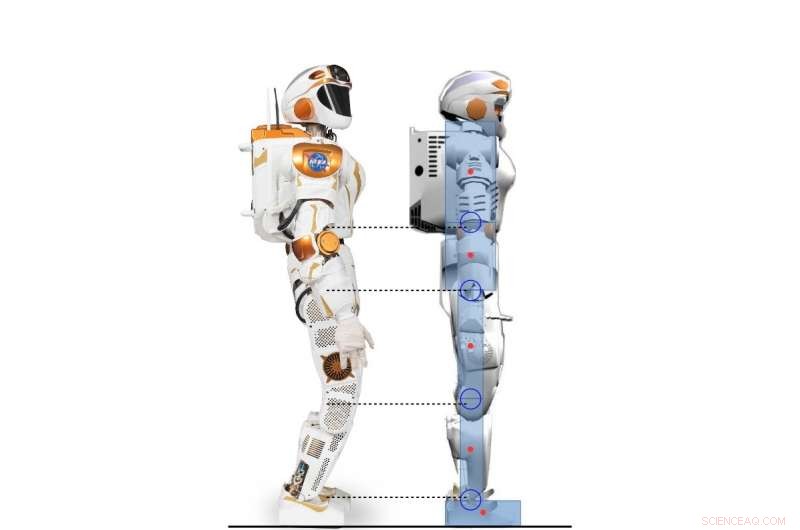
Vista lateral del robot Valkyrie y el personaje humanoide 2D modelado según el robot Valkyrie. Crédito:Yang, Komura y Li
Investigadores de la Universidad de Edimburgo han desarrollado un marco jerárquico basado en el aprendizaje por refuerzo profundo (RL) que puede adquirir una variedad de estrategias para el control del equilibrio humanoide. Su marco, descrito en un artículo publicado previamente en arXiv y presentado en la Conferencia Internacional de Robótica Humanoide de 2017, podría realizar comportamientos de equilibrio mucho más parecidos a los humanos que los controladores convencionales.
Al estar de pie o caminar, Los seres humanos utilizan de forma innata y eficaz una serie de técnicas de control sub-actuadas que les ayudan a mantener el equilibrio. Estos incluyen inclinación del dedo del pie y giro del talón, que crean una mejor distancia entre los pies y el suelo. Replicar comportamientos similares en robots humanoides podría mejorar en gran medida sus capacidades motoras y de movimiento.
"Nuestra investigación se centra en el uso de RL profundo para resolver la locomoción dinámica de robots humanoides, "Dr. Zhibin Li, profesor de robótica y control en la Universidad de Edimburgo, quien realizó el estudio, dijo a TechXplore. "En el pasado, La locomoción se realizó principalmente utilizando enfoques analíticos convencionales:basados en modelos, que son limitados porque requieren esfuerzo y conocimiento humanos, y exigen una alta potencia informática para funcionar en línea ".
Requiere menos esfuerzo humano y ajuste manual, Las técnicas de aprendizaje automático podrían conducir al desarrollo de controladores más eficaces y específicos que los enfoques de ingeniería tradicionales. Otra ventaja de utilizar RL es que el cálculo de estas herramientas también se puede subcontratar fuera de línea, resultando en un rendimiento en línea más rápido para sistemas de control de alta dimensión, como robots humanoides.

Un robot Valkyrie simulado en pose de inclinación de los dedos del pie / talón. Crédito:Yang, Komura y Li
"Dados los algoritmos RL profundos cada vez más potentes, un número cada vez mayor de estudios de investigación ha comenzado a utilizar el RL profundo para resolver tareas de control, dado que el progreso reciente en algoritmos de RL profundos diseñados para el dominio de acción continua ha brindado la posibilidad de aplicar tareas de control continuo de aprendizaje por refuerzo que involucran dinámicas complicadas, "El Dr. Li explicó." El objetivo principal de nuestra investigación fue explorar las posibilidades de utilizar el aprendizaje por refuerzo profundo para adquirir políticas de control versátiles comparables o mejores que los enfoques analíticos utilizando menos esfuerzo humano ".
El marco desarrollado por el Dr. Li, en colaboración con el Dr. Taku Komura y Ph.D. estudiante Chuanyu Yang utiliza RL profundo para lograr políticas de control de alto nivel. Recibir constantemente información sobre el estado del robot, estas estrategias permiten los ángulos de articulación deseados a una frecuencia más baja.
"En el nivel bajo, Los controladores proporcionales y derivados (PD) se utilizan a una frecuencia de control mucho más alta para garantizar los movimientos articulares estables, "El estudiante de doctorado Chuanyu dijo." Las entradas para el controlador de DP de bajo nivel son los ángulos de articulación deseados producidos por la red neuronal de alto nivel, y las salidas son los pares deseados para motores conjuntos ".
Los investigadores probaron el rendimiento de su algoritmo y lograron resultados muy prometedores. Descubrieron que transferir el conocimiento humano de los métodos de ingeniería de control al diseño de recompensas para los algoritmos RL permitió estrategias de control del equilibrio que se parecían a las utilizadas por los humanos. Es más, a medida que los algoritmos de RL mejoran mediante un proceso de prueba y error, adaptarse automáticamente a nuevas situaciones, su marco requiere pocos ajustes manuales u otras intervenciones por parte de ingenieros humanos.
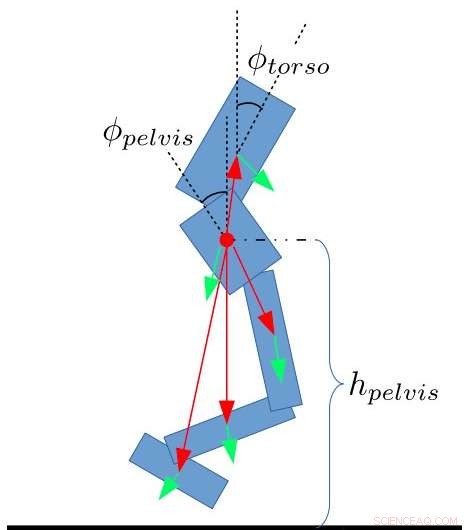
Características estatales para bípedos. Yang, Komura y Li
"Nuestro estudio muestra que el aprendizaje por refuerzo profundo puede ser una herramienta poderosa para producir resultados de equilibrio comparables a los de un controlador diseñado por humanos con menos esfuerzo de ajuste manual y menos tiempo, "El Dr. Li dijo." El algoritmo de aprendizaje de refuerzo profundo que desarrollamos es incluso capaz de aprender comportamientos similares a los humanos emergentes, como inclinarse alrededor de los dedos de los pies o los talones, que la mayoría de los métodos de ingeniería no pueden realizar ".
El Dr. Li y sus colegas ahora están trabajando en una extensión de su estudio que aplica RL a un robot Valkyrie de cuerpo completo en una simulación 3-D. En este nuevo esfuerzo de investigación, fueron capaces de generalizar estrategias de equilibrio parecidas a las humanas para caminar y otras tareas de locomoción.
"Finalmente, nos gustaría aplicar este marco jerárquico de combinar el aprendizaje automático y el control de robots a robots humanoides reales, así como a otras plataformas robóticas, "Dijo el Dr. Li.
© 2018 Tech Xplore