Ilustración de algoritmo. Crédito:Agha-mohammadi et al.
Investigadores del Laboratorio de Propulsión a Chorro de la NASA (JPL), Universidad Texas A &M, y la Universidad Carnegie Mellon llevaron a cabo recientemente un proyecto de investigación destinado a habilitar capacidades de localización y planificación simultáneas (SLAP) en robots autónomos. Su papel publicado en Transacciones IEEE sobre robótica , presenta un esquema de replanificación dinámico en el espacio de creencias, que podría ser particularmente útil para robots que operan en condiciones de incertidumbre, como en entornos cambiantes.
"Los robots que operan en el mundo real deben lidiar con la incertidumbre, "Sung Kyun Kim, uno de los investigadores que llevó a cabo el estudio le dijo a TechXplore. "Por ejemplo, un rover de Marte es navegar a ubicaciones de objetivos científicos, pero también debe evitar colisiones con obstáculos. Por lo tanto, tanto la localización precisa como la planificación de rutas rentable son capacidades esenciales ".
SLAP es una habilidad clave para robots autónomos que operan bajo incertidumbre, permitiéndoles navegar eficazmente por los espacios, evitar obstáculos, y planificar su ruta a las ubicaciones de destino. El proceso secuencial de toma de decisiones de un robot bajo incertidumbre se puede formular como un POMDP (proceso de decisión de Markov parcialmente observable), que debe resolverse continuamente en línea. Sin embargo, garantizar que los robots resuelvan los POMDP de forma eficaz y precisa puede ser un desafío considerable.
"Se nos ocurrieron dos ideas principales para resolver problemas SLAP, "Explicó Kim." Uno es utilizar controladores de retroalimentación para hacer que un estado de creencia sea accesible. Esto puede romper efectivamente la 'maldición de la historia, 'lo que nos ayuda a resolver problemas más grandes. El otro es volver a planificar dinámicamente y mejorar la decisión en tiempo de ejecución, mejorando la calidad y robustez de la solución. La replanificación dinámica es especialmente beneficiosa cuando hay errores de modelado del sistema, cambios dinámicos del entorno, o fallas intermitentes del sensor / actuador ".

Ejemplo del rover de Marte. Crédito:NASA / JPL-Caltech.
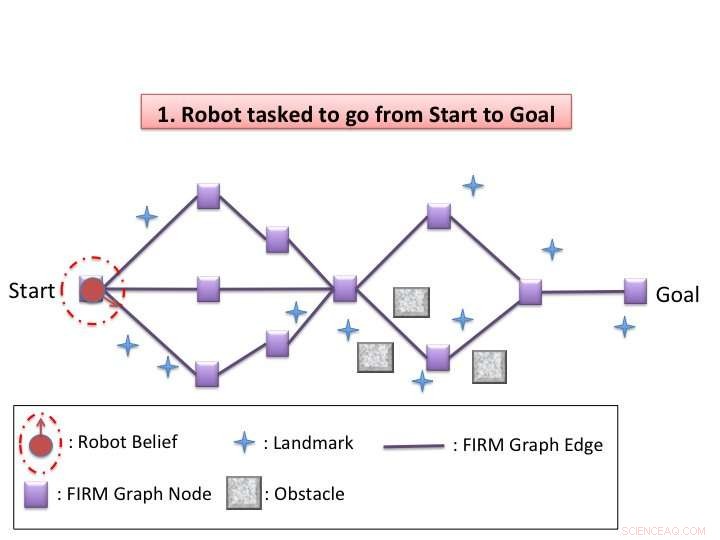
Kim y sus colegas idearon un esquema de replanificación dinámico en el espacio de creencias que permite a los robots navegar de manera efectiva por el espacio que los rodea en situaciones de incertidumbre. como en entornos cambiantes o cuando se presentan obstáculos inesperados. Su algoritmo tiene dos fases, fuera de línea y en línea.
"En la fase sin conexión, nuestro algoritmo construye un gráfico disperso en el espacio de creencias con un controlador de retroalimentación para cada nodo y luego resuelve la política global burda (decidir qué acción tomar en el estado de creencia actual) en el gráfico, ", Dijo Kim." En la fase en línea, La replanificación dinámica se lleva a cabo cada vez que se actualiza el estado de creencias. El algoritmo evalúa localmente cada acción de moverse a un nodo cercano en el gráfico y selecciona el que tiene el costo mínimo. Después de ejecutar la acción seleccionada y actualizar la creencia actual, repite el proceso de replanificación ".
El esquema ideado por Kim y sus colegas explota el comportamiento de los controladores de retroalimentación en el espacio de creencias. En otras palabras, los controladores de retroalimentación actúan como un embudo en el espacio de creencias, con un estado de creencia cercano que potencialmente converge con el estado de creencia del objetivo de control. Esto aborda de manera efectiva un problema clave en la resolución de POMPD:la complejidad exponencial en el horizonte de planificación.
De hecho, una vez que la creencia actual del algoritmo converge con una creencia conocida, no hay necesidad de considerar acciones y observaciones que conduzcan a la creencia actual. Esto, en última instancia, conduce a una mejor escalabilidad, permitiendo que los robots resuelvan problemas de navegación más complejos.
Ejemplo del rover de Marte. Crédito:NASA / JPL-Caltech / MSSS.
"Durante la replanificación dinámica, el método propuesto arranca la optimización local con la política global (aproximada), ", Dijo Kim." Esto significa que puede tomar una decisión no miope, a diferencia de otros planificadores en línea con un horizonte en retroceso finito. En breve, este método puede adaptarse a cambios dinámicos en el entorno y operar de manera robusta a pesar de una perturbación o errores no modelados, mientras se hacen planes rentables en el sentido global ".
Al eliminar pasos de estabilización innecesarios, el método ideado por Kim y sus colegas superó la hoja de ruta de información basada en comentarios (FIRM), una técnica de vanguardia para resolver POMDP. En el futuro, Este esquema de replanificación dinámico en el espacio de creencias podría permitir mejores capacidades SLAP en robots que operan bajo diversos grados de incertidumbre.
"Ahora planeamos aplicar nuestro método a problemas del mundo real, "Dijo Kim." Una posible aplicación es un prototipo de navegación y coordinación de helicópteros-rover en Marte para la exploración planetaria, un proyecto dirigido por el Dr. Ali-akbar Agha-mohammadi en JPL. Un helicóptero sobrevolando el terreno podría proporcionar un mapa aproximado para poder obtener una política global aproximada en la fase fuera de línea. Después, un rover se replanificaría dinámicamente en la fase en línea, para realizar misiones de navegación seguras y rentables ".
© 2018 Tech Xplore