de resolución de problemas, Se observa desde estrategias de engaño hasta soluciones estratégicas muy elaboradas "inteligentes".
Dr. Wojciech Samek, El líder del grupo en Fraunhofer HHI dijo:"Nos sorprendió mucho la amplia gama de estrategias de resolución de problemas aprendidas. Incluso los sistemas modernos de IA no siempre han encontrado una solución que parezca significativa desde una perspectiva humana, pero a veces usaba las llamadas Estrategias Inteligentes de Hans ".
Clever Hans era un caballo que supuestamente podía contar y fue considerado una sensación científica durante la década de 1900. Como se descubrió más tarde, Hans no dominaba las matemáticas, pero en aproximadamente el 90 por ciento de los casos, pudo obtener la respuesta correcta a partir de la reacción del interrogador.
El equipo de Klaus-Robert Müller y Wojciech Samek también descubrió estrategias similares de "Hans inteligente" en varios sistemas de inteligencia artificial. Por ejemplo, un sistema de inteligencia artificial que ganó varios concursos internacionales de clasificación de imágenes hace unos años siguió una estrategia que puede considerarse ingenua desde el punto de vista humano. Clasificó las imágenes principalmente sobre la base del contexto. Las imágenes se asignaron a la categoría "barco" cuando había mucha agua en la imagen. Otras imágenes se clasificaron como "tren" si había rieles. A otras imágenes se les asignó la categoría correcta por su marca de agua de derechos de autor. La verdadera tarea a saber, detectar los conceptos de barcos o trenes, por lo tanto, este sistema de IA no lo resolvió, incluso si clasificaba correctamente la mayoría de las imágenes.
Los investigadores también pudieron encontrar este tipo de estrategias de resolución de problemas defectuosas en algunos de los algoritmos de IA de última generación, las llamadas redes neuronales profundas, algoritmos que se habían considerado inmunes a tales lapsos. Estas redes basaron sus decisiones de clasificación en parte en artefactos que se crearon durante la preparación de las imágenes y no tienen nada que ver con el contenido de la imagen real.
"Estos sistemas de IA no son útiles en la práctica. Su uso en diagnósticos médicos o en áreas críticas para la seguridad implicaría incluso enormes peligros, ", dijo Klaus-Robert Müller." Es bastante concebible que alrededor de la mitad de los sistemas de inteligencia artificial que se utilizan actualmente, implícita o explícitamente, se basan en estas estrategias de Clever Hans. Es hora de comprobarlo sistemáticamente para que se puedan desarrollar sistemas de inteligencia artificial seguros ".
Con su nueva tecnología, los investigadores también identificaron sistemas de inteligencia artificial que han aprendido inesperadamente estrategias "inteligentes". Los ejemplos incluyen sistemas que han aprendido a jugar a los juegos de Atari Breakout y Pinball. "Aquí, la IA entendió claramente el concepto del juego, y encontró una forma inteligente de recolectar muchos puntos de una manera específica y de bajo riesgo. El sistema a veces incluso interviene de formas que un jugador real no haría, "dijo Wojciech Samek.
"Más allá de comprender las estrategias de IA, Nuestro trabajo establece la usabilidad de la IA explicable para el diseño de conjuntos de datos iterativos, es decir, para eliminar artefactos en un conjunto de datos que harían que una IA aprenda estrategias defectuosas, además de ayudar a decidir qué ejemplos sin etiquetar deben anotarse y agregarse para que se puedan reducir las fallas de un sistema de inteligencia artificial, ", dijo el profesor asistente del SUTD, Alexander Binder.
"Nuestra tecnología automatizada es de código abierto y está disponible para todos los científicos. Vemos nuestro trabajo como un primer paso importante para hacer que los sistemas de IA sean más robustos, explicable y seguro en el futuro, y habrá más que seguir. Este es un requisito previo esencial para el uso general de la IA, "dijo Klaus-Robert Müller.














