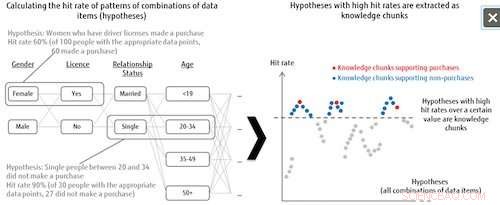
Figura 1:Listado de hipótesis y extracción de fragmentos de conocimiento. Crédito:Fujitsu
Fujitsu Laboratories Ltd. anunció hoy el desarrollo de "Wide Learning, "una tecnología de aprendizaje automático capaz de emitir juicios precisos incluso cuando los operadores no pueden obtener el volumen de datos necesarios para el entrenamiento. La IA ahora se usa a menudo para aprovechar los datos en una variedad de campos, pero la precisión de la IA puede verse afectada en los casos en que el volumen de datos a analizar sea pequeño o desequilibrado. La tecnología Wide Learning de Fujitsu permite llegar a juicios con mayor precisión de lo que era posible anteriormente. y el aprendizaje se logra de manera uniforme, no importa qué hipótesis se examine, incluso cuando los datos están desequilibrados. Lo consigue extrayendo primero hipótesis con un alto grado de importancia, habiendo hecho un gran conjunto de hipótesis formadas por todas las combinaciones de elementos de datos, y luego controlando el grado de impacto de cada hipótesis respectiva en función de las relaciones superpuestas de las hipótesis. Es más, porque las hipótesis se registran como expresiones lógicas, los humanos también pueden comprender el razonamiento detrás de un juicio. La nueva tecnología Wide Learning de Fujitsu permite el uso de IA incluso en áreas como la salud y el marketing, donde los datos necesarios para emitir juicios son escasos, apoyando las operaciones y promoviendo la automatización de los procesos de trabajo utilizando IA.
En años recientes, La tecnología de IA ha comenzado a utilizarse en una variedad de campos, incluida la asistencia sanitaria, márketing, y finanzas. Están aumentando las expectativas para el uso de la toma de decisiones de inteligencia artificial en apoyo de las operaciones y la automatización de tareas en estas áreas. Un desafío que queda por realizar para aprovechar el potencial de estas tecnologías, sin embargo, es que los datos pueden estar desequilibrados. Específicamente, Dependiendo de la industria, puede ser difícil obtener datos suficientes para entrenar a la IA sobre los objetivos sobre los que debe emitir juicios. Esta, en efecto, deja muchas de estas tecnologías incapaces de producir resultados con suficiente precisión para un uso práctico. Es más, Una de las principales razones por las que la implementación de la IA carece de progreso es que incluso cuando una IA proporciona un rendimiento de clasificación o reconocimiento suficientemente preciso, los expertos e incluso los propios desarrolladores a menudo no pueden explicar por qué la IA produjo una determinada respuesta, y si no pueden cumplir con su responsabilidad de explicar los resultados al frente de la industria, entonces no se puede implementar la IA.
Las tecnologías de inteligencia artificial basadas en el aprendizaje profundo hacen juicios de gran precisión de manera convencional al recibir capacitación en grandes volúmenes de datos, incluyendo amplios datos objetivo para ser juzgados. En escenarios del mundo real, sin embargo, hay muchos casos en los que los datos son insuficientes, con muy pocos datos de destino. En estos casos, cuando se enfrenta a datos desconocidos, Se vuelve difícil para la tecnología de inteligencia artificial emitir juicios muy precisos. Es más, el modelo de aprendizaje automático para la IA existente basado en el aprendizaje profundo es un modelo de caja negra que no puede explicar las razones detrás de los juicios que hace la IA, creando un problema con la transparencia. Como tal, En el futuro, será necesario desarrollar una nueva tecnología de inteligencia artificial que realice juicios altamente precisos a partir de datos desequilibrados. y que además sea transparente para resolver diversos problemas de la sociedad.
Teniendo en cuenta estos desafíos, Fujitsu Laboratories ha desarrollado ahora Wide Learning, una tecnología de aprendizaje automático capaz de emitir juicios muy precisos incluso en los casos en los que los datos están desequilibrados. Las características de la tecnología Wide Learning incluyen los dos puntos siguientes.
1. Crea combinaciones de elementos de datos para extraer grandes volúmenes de hipótesis
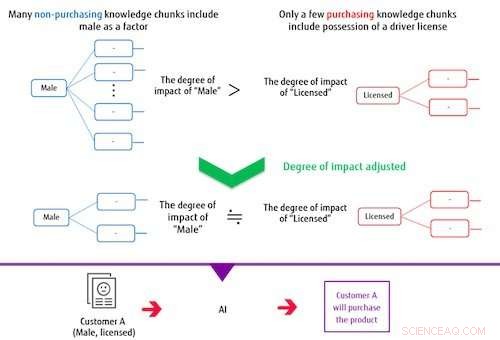
Figura 2:Al hacer un modelo de clasificación, los trozos de conocimiento impactan el ajuste. Crédito:Fujitsu
Esta tecnología trata todos los patrones de combinación de elementos de datos como hipótesis, y luego determina el grado de importancia de cada hipótesis según la tasa de aciertos de la categoría de etiqueta. Por ejemplo, al analizar las tendencias sobre quién compra ciertos productos, el sistema combina todo tipo de patrones de los elementos de datos para aquellos que hicieron o no compraron (la etiqueta de categoría), como mujeres solteras entre 20 y 34 años que tienen licencias de conducir, y luego analiza cuántos resultados obtiene en los datos de quienes realmente hicieron compras cuando estos patrones de combinación se toman como hipótesis. Las hipótesis que logran una tasa de acierto por encima de cierto nivel se definen como hipótesis importantes, llamados "trozos de conocimiento". Esto significa que incluso cuando los datos de destino son insuficientes, el sistema puede extraer todas las hipótesis que valga la pena analizar, lo que también puede contribuir al descubrimiento de explicaciones previamente no consideradas.
2. Ajusta el grado de impacto de los fragmentos de conocimiento para construir un modelo de clasificación preciso.
El sistema crea un modelo de clasificación basado en múltiples fragmentos de conocimiento extraídos y en la etiqueta de destino. En este proceso, si los elementos que componen un fragmento de conocimiento se superponen con frecuencia con los elementos que componen otros fragmentos de conocimiento, el sistema controla su grado de impacto para reducir el peso de su influencia en el modelo de clasificación. De este modo, el sistema puede entrenar un modelo capaz de clasificaciones precisas incluso cuando la etiqueta de destino o los datos marcados como correctos están desequilibrados. Por ejemplo, en un caso en el que los hombres que no realizaron una compra constituyen la gran mayoría del conjunto de datos de compra de un artículo, si la IA está entrenada sin controlar el grado de impacto, luego, la parte de conocimiento que incluye si una persona tiene o no una licencia, independiente del género, no tendrá mucha influencia en la clasificación. Con este método recientemente desarrollado, el grado de impacto de los fragmentos de conocimiento, incluido el hombre como factor, es limitado debido a la superposición de este ítem, mientras que el impacto de la menor cantidad de fragmentos de conocimiento que incluyen si una persona tiene una licencia se vuelve relativamente mayor en la capacitación, construir un modelo que pueda categorizar correctamente tanto a los hombres como a la posesión de una licencia.
Fujitsu Laboratories realizó una prueba de esta tecnología, aplicándolo a los datos en áreas como el marketing digital y la salud. En una prueba que utilizó datos de referencia en las áreas de marketing y atención médica del Repositorio de aprendizaje automático de UC Irvine, esta tecnología mejoró la precisión en aproximadamente un 10-20% en comparación con el aprendizaje profundo. Redujo con éxito la probabilidad de que el sistema pasara por alto a los clientes que probablemente se suscriban a un servicio oa los pacientes con una afección en aproximadamente un 20-50%. En los datos de marketing, de los aproximadamente 5, 000 entradas de datos de clientes utilizadas en la prueba, solo alrededor de 230 fueron para clientes compradores, haciendo un conjunto desequilibrado. Esta tecnología redujo el número de clientes potenciales excluidos de las promociones de ventas de 120, el resultado del análisis de aprendizaje profundo, a 74. Además, dado que los fragmentos de conocimiento que forman la base de esta tecnología tienen un formato de expresión lógica, la capacidad de explicar el razonamiento detrás de un juicio también es útil para implementar esta tecnología en la sociedad. Incluso cuando se determina que las correcciones a un modelo son necesarias, basado en resultados de nuevos datos, es posible hacer revisiones más apropiadas, porque los usuarios pueden comprender las razones de los resultados.
Fujitsu Laboratories continuará aplicando esta tecnología a tareas que exigen el razonamiento detrás de los juicios de IA, como en transacciones financieras y diagnósticos médicos, y a tareas que manejan fenómenos de baja frecuencia, como fraudes y averías de equipos, con el objetivo de comercializarlo como una nueva tecnología de aprendizaje automático que respalde Fujitsu Human Centric AI Zinrai de Fujitsu Limited en el año fiscal 2019. Fujitsu Laboratories también hará un uso efectivo de la capacidad característica de esta tecnología para la explicación, Continuar la investigación y el desarrollo en temas tales como un mejor apoyo para emitir juicios y decisiones en las tareas a las que se aplica. y en el diseño general del sistema, incluida la colaboración con humanos.














